Anda semua telah mendengar tentang penskalaan - arsitektur Anda harus dapat diskalakan, Anda harus dapat meningkatkan skala untuk memenuhi permintaan, seterusnya dan seterusnya. Apa artinya ketika kita berbicara tentang database? Seperti apa penskalaan di balik layar? Topik ini sangat luas dan tidak ada cara untuk mencakup semua aspek. Seri entri dua blog ini adalah upaya untuk memberi Anda wawasan tentang topik skalabilitas basis data.
Mengapa kita Menskalakan?
Pertama, mari kita lihat apa itu skalabilitas. Singkatnya, kita berbicara tentang kemampuan untuk menangani beban yang lebih tinggi oleh sistem database Anda. Ini bisa menjadi masalah menangani lonjakan singkat dalam aktivitas, itu bisa menjadi masalah menangani beban kerja yang meningkat secara bertahap di lingkungan database Anda. Ada banyak alasan untuk mempertimbangkan penskalaan. Kebanyakan dari mereka datang dengan tantangan mereka sendiri. Kita dapat meluangkan waktu untuk melihat contoh situasi yang mungkin ingin kita perkecil.
Konsumsi sumber daya meningkat
Ini adalah yang paling umum - beban Anda telah meningkat ke titik di mana sumber daya Anda yang ada tidak lagi mampu menanganinya. Itu bisa apa saja. Beban CPU telah meningkat dan cluster database Anda tidak lagi dapat mengirimkan data dengan waktu eksekusi kueri yang wajar dan stabil. Pemanfaatan memori telah berkembang sedemikian rupa sehingga database tidak lagi terikat CPU tetapi menjadi terikat I/O dan, dengan demikian, kinerja node database telah berkurang secara signifikan. Jaringan juga bisa menjadi penyelundup. Anda mungkin terkejut melihat batasan apa yang terkait dengan jaringan yang telah ditetapkan oleh instance cloud Anda. Faktanya, ini mungkin menjadi batasan paling umum yang harus Anda tangani karena jaringan adalah segalanya di cloud - bukan hanya data yang dikirim antara aplikasi dan database, tetapi juga penyimpanan terpasang melalui jaringan. Ini juga bisa karena penggunaan disk - Anda hanya kehabisan ruang disk atau, lebih mungkin, mengingat kita dapat memiliki disk yang cukup besar saat ini, ukuran basis data melebihi ukuran yang "dapat dikelola". Pemeliharaan seperti perubahan skema menjadi tantangan, kinerja berkurang karena ukuran data, pencadangan membutuhkan waktu lama untuk diselesaikan. Semua kasus tersebut mungkin merupakan kasus yang valid untuk kebutuhan peningkatan.
Peningkatan beban kerja secara tiba-tiba
Contoh kasus lain di mana penskalaan diperlukan adalah peningkatan beban kerja secara tiba-tiba. Untuk beberapa alasan (baik itu upaya pemasaran, konten menjadi viral, darurat atau situasi serupa) infrastruktur Anda mengalami peningkatan yang signifikan dalam beban pada cluster database. Beban CPU melampaui atap, I/O disk memperlambat kueri, dll. Hampir semua sumber daya yang kami sebutkan di bagian sebelumnya dapat kelebihan beban dan mulai menyebabkan masalah.
Operasi yang direncanakan
Alasan ketiga yang ingin kami soroti adalah alasan yang lebih umum - semacam operasi yang direncanakan. Ini bisa menjadi aktivitas pemasaran terencana yang Anda harapkan untuk mendatangkan lebih banyak lalu lintas, Black Friday, pengujian beban, atau apa pun yang Anda ketahui sebelumnya.
Masing-masing alasan tersebut memiliki karakteristiknya sendiri. Jika Anda dapat merencanakan sebelumnya, Anda dapat mempersiapkan prosesnya secara mendetail, mengujinya, dan menjalankannya kapan pun Anda mau. Anda kemungkinan besar ingin melakukannya dalam periode "lalu lintas rendah", selama sesuatu seperti itu ada di beban kerja Anda (tidak harus ada). Di sisi lain, lonjakan beban yang tiba-tiba, terutama jika cukup signifikan untuk mempengaruhi produksi, akan memaksa reaksi segera, tidak peduli seberapa siap Anda dan seberapa aman itu - jika layanan Anda sudah terpengaruh, Anda mungkin juga lakukanlah daripada menunggu.
