Untuk mengoperasikan basis data apa pun secara efisien, Anda harus memiliki wawasan tentang kinerja basis data. Hal ini mungkin tidak terlihat saat semuanya berjalan dengan baik, tetapi begitu terjadi kesalahan, akses ke informasi dapat berperan penting dalam mendiagnosis masalah dengan cepat dan benar.
Semua database membuat beberapa data status internal mereka tersedia untuk pengguna. Di MySQL, Anda bisa mendapatkan data ini sebagian besar dengan menjalankan 'SHOW STATUS' dan 'SHOW GLOBAL STATUS', dengan menjalankan 'SHOW ENGINE INNODB STATUS', memeriksa tabel information_schema dan, dalam versi yang lebih baru, dengan menanyakan tabel performance_schema.

Metode ini jauh dari nyaman dalam operasi sehari-hari, oleh karena itu popularitas solusi pemantauan dan tren yang berbeda. Alat seperti Nagios/Icinga dirancang untuk mengawasi host/layanan, dan memperingatkan saat layanan berada di luar rentang yang dapat diterima. Alat lain seperti Cacti dan Munin memberikan tampilan grafis pada informasi host/layanan, dan memberikan konteks historis untuk kinerja dan penggunaan. ClusterControl menggabungkan dua jenis pemantauan ini, jadi kita akan melihat informasi yang disajikan, dan bagaimana kita harus menafsirkannya.
Jika Anda menggunakan Galera Cluster (MySQL Galera Cluster by Codership atau MariaDB Cluster atau Percona XtraDB Cluster), Anda mungkin telah memperhatikan bagian berikut di tab "Overview" ClusterControl:
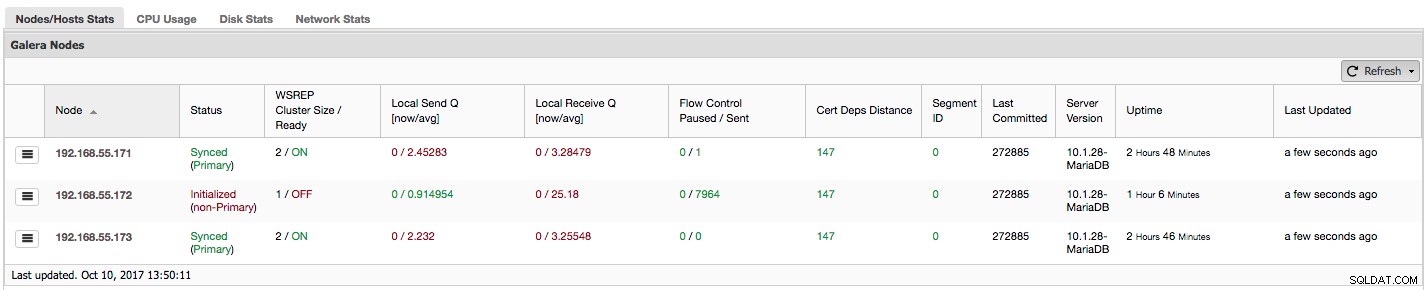
Mari kita lihat, langkah demi langkah, data seperti apa yang kita miliki di sini.
Kolom pertama berisi daftar node dengan alamat IP-nya - tidak banyak yang bisa dikatakan tentangnya.
Kolom kedua lebih menarik - menggambarkan status simpul (wsrep_local_state_comment status). Sebuah node dapat berada dalam status yang berbeda:
- Diinisialisasi - Node aktif dan berjalan, tetapi bukan bagian dari kluster. Ini dapat disebabkan, misalnya, oleh masalah jaringan;
- Bergabung - Node sedang dalam proses bergabung dengan cluster dan menerima atau meminta transfer status dari salah satu node lain;
- Donor/Desynced - Node berfungsi sebagai donor untuk beberapa node lain yang bergabung dengan cluster;
- Bergabung - Node bergabung dengan cluster tetapi sibuk mengejar set tulis yang dikomit;
- Disinkronkan - Node berfungsi normal.
