Anda mungkin pernah mendengar tentang istilah "otak terbelah". Apa itu? Bagaimana pengaruhnya terhadap cluster Anda? Dalam posting blog ini kita akan membahas apa sebenarnya itu, bahaya apa yang mungkin ditimbulkannya terhadap database Anda, bagaimana kami dapat mencegahnya, dan jika semuanya tidak beres, bagaimana memulihkannya.
Lama berlalu adalah hari-hari contoh tunggal, saat ini hampir semua database berjalan dalam kelompok atau cluster replikasi. Ini bagus untuk ketersediaan dan skalabilitas tinggi, tetapi database terdistribusi memperkenalkan bahaya dan batasan baru. Satu kasus yang bisa mematikan adalah perpecahan jaringan. Bayangkan sekelompok beberapa node yang, karena masalah jaringan, terbelah menjadi dua bagian. Untuk alasan yang jelas (konsistensi data), kedua bagian tidak boleh menangani lalu lintas pada saat yang sama karena keduanya terisolasi satu sama lain dan data tidak dapat ditransfer di antara keduanya. Ini juga salah dari sudut pandang aplikasi - bahkan jika, pada akhirnya, akan ada cara untuk menyinkronkan data (walaupun rekonsiliasi 2 kumpulan data tidak sepele). Untuk sementara, bagian dari aplikasi tidak akan menyadari perubahan yang dibuat oleh host aplikasi lain, yang mengakses bagian lain dari cluster database. Hal ini dapat menyebabkan masalah serius.
Kondisi di mana cluster telah dibagi menjadi dua atau lebih bagian yang bersedia menerima tulisan disebut “otak terbelah”.
Masalah terbesar dengan otak terbelah adalah penyimpangan data, karena penulisan terjadi di kedua bagian cluster. Tak satu pun dari rasa MySQL menyediakan cara otomatis untuk menggabungkan kumpulan data yang telah menyimpang. Anda tidak akan menemukan fitur seperti itu di replikasi MySQL, Replikasi Grup atau Galera. Setelah data menyimpang, satu-satunya pilihan adalah menggunakan salah satu bagian dari cluster sebagai sumber kebenaran dan membuang perubahan yang dieksekusi pada bagian lain - kecuali jika kita dapat mengikuti beberapa proses manual untuk menggabungkan data.
Inilah sebabnya mengapa kita akan mulai dengan bagaimana mencegah terjadinya split brain. Ini jauh lebih mudah daripada harus memperbaiki perbedaan data apa pun.
Cara Mencegah Otak Terbelah
Solusi yang tepat tergantung pada jenis database dan pengaturan lingkungan. Kita akan melihat beberapa kasus yang paling umum untuk Galera Cluster dan Replikasi MySQL.
Kluster Galera
Galera memiliki "pemutus sirkuit" bawaan untuk menangani otak terbelah:ia mengandalkan mekanisme kuorum. Jika mayoritas (50% + 1) node tersedia di cluster, Galera akan beroperasi secara normal. Jika tidak ada mayoritas, Galera akan berhenti melayani lalu lintas dan beralih ke apa yang disebut status "non-Utama". Ini cukup banyak yang Anda butuhkan untuk menghadapi situasi otak terbelah saat menggunakan Galera. Tentu, ada metode manual untuk memaksa Galera ke status "Utama" meskipun tidak ada mayoritas. Masalahnya, kecuali Anda melakukannya, Anda seharusnya aman.
Cara penghitungan kuorum memiliki dampak penting - pada tingkat pusat data tunggal, Anda ingin memiliki jumlah node yang ganjil. Tiga node memberi Anda toleransi untuk kegagalan satu node (2 node cocok dengan persyaratan lebih dari 50% node dalam cluster yang tersedia). Lima node akan memberi Anda toleransi untuk kegagalan dua node (5 - 2 =3 yang lebih dari 50% dari 5 node). Di sisi lain, menggunakan empat node tidak akan meningkatkan toleransi Anda terhadap tiga cluster node. Itu masih akan menangani hanya kegagalan satu node (4 - 1 =3, lebih dari 50% dari 4) sementara kegagalan dua node akan membuat cluster tidak dapat digunakan (4 - 2 =2, hanya 50%, tidak lebih).
