Pertanyaan Anda sangat tidak tepat. Silakan, ikuti saran @RiggsFolly dan baca referensi tentang cara mengajukan pertanyaan yang baik.
Juga, seperti yang disarankan oleh @DuduMarkovitz, Anda harus mulai dengan menyederhanakan masalah dan membersihkan data Anda. Beberapa sumber daya untuk membantu Anda memulai:
- Tutorial Pemrosesan Teks Dasar oleh Matt Deny
- Menangani dan Memproses String di R oleh Gaston Sanchez
Setelah Anda puas dengan hasilnya, Anda dapat melanjutkan untuk mengidentifikasi grup untuk setiap Var1 entri (ini akan membantu Anda di jalan untuk melakukan analisis/manipulasi lebih lanjut pada entri serupa) Ini dapat dilakukan dengan berbagai cara tetapi seperti yang disebutkan oleh @GordonLinoff, salah satunya adalah Jarak Levenshtein.
Catatan :untuk 50 ribu entri, hasilnya tidak akan 100% akurat karena tidak selalu mengkategorikan istilah dalam kelompok yang sesuai tetapi ini akan sangat mengurangi upaya manual.
Di R, Anda dapat melakukan ini menggunakan adist()
Menggunakan data contoh Anda:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
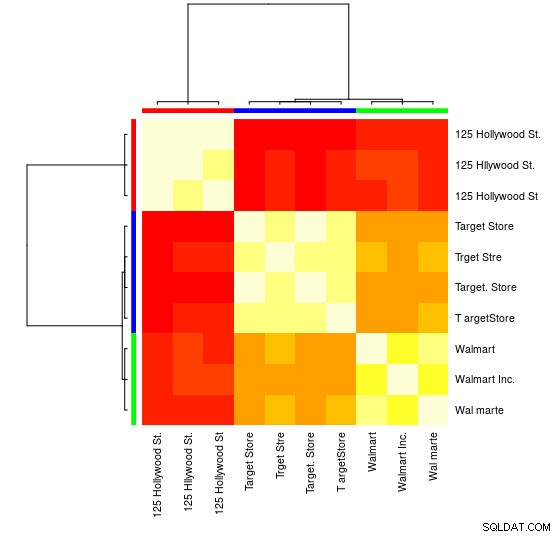
Untuk sampel kecil ini, Anda dapat melihat 3 grup berbeda (cluster dengan nilai Levensthein Distance rendah) dan dapat dengan mudah menetapkannya secara manual, tetapi untuk set yang lebih besar, Anda mungkin memerlukan algoritme pengelompokan.
Saya sudah mengarahkan Anda di komentar ke salah satu jawaban sebelumnya
menunjukkan bagaimana melakukan ini menggunakan hclust() dan metode varians minimum Ward tetapi saya pikir di sini Anda akan lebih baik menggunakan teknik lain (salah satu sumber favorit saya tentang topik ini untuk gambaran singkat tentang beberapa metode yang paling banyak digunakan di R adalah ini jawaban mendetail
)
Berikut ini contoh menggunakan pengelompokan propagasi afinitas:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
Anda akan menemukan di objek APResult d_ap elemen-elemen yang terkait dengan setiap cluster dan jumlah cluster yang optimal, dalam hal ini:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Anda juga dapat melihat representasi visual:
> heatmap(d_ap, margins = c(10, 10))
Kemudian, Anda dapat melakukan manipulasi lebih lanjut untuk setiap grup. Sebagai contoh, disini saya menggunakan hunspell untuk mencari setiap kata terpisah dari Var1 dalam kamus en_US untuk kesalahan ejaan dan coba temukan, dalam setiap group , yang id tidak memiliki kesalahan ejaan (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Yang memberikan:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Catatan :Di sini karena kami belum melakukan pemrosesan teks apa pun, hasilnya tidak terlalu meyakinkan, tetapi Anda mengerti.
Data
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)