Di kolom yang sama di dalam kurung adalah status cluster (wsrep_cluster_status status). Itu dapat memiliki tiga status berbeda:
- Utama - Komunikasi antar node berfungsi dan kuorum ada (mayoritas node tersedia)
- Non-Utama - Node adalah bagian dari kluster tetapi, karena alasan tertentu, kehilangan kontak dengan kluster lainnya. Akibatnya, simpul ini dianggap tidak aktif dan tidak akan menerima kueri
- Terputus - Node tidak dapat membangun komunikasi grup.
"WSREP Cluster Size / Ready" memberi tahu kita tentang ukuran cluster saat node melihatnya, dan apakah node siap menerima kueri. Komponen Non-Primary membuat cluster dengan ukuran 1 dan kesiapan wsrep NONAKTIF.
Mari kita lihat tangkapan layar di atas, dan lihat apa yang diceritakannya tentang Galera. Kita bisa melihat tiga node. Dua di antaranya (192.168.55.171 dan 192.168.55.173) baik-baik saja, keduanya "Disinkronkan" dan cluster dalam status "Utama". Cluster saat ini terdiri dari dua node. Node 192.168.55.172 adalah "Diinisialisasi" dan membentuk komponen "non-Utama". Artinya node ini kehilangan koneksi dengan cluster - kemungkinan besar semacam masalah jaringan (pada kenyataannya, kami menggunakan iptables untuk memblokir lalu lintas ke node ini dari 192.168.55.171 dan 192.168.55.173).
Saat ini kita harus berhenti sejenak dan menjelaskan bagaimana Galera Cluster bekerja secara internal. Kami tidak akan membahas terlalu banyak detail karena tidak termasuk dalam cakupan posting blog ini, tetapi beberapa pengetahuan diperlukan untuk memahami pentingnya data yang disajikan di kolom berikutnya.
Galera adalah cluster multi-master yang "hampir" sinkron. Ini berarti bahwa Anda harus mengharapkan data untuk ditransfer melintasi node "secara virtual" pada saat yang sama (tidak ada lagi masalah yang mengganggu dengan slave yang tertinggal) dan bahwa Anda dapat menulis ke node mana pun dalam sebuah cluster (tidak ada lagi masalah yang mengganggu dengan mempromosikan slave ke master ). Untuk mencapai itu, Galera menggunakan writesets - kumpulan perubahan atom yang direplikasi di seluruh cluster. Writeset dapat berisi beberapa perubahan baris dan informasi tambahan yang diperlukan seperti data terkait penguncian.
Setelah klien mengeluarkan COMMIT, tetapi sebelum MySQL benar-benar melakukan apa pun, sebuah writeset dibuat dan dikirim ke semua node di cluster untuk sertifikasi. Semua node memeriksa apakah mungkin untuk melakukan perubahan atau tidak (karena perubahan dapat mengganggu penulisan lain yang dieksekusi, sementara itu, langsung pada node lain). Jika ya, data benar-benar dikomit oleh MySQL, jika tidak, rollback dijalankan.
Yang penting untuk diingat adalah fakta bahwa node, mirip dengan slave dalam replikasi reguler, dapat bekerja secara berbeda - beberapa mungkin memiliki perangkat keras yang lebih baik daripada yang lain, beberapa mungkin lebih dimuat daripada yang lain. Namun Galera mengharuskan mereka untuk memproses set tulis secara singkat dan cepat, untuk menjaga sinkronisasi "virtual". Harus ada mekanisme yang dapat membatasi replikasi dan memungkinkan node yang lebih lambat untuk mengikuti sisa cluster.
