Anda hanya dapat mengakses elemen dengan kunci utama mereka dalam tabel hash. Ini lebih cepat daripada dengan algoritma pohon (O(1) bukannya log(n) ), tetapi Anda tidak dapat memilih rentang (semuanya di antara x dan y ).Algoritme pohon mendukung ini di Log(n) sedangkan indeks hash dapat menghasilkan pemindaian tabel penuh O(n) . Juga overhead konstan dari indeks hash biasanya lebih besar (yang bukan merupakan faktor dalam notasi theta, tetapi masih ada ).Algoritme pohon juga biasanya lebih mudah dipelihara, dikembangkan dengan data, skala, dll.
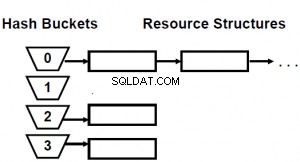
Indeks hash bekerja dengan ukuran hash yang telah ditentukan sebelumnya, jadi Anda akan mendapatkan beberapa "ember" tempat objek disimpan. Objek ini dilingkarkan lagi untuk benar-benar menemukan yang tepat di dalam partisi ini.
Jadi, jika Anda memiliki ukuran kecil, Anda memiliki banyak overhead untuk elemen kecil, ukuran besar menghasilkan pemindaian lebih lanjut.
Algoritma tabel hash saat ini biasanya menskalakan, tetapi penskalaan bisa jadi tidak efisien.
Namun mungkin ada titik di mana indeks Anda melebihi ukuran yang dapat ditoleransi dibandingkan dengan ukuran hash Anda dan seluruh indeks Anda perlu dibangun kembali. Biasanya ini bukan masalah, tetapi untuk database yang sangat besar, ini bisa memakan waktu berhari-hari.
Pengorbanan untuk algoritme pohon kecil dan cocok untuk hampir semua kasus penggunaan dan karenanya merupakan default.
Namun jika Anda memiliki kasus penggunaan yang sangat tepat dan Anda tahu persis apa dan hanya apa yang akan dibutuhkan, Anda dapat memanfaatkan indeks hashing.