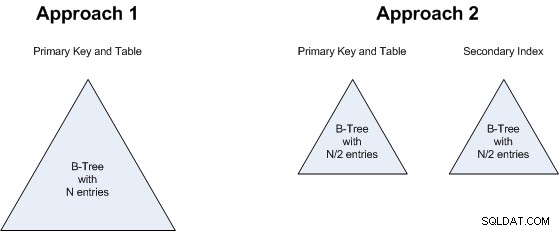
Berikut adalah bagaimana kedua pendekatan ini akan direpresentasikan secara fisik dalam database:
Mari kita menganalisis kedua pendekatan...
Pendekatan 1 (kedua arah disimpan dalam tabel):
- PRO:Kueri yang lebih sederhana.
- CON:Data dapat rusak dengan menyisipkan/memperbarui/menghapus hanya satu arah.
- MINOR PRO:Tidak memerlukan batasan tambahan untuk memastikan persahabatan tidak dapat diduplikasi.
- Analisis lebih lanjut diperlukan:
- TIE:Satu indeks meliputi kedua arah, jadi Anda tidak memerlukan indeks sekunder.
- TIE:Persyaratan penyimpanan.
- TIE:Performa.
Pendekatan 2 (hanya satu arah yang disimpan dalam tabel):
- CON:Kueri yang lebih rumit.
- PRO:Tidak dapat merusak data dengan lupa menangani arah yang berlawanan, karena tidak ada arah yang berlawanan .
- MINOR CON:Memerlukan
CHECK(UID < FriendID), jadi persahabatan yang sama tidak akan pernah bisa diwakili dalam dua cara yang berbeda, dan kuncinya di(UID, FriendID)dapat melakukan tugasnya. - Analisis lebih lanjut diperlukan:
- TIE:Dua indeks diperlukan untuk menutupi
kedua arah kueri (indeks gabungan pada
{UID, FriendID}dan indeks komposit di{FriendID, UID}). - TIE:Persyaratan penyimpanan.
- TIE:Performa.
- TIE:Dua indeks diperlukan untuk menutupi
kedua arah kueri (indeks gabungan pada
Poin 1 adalah kepentingan khusus. MySQL/InnoDB selalu cluster data, dan indeks sekunder bisa mahal dalam tabel berkerumun (lihat "Kekurangan pengelompokan" di artikel ini ), jadi sepertinya indeks sekunder dalam pendekatan 2 akan menghabiskan semua keuntungan dari lebih sedikit baris. Namun , indeks sekunder berisi bidang yang sama persis dengan indeks utama (hanya dalam urutan yang berlawanan) sehingga tidak ada overhead penyimpanan dalam kasus khusus ini. Juga tidak ada penunjuk ke tumpukan tabel (karena tidak ada tumpukan tabel), jadi mungkin lebih murah dari segi penyimpanan daripada indeks berbasis tumpukan normal. Dan dengan asumsi kueri ditutupi dengan indeks, tidak akan ada pencarian ganda yang biasanya terkait dengan indeks sekunder dalam tabel berkerumun juga. Jadi, ini pada dasarnya seri (baik pendekatan 1 maupun pendekatan 2 tidak memiliki keuntungan yang signifikan).
Poin 2 terkait dengan poin 1:tidak masalah apakah kita akan memiliki B-Tree dengan nilai N atau dua B-Trees, masing-masing dengan nilai N/2. Jadi ini juga mengikat:kedua pendekatan akan menggunakan jumlah penyimpanan yang kira-kira sama.
Alasan yang sama berlaku untuk poin 3 :apakah kita mencari satu B-Tree yang lebih besar atau 2 yang lebih kecil, tidak membuat banyak perbedaan, jadi ini juga seri.
Jadi, untuk kekokohan, dan meskipun ada pertanyaan yang lebih buruk dan kebutuhan untuk CHECK tambahan , saya akan menggunakan pendekatan 2.