Di blog sebelumnya, kita telah membahas cara memigrasikan pengaturan Moodle yang berdiri sendiri ke pengaturan yang dapat diskalakan berdasarkan database yang dikelompokkan. Langkah selanjutnya yang perlu Anda pikirkan adalah mekanisme failover - apa yang Anda lakukan jika dan ketika layanan database Anda mati.
Server database yang gagal bukanlah hal yang aneh jika Anda memiliki MySQL Replication sebagai database Moodle backend Anda, dan jika itu terjadi, Anda perlu menemukan cara untuk memulihkan topologi Anda dengan misalnya mempromosikan server siaga ke menjadi server utama baru. Memiliki failover otomatis untuk database MySQL Moodle Anda membantu waktu kerja aplikasi. Kami akan menjelaskan cara kerja mekanisme failover, dan cara membuat failover otomatis ke dalam penyiapan Anda.
Arsitektur Ketersediaan Tinggi untuk Database MySQL
Arsitektur ketersediaan tinggi dapat dicapai dengan mengelompokkan database MySQL Anda dalam beberapa cara berbeda. Anda dapat menggunakan Replikasi MySQL, menyiapkan beberapa replika yang mengikuti database utama Anda. Selain itu, Anda dapat menempatkan penyeimbang beban basis data untuk membagi lalu lintas baca/tulis, dan mendistribusikan lalu lintas ke node baca-tulis dan read-only. Arsitektur database high availability menggunakan MySQL Replication dapat digambarkan sebagai berikut :
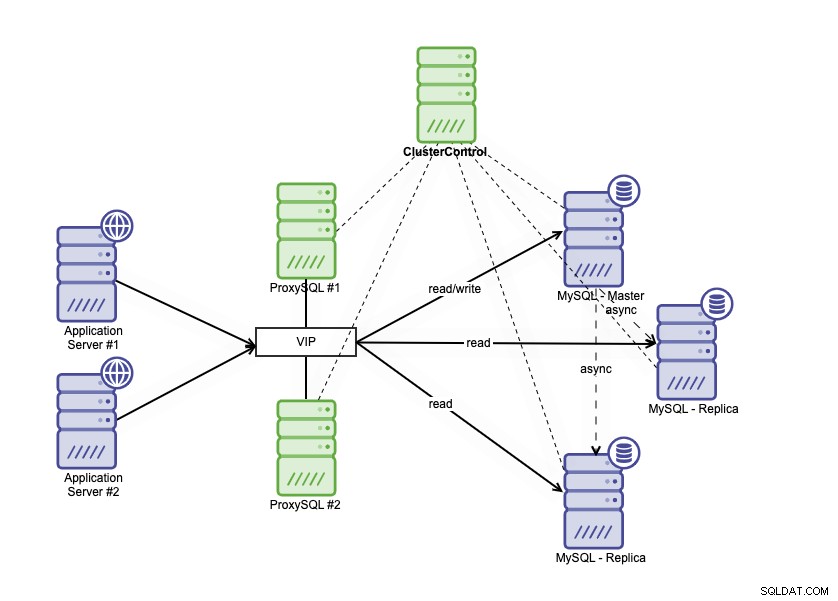
Terdiri dari satu basis data utama, dua replika basis data, dan penyeimbang beban basis data (di blog ini, kami menggunakan ProxySQL sebagai penyeimbang beban basis data), dan keepalive sebagai layanan untuk memantau proses ProxySQL. Kami menggunakan Virtual IP Address sebagai koneksi tunggal dari aplikasi. Lalu lintas akan didistribusikan ke penyeimbang beban aktif berdasarkan flag peran di keepalive.
ProxySQL mampu menganalisis lalu lintas dan memahami apakah permintaan adalah membaca atau menulis. Ini kemudian akan meneruskan permintaan ke host yang sesuai.
Kegagalan pada Replikasi MySQL
Replikasi MySQL menggunakan pencatatan log biner untuk mereplikasi data dari primer ke replika. Replika terhubung ke node utama, dan setiap perubahan direplikasi dan ditulis ke log relai node replika melalui IO_THREAD. Setelah perubahan disimpan dalam log relai, proses SQL_THREAD akan dilanjutkan dengan menerapkan data ke dalam database replika.
Setelan default untuk parameter read_only dalam replika adalah ON. Ini digunakan untuk melindungi replika itu sendiri dari penulisan langsung apa pun, sehingga perubahan akan selalu berasal dari database utama. Ini penting karena kami tidak ingin replika menyimpang dari server utama. Skenario failover dalam Replikasi MySQL terjadi ketika yang utama tidak dapat dijangkau. Ada banyak alasan untuk ini; mis., server mogok atau masalah jaringan.