Mari kita lihat kolom "Pengiriman Lokal Q [sekarang/rata-rata]" dan "Penerimaan Lokal Q [sekarang/rata-rata]". Setiap node memiliki antrian lokal untuk mengirim dan menerima writeset. Ini memungkinkan untuk memparalelkan beberapa penulisan dan data antrian yang tidak dapat diproses sekaligus jika node tidak dapat mengikuti lalu lintas. Dalam SHOW GLOBAL STATUS kita dapat menemukan delapan penghitung yang menjelaskan kedua antrian, empat penghitung per antrian:
- wsrep_local_send_queue - status antrian pengiriman saat ini
- wsrep_local_send_queue_min - minimal sejak FLUSH STATUS
- wsrep_local_send_queue_max - maksimum sejak FLUSH STATUS
- wsrep_local_send_queue_avg - rata-rata sejak FLUSH STATUS
- wsrep_local_recv_queue - status antrian penerimaan saat ini
- wsrep_local_recv_queue_min - minimal sejak FLUSH STATUS
- wsrep_local_recv_queue_max - maksimum sejak FLUSH STATUS
- wsrep_local_recv_queue_avg - rata-rata sejak FLUSH STATUS
Metrik di atas disatukan di seluruh node di bawah ClusterControl -> Performance -> DB Status:
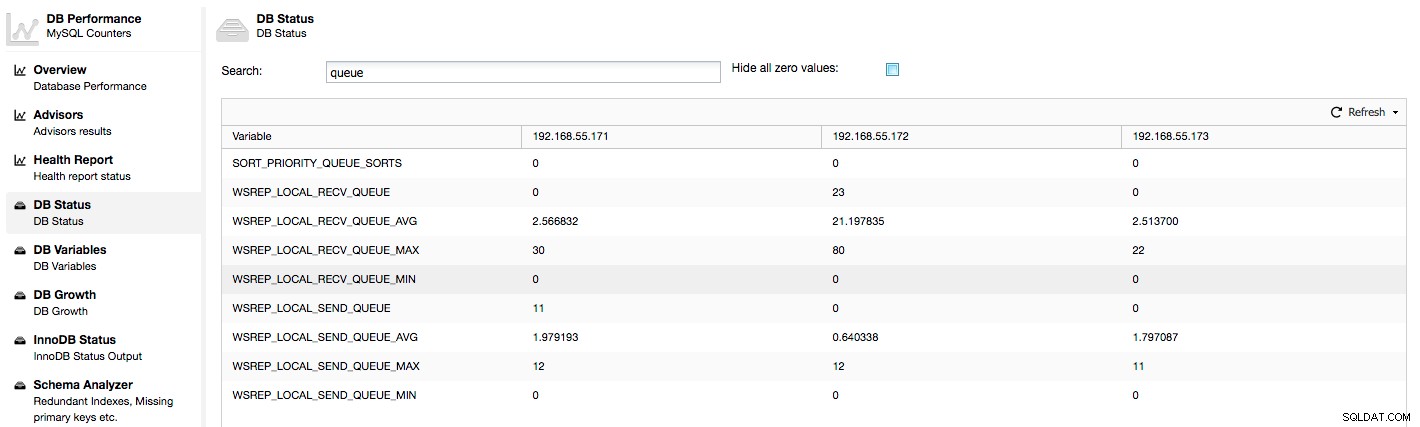
ClusterControl menampilkan penghitung "sekarang" dan "rata-rata", karena ini adalah yang paling bermakna sebagai angka tunggal (Anda juga dapat membuat grafik khusus berdasarkan variabel yang menjelaskan status antrian saat ini). Ketika kita melihat bahwa salah satu antrian meningkat, ini berarti bahwa node tidak dapat mengikuti replikasi dan node lain harus melambat untuk memungkinkannya mengejar. Kami menyarankan untuk menyelidiki beban kerja dari node yang diberikan - periksa daftar proses untuk beberapa kueri yang berjalan lama, periksa statistik OS seperti penggunaan CPU dan beban kerja I/O. Mungkin juga mungkin untuk mendistribusikan kembali sebagian lalu lintas dari simpul tersebut ke bagian kluster lainnya.