Jenis Penskalaan Basis Data
Ada dua jenis penskalaan utama:vertikal dan horizontal. Keduanya memiliki pro dan kontra, keduanya berguna dalam situasi yang berbeda. Mari kita lihat dan diskusikan kasus penggunaan untuk kedua skenario.
Penskalaan vertikal
Metode penskalaan ini mungkin yang tertua:jika perangkat keras Anda tidak cukup kuat untuk menangani beban kerja, tingkatkan. Kami berbicara di sini hanya tentang menambahkan sumber daya ke node yang ada dengan maksud untuk membuat mereka cukup mampu untuk menangani tugas-tugas yang diberikan. Ini memiliki beberapa dampak yang ingin kami bahas.
Keuntungan penskalaan vertikal
Yang terpenting adalah semuanya tetap sama. Anda memiliki tiga node dalam cluster database, Anda masih memiliki tiga node, hanya lebih mampu. Tidak perlu mendesain ulang lingkungan Anda, mengubah cara aplikasi mengakses database - semuanya tetap sama persis karena, dari segi konfigurasi, tidak ada yang benar-benar berubah.
Keuntungan signifikan lainnya dari penskalaan vertikal adalah bisa sangat cepat, terutama di lingkungan cloud. Seluruh prosesnya, cukup banyak, untuk menghentikan node yang ada, membuat perubahan pada perangkat keras, memulai node lagi. Untuk penyiapan lokal klasik, tanpa virtualisasi apa pun, ini mungkin rumit - Anda mungkin tidak memiliki CPU yang lebih cepat yang tersedia untuk ditukar, memutakhirkan disk ke yang lebih besar atau lebih cepat mungkin juga memakan waktu, tetapi untuk lingkungan cloud, baik itu publik atau pribadi, ini bisa semudah menjalankan tiga perintah:stop instance, upgrade instance ke ukuran yang lebih besar, start instance. IP virtual dan volume yang dapat dilampirkan kembali memudahkan untuk memindahkan data antar-instance.
Kerugian penskalaan vertikal
Kelemahan utama penskalaan vertikal adalah, sederhananya, ia memiliki batasan. Jika Anda menggunakan ukuran instance terbesar yang tersedia, dengan volume disk tercepat, tidak banyak lagi yang dapat Anda lakukan. Juga tidak mudah untuk meningkatkan kinerja cluster database Anda secara signifikan. Sebagian besar tergantung pada ukuran instans awal, tetapi jika Anda sudah menjalankan node yang cukup berkinerja, Anda mungkin tidak dapat mencapai skala 10x menggunakan penskalaan vertikal. Node yang 10x lebih cepat mungkin tidak ada.
Penskalaan horizontal
Penskalaan horizontal adalah hal yang berbeda. Alih-alih naik dengan ukuran instance, kami tetap pada level yang sama tetapi kami memperluas secara horizontal dengan menambahkan lebih banyak node. Sekali lagi, ada pro dan kontra dari metode ini.
Kelebihan penskalaan horizontal
Keuntungan utama penskalaan horizontal adalah, secara teoritis, batasnya adalah langit. Tidak ada batasan keras buatan untuk scale-out, meskipun batasan memang ada, terutama karena komunikasi intra-cluster menjadi lebih besar dan overhead yang lebih besar dengan setiap node baru ditambahkan ke cluster.
Keuntungan signifikan lainnya adalah Anda dapat meningkatkan skala cluster tanpa perlu waktu henti. Jika Anda ingin memutakhirkan perangkat keras, Anda harus menghentikan instans, memutakhirkannya, lalu mulai lagi. Jika Anda ingin menambahkan lebih banyak node ke cluster, yang perlu Anda lakukan hanyalah menyediakan node tersebut, menginstal perangkat lunak apa pun yang Anda butuhkan, termasuk database, dan membiarkannya bergabung dengan cluster. Opsional (bergantung jika cluster memiliki metode internal untuk menyediakan node baru dengan data), Anda mungkin harus menyediakannya dengan data Anda sendiri. Namun, biasanya, ini adalah proses otomatis.