Saat menerapkan kluster Galera dalam satu pusat data, harap diingat bahwa, idealnya, Anda ingin mendistribusikan node di beberapa zona ketersediaan (sumber daya terpisah, jaringan, dll.) - selama node tersebut memang ada di pusat data Anda, yaitu . Pengaturan sederhana mungkin terlihat seperti di bawah ini:
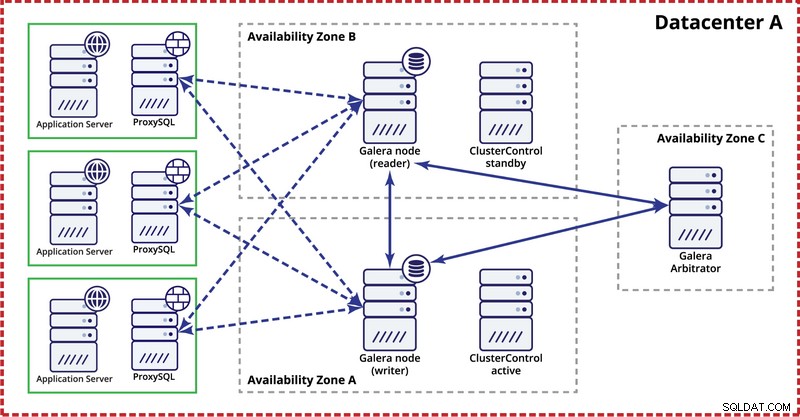
Pada tingkat multi-pusat data, pertimbangan tersebut juga berlaku. Jika Anda ingin klaster Galera menangani kegagalan pusat data secara otomatis, Anda harus menggunakan pusat data dalam jumlah ganjil. Untuk mengurangi biaya, Anda dapat menggunakan arbiter Galera di salah satu dari mereka alih-alih node database. Arbiter Galera (garbd) adalah proses yang mengambil bagian dalam perhitungan kuorum tetapi tidak memuat data apa pun. Hal ini memungkinkan untuk menggunakannya bahkan pada kasus yang sangat kecil karena tidak intensif sumber daya - meskipun konektivitas jaringan harus baik karena 'melihat' semua lalu lintas replikasi. Contoh setup mungkin terlihat seperti pada diagram di bawah ini:
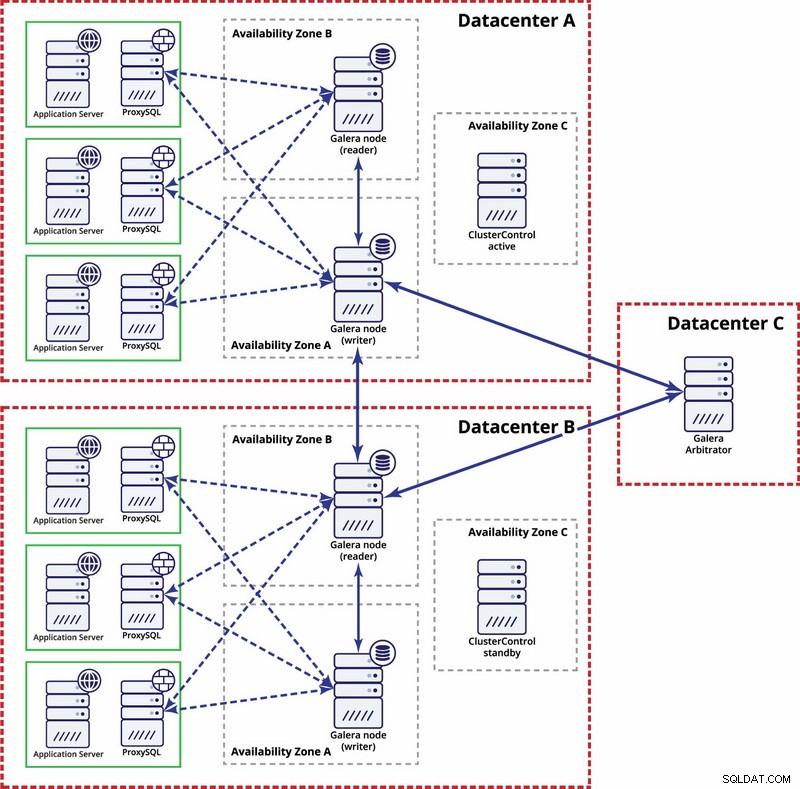
Replikasi MySQL
Dengan replikasi MySQL, masalah terbesar adalah tidak ada mekanisme kuorum bawaan, seperti di cluster Galera. Oleh karena itu, diperlukan lebih banyak langkah untuk memastikan bahwa penyiapan Anda tidak akan terpengaruh oleh otak yang terbelah.
