Sedikit pemikiran tentang ini:
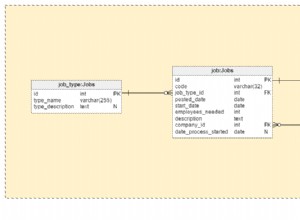
Saya akan mencoba memodelkan model domain Neo4j Anda untuk memasukkan atribut setiap node dalam grafik. Dengan memisahkan data Anda menjadi dua penyimpanan data yang berbeda, Anda mungkin membatasi beberapa operasi yang mungkin ingin Anda lakukan.
Saya kira itu tergantung pada apa yang akan Anda lakukan dengan grafik Anda. Jika, misalnya, Anda ingin menemukan semua simpul yang terhubung ke simpul tertentu yang atributnya (yaitu nama, usia.. apa pun) adalah nilai tertentu, apakah Anda terlebih dahulu harus menemukan ID simpul yang benar di database MySQL Anda dan kemudian masuk ke Neo4j? Ini sepertinya lambat dan terlalu rumit ketika Anda bisa melakukan semua ini di Neo4j. Jadi pertanyaannya adalah:apakah Anda memerlukan atribut simpul saat melintasi grafik?
Apakah data Anda akan berubah atau statis? Dengan memiliki dua penyimpanan data yang terpisah akan memperumit masalah.
Sementara menghasilkan statistik menggunakan database MySQL mungkin lebih mudah daripada melakukan semuanya di Neo4j, kode yang diperlukan untuk melintasi grafik untuk menemukan semua node yang memenuhi kriteria yang ditentukan tidak terlalu sulit. Apa statistik ini yang akan mendorong solusi Anda.
Saya tidak dapat mengomentari kinerja kueri MySQL untuk memilih id simpul. Saya kira itu tergantung pada berapa banyak node yang perlu Anda pilih dan strategi pengindeksan Anda. Saya setuju tentang sisi kinerja dalam hal melintasi grafik.
Ini adalah artikel bagus tentang ini:MySQL vs. Neo4j pada Traversal Grafik Skala Besar dan dalam hal ini, ketika mereka mengatakan besar, itu hanya berarti satu juta simpul/simpul dan empat juta tepi. Jadi itu bahkan bukan grafik yang sangat padat.