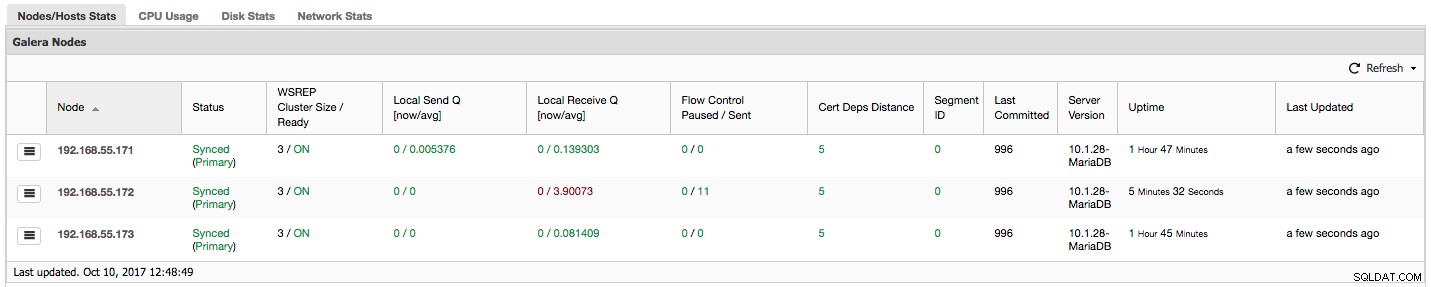
"Kontrol Aliran Dijeda" menunjukkan informasi tentang persentase waktu yang diberikan node untuk menjeda replikasinya karena beban yang terlalu berat. Ketika sebuah node tidak dapat mengikuti beban kerja, ia mengirim paket Kontrol Aliran ke node lain, memberi tahu mereka bahwa mereka harus mengurangi pengiriman writeset. Di tangkapan layar kami, kami memiliki nilai '0,30' untuk node 192.168.55.172. Ini berarti hampir 30% dari waktu node ini harus menjeda replikasi karena tidak dapat mengikuti tingkat sertifikasi writeset yang diperlukan oleh node lain (atau lebih sederhana, terlalu banyak penulisan yang berhasil!). Seperti yang dapat kita lihat, "Penerimaan Lokal Q [rata-rata]" juga menunjukkan fakta ini kepada kita.
Kolom berikutnya, "Kontrol Aliran Terkirim" memberi kita informasi tentang berapa banyak paket Kontrol Aliran yang dikirim oleh node tertentu ke cluster. Sekali lagi, kita melihat bahwa itu adalah node 192.168.55.172 yang memperlambat cluster.