Salah satu metodenya adalah menghindari failover otomatis lintas pusat data. Anda dapat mengonfigurasi solusi failover Anda (bisa melalui ClusterControl, atau MHA atau Orchestrator) ke failover hanya dalam satu pusat data. Jika terjadi pemadaman pusat data penuh, admin akan memutuskan bagaimana cara melakukan failover dan bagaimana memastikan bahwa server di pusat data yang gagal tidak akan digunakan.
Ada opsi untuk membuatnya lebih otomatis. Anda dapat menggunakan Consul untuk menyimpan data tentang node dalam pengaturan replikasi, dan yang salah satunya adalah master. Kemudian terserah admin (atau melalui beberapa skrip) untuk memperbarui entri ini dan memindahkan penulisan ke pusat data kedua. Anda bisa mendapatkan keuntungan dari pengaturan Orchestrator/Raft di mana node Orchestrator dapat didistribusikan di beberapa pusat data dan mendeteksi otak terbelah. Berdasarkan ini, Anda dapat mengambil tindakan yang berbeda seperti, seperti yang kami sebutkan sebelumnya, memperbarui entri di Konsul kami atau dll. Intinya adalah bahwa ini adalah lingkungan yang jauh lebih kompleks untuk diatur dan diotomatisasi daripada cluster Galera. Di bawah ini Anda dapat menemukan contoh pengaturan multi-pusat data untuk replikasi MySQL.
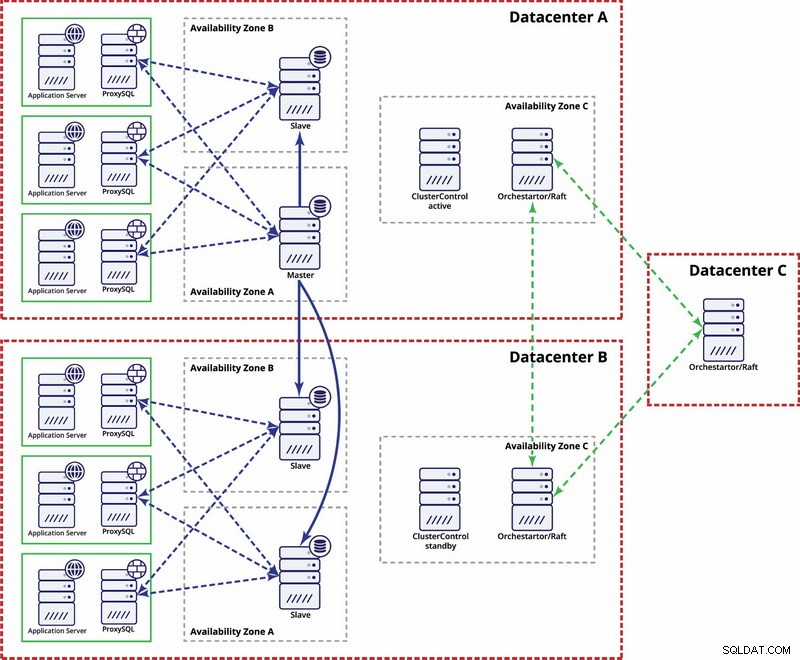
Harap diingat bahwa Anda masih harus membuat skrip untuk membuatnya berfungsi, yaitu memantau node Orchestrator untuk otak yang terbelah dan mengambil tindakan yang diperlukan untuk mengimplementasikan STONITH dan memastikan bahwa master di pusat data A tidak akan digunakan setelah jaringan bertemu dan konektivitas akan dipulihkan.
Terjadinya Otak Terbelah - Apa yang Harus Dilakukan Selanjutnya?
Skenario kasus terburuk terjadi dan kami memiliki penyimpangan data. Kami akan mencoba memberi Anda beberapa petunjuk apa yang bisa dilakukan di sini. Sayangnya, langkah-langkah yang tepat akan sangat bergantung pada desain skema Anda sehingga tidak mungkin untuk menulis panduan cara yang tepat.
Yang harus Anda ingat adalah bahwa tujuan akhirnya adalah menyalin data dari satu master ke master lainnya dan membuat ulang semua hubungan antar tabel.