Kontra penskalaan horizontal
Masalah utama yang harus Anda tangani adalah penambahan node yang semakin banyak membuat sulit untuk mengelola seluruh lingkungan. Anda harus dapat mengetahui node mana yang tersedia, daftar seperti itu harus dipertahankan dan diperbarui dengan setiap node baru yang dibuat. Anda mungkin memerlukan solusi eksternal seperti layanan direktori (Konsul atau Dll) untuk melacak node dan statusnya. Ini, jelas, meningkatkan kompleksitas seluruh lingkungan.
Masalah potensial lainnya adalah proses scale-out membutuhkan waktu. Menambahkan node baru dan menyediakannya dengan perangkat lunak dan, terutama, data membutuhkan waktu. Berapa banyak, itu tergantung pada perangkat keras (terutama I/O dan throughput jaringan) dan ukuran data. Untuk pengaturan besar, ini mungkin memakan waktu yang lama dan ini mungkin menjadi penghalang untuk situasi di mana peningkatan skala harus segera dilakukan. Jam menunggu untuk menambahkan node baru mungkin tidak dapat diterima jika klaster database terpengaruh sejauh operasi tidak dilakukan dengan benar.
Prasyarat Penskalaan
Replikasi data
Sebelum upaya penskalaan apa pun dapat dilakukan, lingkungan Anda harus memenuhi beberapa persyaratan. Sebagai permulaan, aplikasi Anda harus dapat memanfaatkan lebih dari satu node. Jika hanya dapat menggunakan satu simpul, opsi Anda cukup terbatas pada penskalaan vertikal. Anda dapat meningkatkan ukuran node tersebut atau menambahkan beberapa sumber daya perangkat keras ke server bare metal dan membuatnya lebih berkinerja tetapi itulah yang terbaik yang dapat Anda lakukan:Anda akan selalu dibatasi oleh ketersediaan perangkat keras yang lebih berkinerja dan, pada akhirnya, Anda akan menemukan diri Anda sendiri tanpa opsi untuk meningkatkan lebih lanjut.
Di sisi lain, jika Anda memiliki sarana untuk memanfaatkan beberapa node database oleh aplikasi Anda, Anda dapat memanfaatkan penskalaan horizontal. Mari berhenti di sini dan diskusikan apa yang Anda perlukan untuk benar-benar menggunakan banyak node secara maksimal.
Sebagai permulaan, kemampuan untuk membagi pembacaan dari penulisan. Secara tradisional aplikasi hanya terhubung ke satu node. Node tersebut digunakan untuk menangani semua penulisan dan semua pembacaan yang dijalankan oleh aplikasi.

Menambahkan node kedua ke cluster, dari sudut pandang penskalaan, tidak mengubah apa pun . Anda harus ingat bahwa, jika satu node gagal, node lain harus menangani lalu lintas, jadi jumlah beban di kedua node tidak boleh terlalu tinggi untuk ditangani oleh satu node.

Dengan tiga node yang tersedia, Anda dapat sepenuhnya menggunakan dua node. Ini memungkinkan kami untuk menskalakan beberapa lalu lintas baca:jika satu node memiliki kapasitas 100% (dan kami lebih suka menjalankan paling banyak 70%), maka dua node mewakili 200%. Tiga node:300%. Jika satu node down dan jika kita akan mendorong node yang tersisa hampir ke batas, kita dapat mengatakan bahwa kita dapat bekerja dengan 170 - 180% dari kapasitas node tunggal jika cluster terdegradasi. Itu memberi kami beban 60% yang bagus pada setiap node jika ketiga node tersedia.