Apa yang dapat kita lakukan dengan informasi ini? Sebagian besar, kita harus menyelidiki apa yang terjadi di node lambat. Periksa penggunaan CPU, periksa kinerja I/O dan statistik jaringan. Langkah pertama ini membantu menilai masalah seperti apa yang kita hadapi.
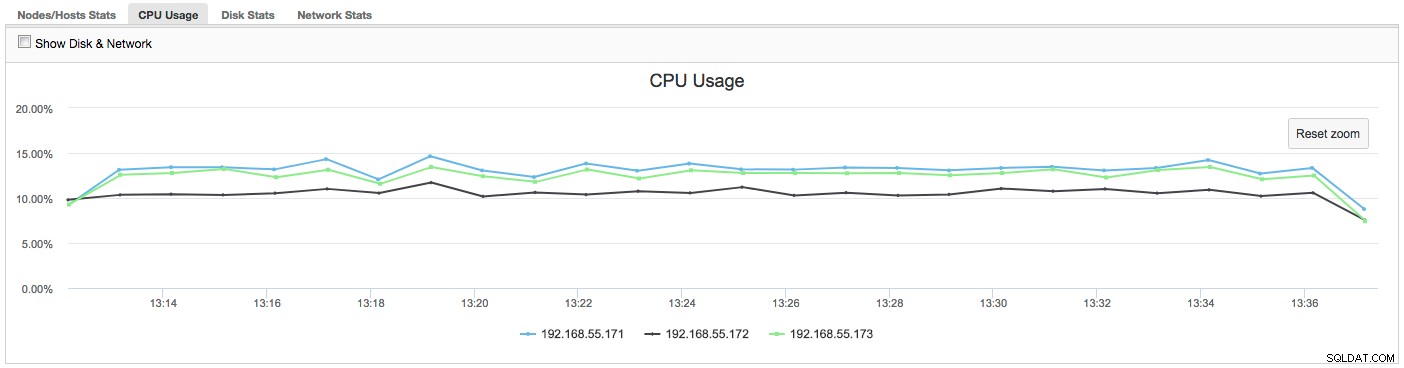
Dalam hal ini, setelah kami beralih ke tab Penggunaan CPU, menjadi jelas bahwa penggunaan CPU yang ekstensif menyebabkan masalah kami. Langkah selanjutnya adalah mengidentifikasi pelakunya dengan melihat PROCESSLIST (Query Monitor -> Running Queries -> filter by 192.168.55.172) untuk memeriksa kueri yang menyinggung:
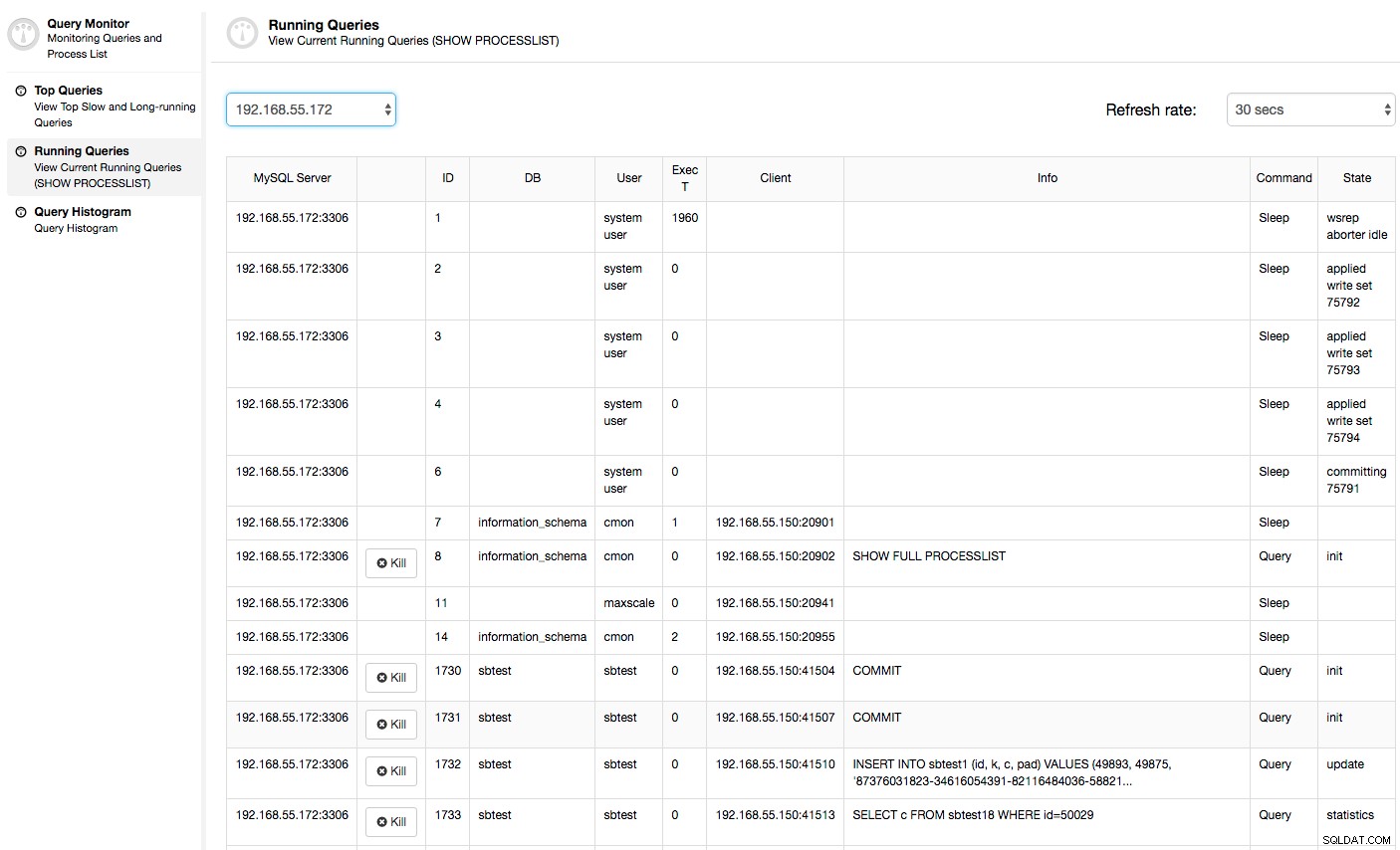
Atau, periksa proses pada node dari sisi sistem operasi (Nodes -> 192.168.55.172 -> Top) untuk melihat apakah pemuatan tidak disebabkan oleh sesuatu di luar Galera/MySQL.