Pertama-tama, Anda harus mengidentifikasi node mana yang akan terus menyajikan data sebagai master. Ini adalah kumpulan data tempat Anda akan menggabungkan data yang disimpan di instans "master" lainnya. Setelah selesai, Anda harus mengidentifikasi data dari master lama yang hilang pada master saat ini. Ini akan menjadi pekerjaan manual. Jika Anda memiliki stempel waktu di tabel Anda, Anda dapat memanfaatkannya untuk menentukan data yang hilang. Pada akhirnya, log biner akan berisi semua modifikasi data sehingga Anda dapat mengandalkannya. Anda mungkin juga harus mengandalkan pengetahuan Anda tentang struktur data dan hubungan antar tabel. Jika data Anda dinormalisasi, satu record dalam satu tabel bisa terkait dengan record di tabel lain. Misalnya, aplikasi Anda mungkin memasukkan data ke tabel “pengguna” yang terkait dengan tabel “alamat” menggunakan user_id. Anda harus menemukan semua baris terkait dan mengekstraknya.
Langkah selanjutnya adalah memuat data ini ke master baru. Inilah bagian yang sulit - jika Anda menyiapkan pengaturan Anda sebelumnya, ini bisa jadi hanya masalah menjalankan beberapa sisipan. Jika tidak, ini mungkin agak rumit. Ini semua tentang kunci utama dan nilai indeks unik. Jika nilai kunci utama Anda dibuat sebagai unik di setiap server menggunakan semacam generator UUID atau menggunakan pengaturan auto_increment_increment dan auto_increment_offset di MySQL, Anda dapat yakin bahwa data dari master lama yang harus Anda masukkan tidak akan menyebabkan kunci utama atau unik konflik kunci dengan data pada master baru. Jika tidak, Anda mungkin harus secara manual mengubah data dari master lama untuk memastikannya dapat dimasukkan dengan benar. Kedengarannya rumit, jadi mari kita lihat contohnya.
Mari kita bayangkan kita menyisipkan baris menggunakan auto_increment pada node A, yang merupakan master. Demi kesederhanaan, kami akan fokus pada satu baris saja. Ada kolom 'id' dan 'value'.
Jika kita memasukkannya tanpa pengaturan tertentu, kita akan melihat entri seperti di bawah ini:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Mereka akan mereplikasi ke budak (B). Jika terjadi split brain dan write akan dieksekusi pada master lama dan baru, kita akan berakhir dengan situasi berikut:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Seperti yang Anda lihat, tidak ada cara untuk membuang record dengan id 1004, 1005 dan 1006 dari node A dan menyimpannya di node B karena kita akan berakhir dengan duplikat entri kunci utama. Yang perlu dilakukan adalah mengubah nilai kolom id pada baris yang akan disisipkan menjadi nilai yang lebih besar dari nilai maksimum kolom id dari tabel. Ini semua yang dibutuhkan untuk satu baris. Untuk relasi yang lebih kompleks, di mana banyak tabel terlibat, Anda mungkin harus membuat perubahan di beberapa lokasi.
Di sisi lain, jika kita telah mengantisipasi potensi masalah ini dan mengonfigurasi node kita untuk menyimpan id ganjil di node A dan id genap di node B, masalahnya akan jauh lebih mudah dipecahkan.
Node A dikonfigurasi dengan auto_increment_offset =1 dan auto_increment_increment =2
Node B dikonfigurasi dengan auto_increment_offset =2 dan auto_increment_increment =2
Beginilah tampilan data pada node A sebelum split brain:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Jika terjadi split brain maka akan terlihat seperti di bawah ini.
Simpul A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Simpul B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Sekarang kita dapat dengan mudah menyalin data yang hilang dari node A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Dan muat ke node B yang berakhir dengan kumpulan data berikut:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Tentu, baris tidak dalam urutan aslinya, tetapi ini seharusnya baik-baik saja. Dalam skenario terburuk, Anda harus mengurutkan berdasarkan kolom 'nilai' dalam kueri dan mungkin menambahkan indeks di atasnya untuk mempercepat penyortiran.
Sekarang, bayangkan ratusan atau ribuan baris dan struktur tabel yang sangat dinormalisasi - untuk memulihkan satu baris mungkin berarti Anda harus memulihkan beberapa di antaranya di tabel tambahan. Dengan kebutuhan untuk mengubah id (karena Anda tidak memiliki pengaturan pelindung) di semua baris terkait dan semua ini adalah pekerjaan manual, Anda dapat membayangkan bahwa ini bukan situasi terbaik. Butuh waktu untuk memulihkan dan itu adalah proses yang rawan kesalahan. Untungnya, seperti yang telah kita bahas di awal, ada cara untuk meminimalkan kemungkinan bahwa otak terbelah akan berdampak pada sistem Anda atau untuk mengurangi pekerjaan yang perlu dilakukan untuk menyinkronkan kembali node Anda. Pastikan Anda menggunakannya dan tetap siap.