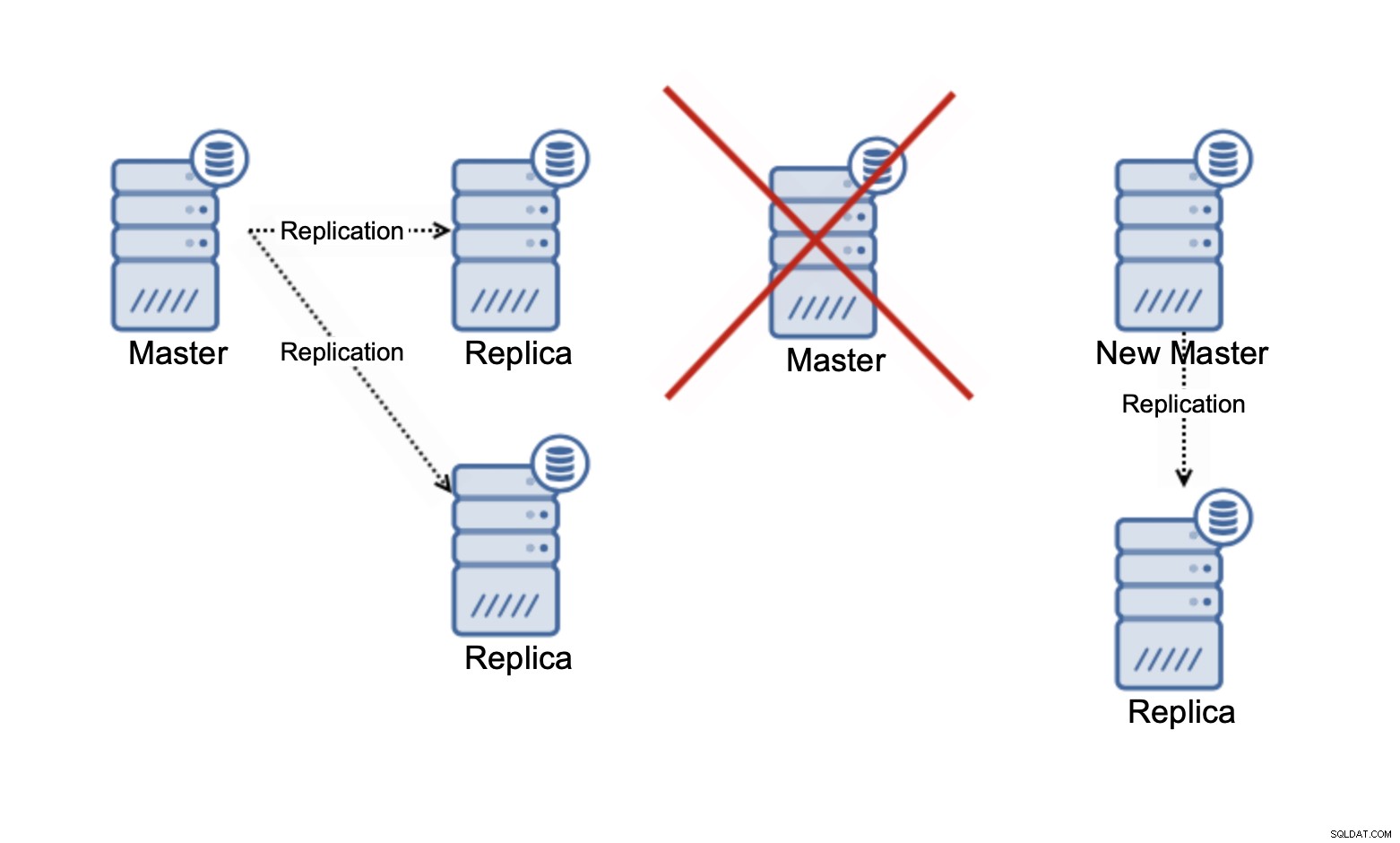
Harap diingat bahwa saat ini kita hanya berbicara tentang penskalaan pembacaan . Replikasi kapan pun tidak dapat meningkatkan kapasitas tulis Anda. Dalam replikasi asinkron, Anda hanya memiliki satu penulis (master), dan untuk replikasi sinkron, seperti Galera, di mana kumpulan data dibagikan di semua node, setiap penulisan yang terjadi pada satu node harus dilakukan pada node yang tersisa dari gugus.
Dalam kluster Galera tiga simpul, jika Anda menulis satu baris, sebenarnya Anda menulis tiga baris, satu untuk setiap simpul. Menambahkan lebih banyak node atau replika tidak akan membuat perbedaan. Alih-alih menulis baris yang sama pada tiga simpul, Anda akan menulisnya pada lima. Inilah sebabnya mengapa memisahkan penulisan Anda dalam cluster multi-master, di mana kumpulan data dibagikan di semua node (ada cluster multi-master tempat data di-shard, misalnya MySQL NDB Cluster - di sini cerita skalabilitas penulisan benar-benar berbeda), tidak terlalu masuk akal. Ini menambah overhead dalam menangani potensi konflik penulisan di semua node sementara itu tidak benar-benar mengubah apa pun terkait kapasitas tulis total.