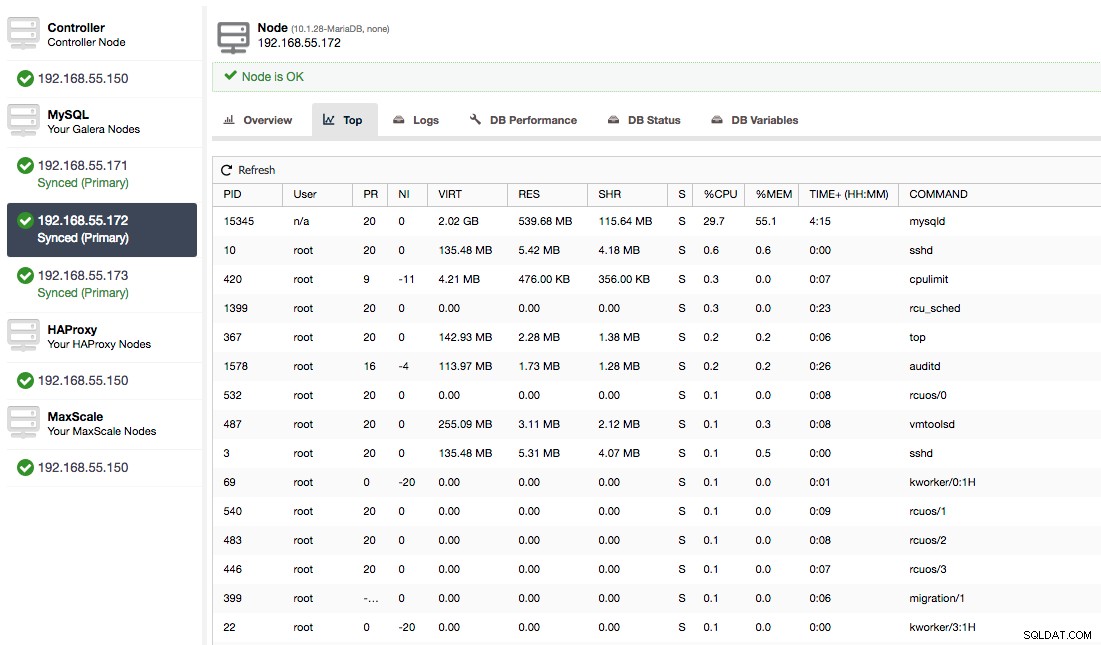
Dalam hal ini, kami telah menjalankan perintah mysqld melalui cpulimit, untuk mensimulasikan penggunaan CPU yang lambat khusus untuk proses mysqld dengan membatasi hingga 30% dari 400% CPU yang tersedia (server memiliki 4 core).
Kolom "Cert Deps Distance" memberi kita informasi tentang berapa banyak writeset, rata-rata, yang dapat diterapkan secara paralel. Writeset terkadang dapat dieksekusi pada saat yang sama - Galera memanfaatkan ini dengan menggunakan beberapa wsrep_slave_threads untuk menerapkan writeset. Kolom ini memberi Anda gambaran tentang berapa banyak utas budak yang dapat Anda gunakan pada beban kerja Anda. Perlu diperhatikan bahwa tidak ada gunanya menyiapkan wsrep_slave_threads variabel ke nilai yang lebih tinggi daripada yang Anda lihat di kolom ini atau di wsrep_cert_deps_distance variabel status, yang menjadi dasar kolom "Cert Deps Distance". Catatan penting lainnya - tidak ada gunanya mengatur wsrep_slave_threads variabel menjadi lebih dari jumlah inti yang dimiliki CPU Anda.