Anda perlu mempromosikan salah satu replika ke primer, menonaktifkan parameter hanya-baca pada replika yang dipromosikan agar dapat ditulis. Anda juga perlu mengubah replika lain untuk terhubung ke primer baru. Dalam mode GTID, Anda tidak perlu mencatat nama dan posisi log biner dari mana untuk melanjutkan replikasi. Namun, dalam replikasi berbasis binlog tradisional, Anda pasti perlu mengetahui nama dan posisi log biner terakhir untuk melanjutkan. Failover dalam replikasi berbasis binlog adalah proses yang cukup kompleks, tetapi bahkan failover dalam replikasi berbasis GTID juga tidak sepele karena Anda perlu melihat hal-hal seperti transaksi yang salah. Mendeteksi kegagalan adalah satu hal, dan kemudian bereaksi terhadap kegagalan dalam penundaan singkat mungkin tidak mungkin tanpa otomatisasi.
Bagaimana ClusterControl Mengaktifkan Failover Otomatis
ClusterControl memiliki kemampuan untuk melakukan failover otomatis untuk database MySQL Moodle Anda. Terdapat fitur Automatic Recovery for Cluster and Node yang akan memicu proses failover ketika database primary crash.
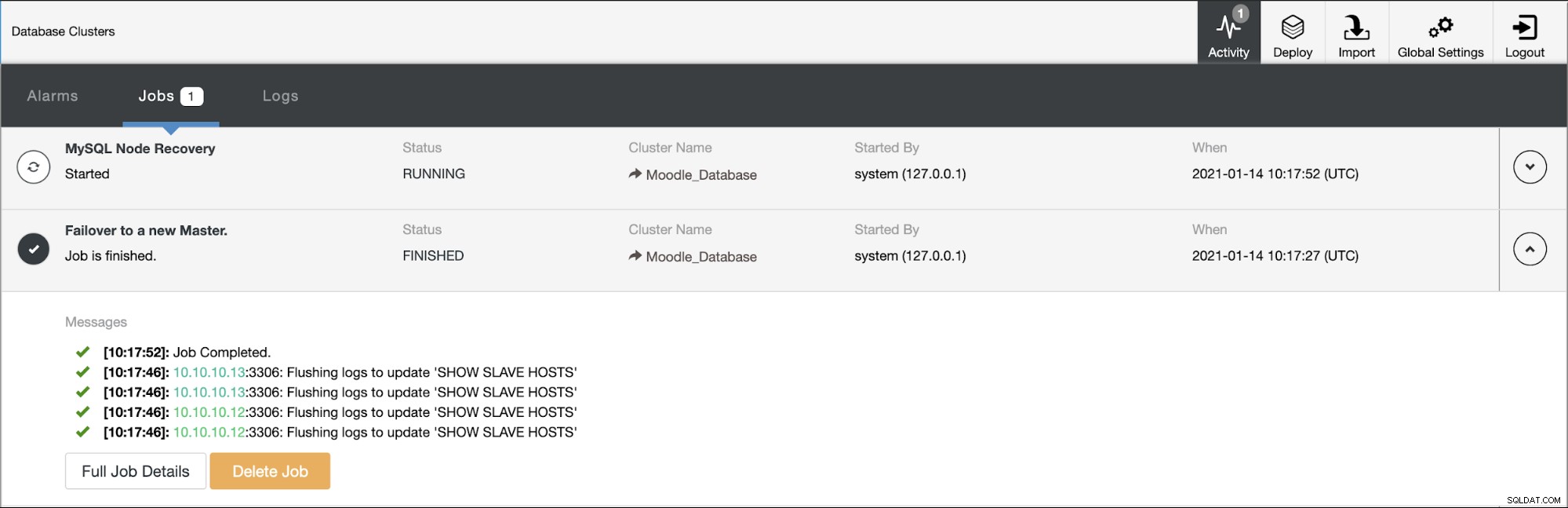
Kami akan mensimulasikan bagaimana Automatic Failover terjadi di ClusterControl. Kita akan membuat database primer crash, dan lihat saja di dashboard ClusterControl. Di bawah ini adalah Topologi cluster saat ini :
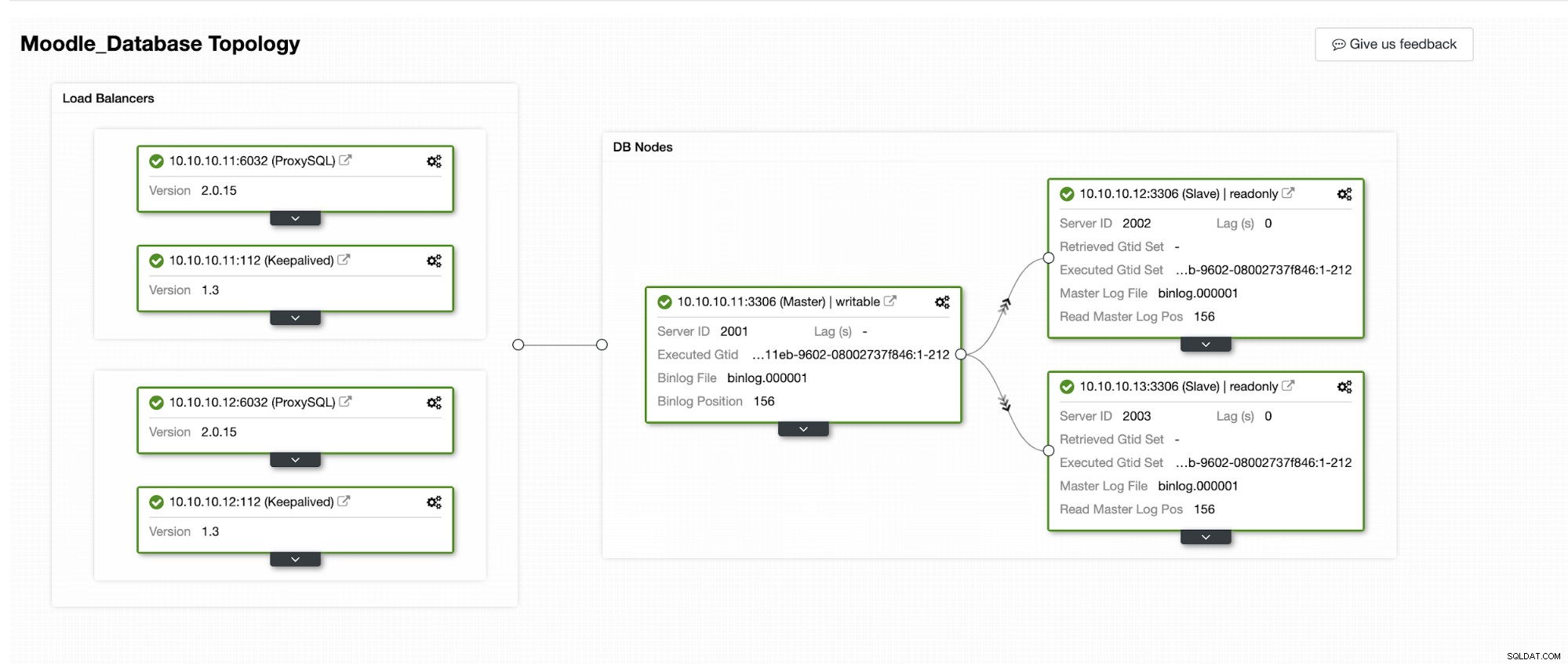
Basis data utama menggunakan Alamat IP 10.10.10.11 dan replikanya adalah :10.10.10.12 dan 10.10.10.13. Ketika crash terjadi pada primary, ClusterControl memicu peringatan dan failover dimulai seperti yang ditunjukkan pada gambar di bawah ini:
Salah satu replika akan dipromosikan menjadi primer, menghasilkan Topologi sebagai pada gambar di bawah ini:
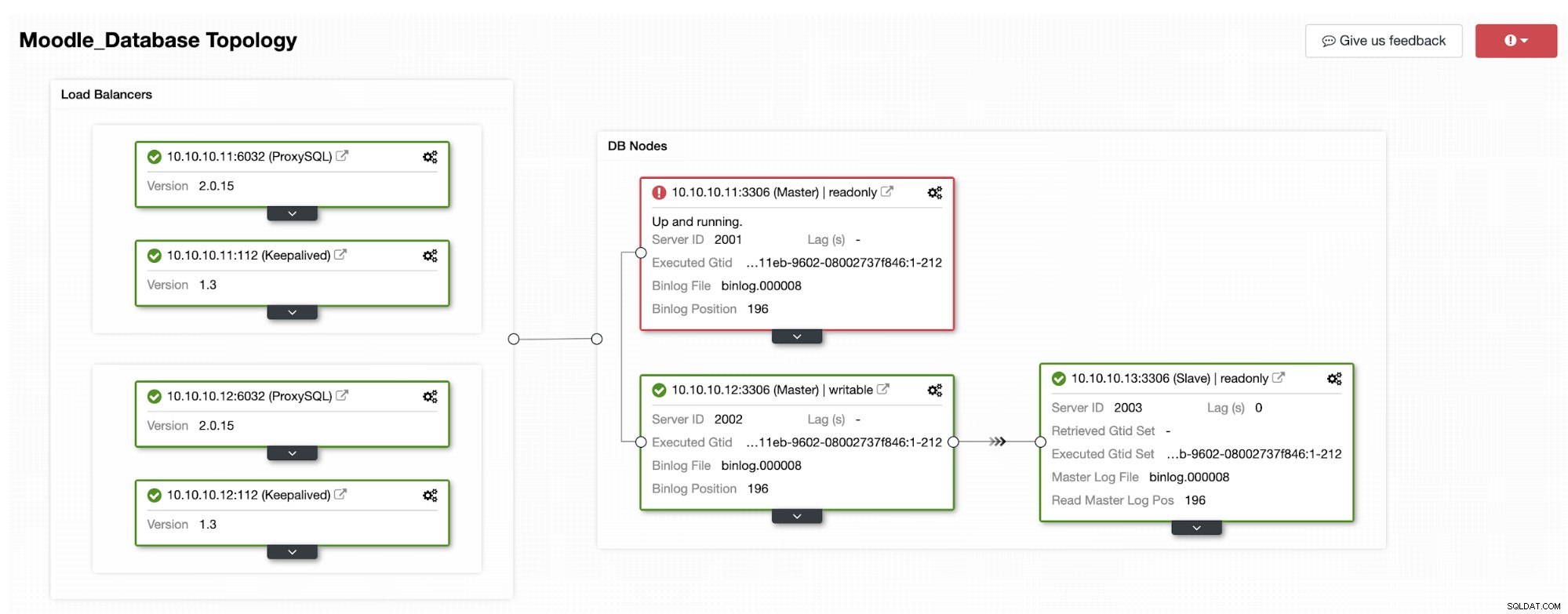