Loadbalancing dan pemisahan baca/tulis
Kemampuan untuk memisahkan pembacaan dari penulisan adalah suatu keharusan jika Anda ingin menskalakan pembacaan Anda dalam penyiapan replikasi asinkron. Anda harus dapat mengirim lalu lintas tulis ke satu node dan kemudian mengirim bacaan ke semua node dalam topologi replikasi. Seperti yang kami sebutkan sebelumnya, fungsi ini juga cukup berguna di kluster multi-master karena memungkinkan kami untuk menghapus konflik penulisan yang mungkin terjadi jika Anda mencoba mendistribusikan penulisan ke beberapa node dalam kluster. Bagaimana kita bisa melakukan split baca/tulis? Ada beberapa cara yang bisa Anda gunakan untuk melakukannya. Mari kita bahas topik ini sebentar.
Pemisahan R/W tingkat aplikasi
Skenario paling sederhana, juga paling jarang:aplikasi Anda dapat mengonfigurasi node mana yang harus menerima penulisan dan node mana yang harus menerima pembacaan. Fungsionalitas ini dapat dikonfigurasi dalam beberapa cara, yang paling sederhana adalah daftar hardcode dari node tetapi juga bisa menjadi sesuatu di sepanjang baris inventaris node dinamis yang diperbarui oleh utas latar belakang. Masalah utama dengan pendekatan ini adalah bahwa seluruh logika harus ditulis sebagai bagian dari aplikasi. Dengan daftar node yang di-hardcode, skenario paling sederhana akan memerlukan perubahan pada kode aplikasi untuk setiap perubahan dalam topologi replikasi. Di sisi lain, solusi yang lebih canggih seperti menerapkan penemuan layanan akan lebih rumit untuk dipertahankan dalam jangka panjang.
R/W split in konektor
Opsi lain adalah menggunakan konektor untuk melakukan pemisahan baca/tulis. Tidak semua dari mereka memiliki opsi ini, tetapi beberapa memilikinya. Contohnya adalah php-mysqlnd atau Connector/J. Bagaimana itu diintegrasikan ke dalam aplikasi, mungkin berbeda berdasarkan konektor itu sendiri. Dalam beberapa kasus konfigurasi harus dilakukan dalam aplikasi, dalam beberapa kasus itu harus dilakukan dalam file konfigurasi terpisah untuk konektor. Keuntungan dari pendekatan ini adalah bahwa meskipun Anda harus memperluas aplikasi Anda, sebagian besar kode baru siap digunakan dan dikelola oleh sumber eksternal. Ini membuatnya lebih mudah untuk menangani penyiapan seperti itu dan Anda harus menulis lebih sedikit kode (jika ada).
R/W split di loadbalancer
Akhirnya, salah satu solusi terbaik:loadbalancer. Idenya sederhana - meneruskan data Anda melalui loadbalancer yang akan dapat membedakan antara membaca dan menulis dan mengirimkannya ke lokasi yang tepat. Ini adalah peningkatan besar dari sudut pandang kegunaan karena kami dapat memisahkan penemuan basis data dan perutean kueri dari aplikasi. Satu-satunya hal yang harus dilakukan aplikasi adalah mengirim lalu lintas basis data ke satu titik akhir yang terdiri dari nama host dan port. Sisanya terjadi di latar belakang. Loadbalancer bekerja untuk merutekan kueri ke node database backend. Loadbalancer juga dapat melakukan penemuan topologi replikasi atau Anda dapat menerapkan inventaris layanan yang tepat menggunakan etcd atau consul dan memperbaruinya melalui alat orkestrasi infrastruktur Anda seperti Ansible.
Ini mengakhiri bagian pertama dari blog ini. Di bagian kedua kita akan membahas tantangan yang kita hadapi saat menskalakan tingkat basis data. Kami juga akan membahas beberapa cara untuk memperluas klaster basis data kami.