"ID Segmen" - kolom ini memerlukan penjelasan lebih lanjut. Segmen adalah fitur baru yang ditambahkan di Galera 3.0. Sebelum versi ini, writeset dipertukarkan di antara semua node. Katakanlah kita memiliki dua pusat data:
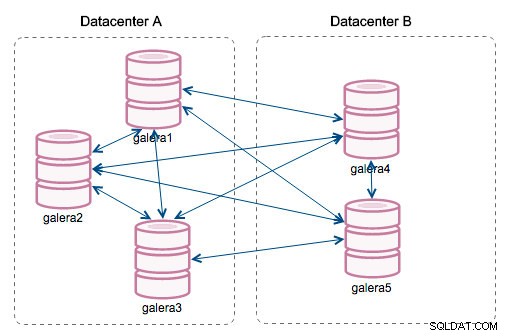
Obrolan semacam ini berfungsi baik di jaringan lokal tetapi WAN adalah cerita yang berbeda - sertifikasi melambat karena peningkatan latensi, biaya tambahan dihasilkan karena bandwidth jaringan yang digunakan untuk mentransfer set tulis antara setiap anggota cluster.
Dengan diperkenalkannya "Segmen", segalanya berubah. Anda dapat menetapkan simpul ke segmen dengan memodifikasi wsrep_provider_options variabel dan menambahkan "gmcast.segment=x" (0, 1, 2) ke dalamnya. Node dengan nomor segmen yang sama diperlakukan seperti berada di pusat data yang sama, dihubungkan oleh jaringan lokal. Grafik kita kemudian menjadi berbeda:
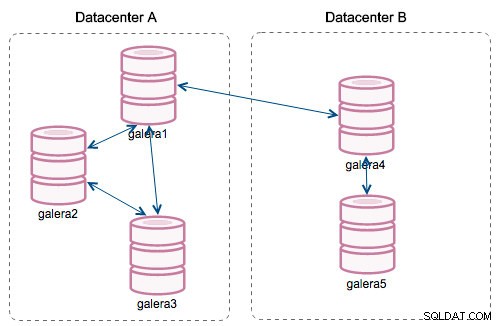
Perbedaan utamanya adalah tidak ada lagi komunikasi semua orang ke semua orang. Dalam setiap segmen, ya - mekanismenya masih sama tetapi kedua segmen berkomunikasi hanya melalui satu koneksi antara dua node yang dipilih. Dalam kasus downtime, koneksi ini akan failover secara otomatis. Akibatnya, kami mendapatkan lebih sedikit obrolan jaringan dan lebih sedikit penggunaan bandwidth antara pusat data jarak jauh. Jadi, pada dasarnya, kolom "ID Segmen" memberitahu kita ke segmen mana sebuah node ditugaskan.
Kolom "Last Committed" memberi kita informasi tentang nomor urut dari writeset yang terakhir dieksekusi pada node tertentu. Ini dapat berguna dalam menentukan node mana yang paling baru jika ada kebutuhan untuk mem-bootstrap cluster.
Kolom lainnya cukup jelas:Versi server, waktu aktif node, dan kapan status diperbarui.
Seperti yang Anda lihat, bagian "Galera Nodes" dari "Node/Hosts Stats" di tab "Overview" memberi Anda pemahaman yang cukup baik tentang kesehatan cluster - apakah itu membentuk komponen "Utama", berapa banyak node yang sehat , apakah ada masalah kinerja dengan beberapa node dan jika ya, node mana yang memperlambat cluster.
Kumpulan data ini sangat berguna saat Anda mengoperasikan kluster Galera Anda, jadi semoga tidak ada lagi flying blind :-)