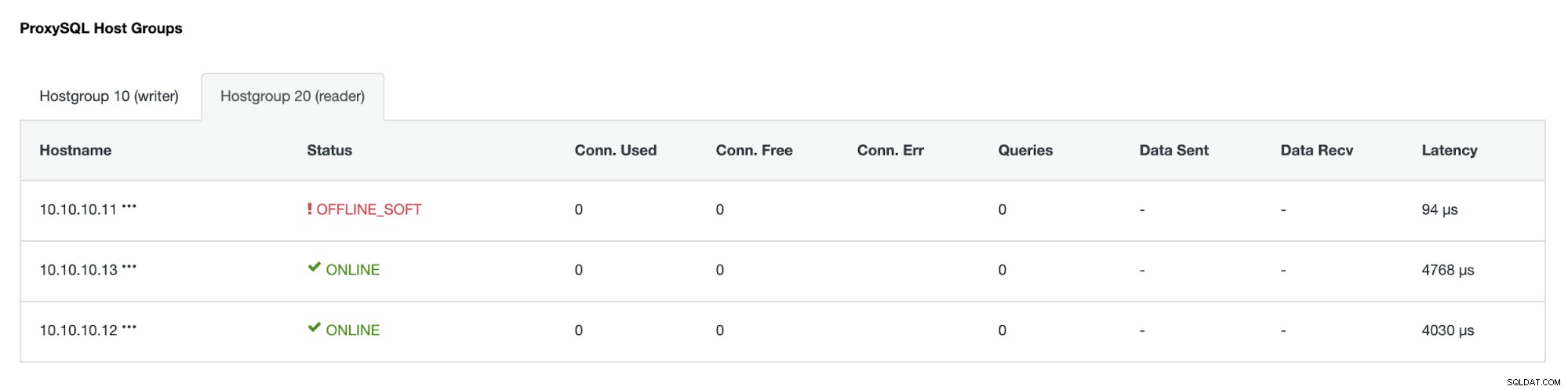
Alamat IP 10.10.10.12 sekarang melayani lalu lintas tulis sebagai utama, dan juga kita hanya memiliki satu replika yang memiliki alamat IP 10.10.10.13. Di sisi ProxySQL, proxy akan mendeteksi primer baru secara otomatis. Hostgroup (HG10) masih melayani lalu lintas tulis yang memiliki anggota 10.10.10.12 seperti gambar di bawah ini:

Hostgroup (HG20) masih dapat melayani lalu lintas baca, tetapi seperti yang Anda lihat node 10.10.10.11 offline karena crash :
Setelah server utama yang gagal kembali online, server tidak akan otomatis kembali -diperkenalkan dalam topologi database. Ini untuk menghindari hilangnya informasi pemecahan masalah, karena memperkenalkan kembali node sebagai replika mungkin memerlukan penimpaan beberapa log atau informasi lainnya. Tetapi dimungkinkan untuk mengonfigurasi auto-rejoin dari node yang gagal.