Pemantauan adalah salah satu tugas mendasar dalam sistem apa pun. Ini dapat membantu kami mendeteksi masalah dan mengambil tindakan, atau sekadar mengetahui status sistem kami saat ini. Menggunakan tampilan visual dapat membuat kita lebih efektif karena kita dapat lebih mudah mendeteksi masalah kinerja.
Di blog ini, kita akan melihat cara menggunakan SCUMM untuk memantau database PostgreSQL kita dan metrik apa yang dapat kita gunakan untuk tugas ini. Kami juga akan memeriksa dasbor yang tersedia, sehingga Anda dapat dengan mudah mengetahui apa yang sebenarnya terjadi dengan instance PostgreSQL Anda.
Apa itu SCUMM?
Pertama-tama, mari kita lihat apa itu SCUMM (Severalnines ClusterControl Unified Monitoring and Management ).
Ini adalah solusi berbasis agen baru dengan agen yang diinstal pada node database.
Agen SCUMM adalah eksportir Prometheus yang mengekspor metrik dari layanan seperti PostgreSQL sebagai metrik Prometheus.
Server Prometheus digunakan untuk mengikis dan menyimpan data deret waktu dari Agen SCUMM.
Prometheus adalah perangkat pemantauan dan peringatan sistem sumber terbuka yang awalnya dibuat di SoundCloud. Sekarang merupakan proyek open source mandiri dan dikelola secara independen.
Prometheus dirancang untuk keandalan, menjadi sistem yang Anda gunakan selama pemadaman listrik untuk memungkinkan Anda mendiagnosis masalah dengan cepat.
Bagaimana cara menggunakan SCUMM?
Saat menggunakan ClusterControl, ketika kita memilih sebuah cluster, kita dapat melihat gambaran umum dari database kita, serta beberapa metrik dasar yang dapat digunakan untuk mengidentifikasi masalah. Pada dashboard di bawah ini, kita dapat melihat setup master-slave dengan satu master dan 2 slave, dengan HAProxy dan Keepalive.
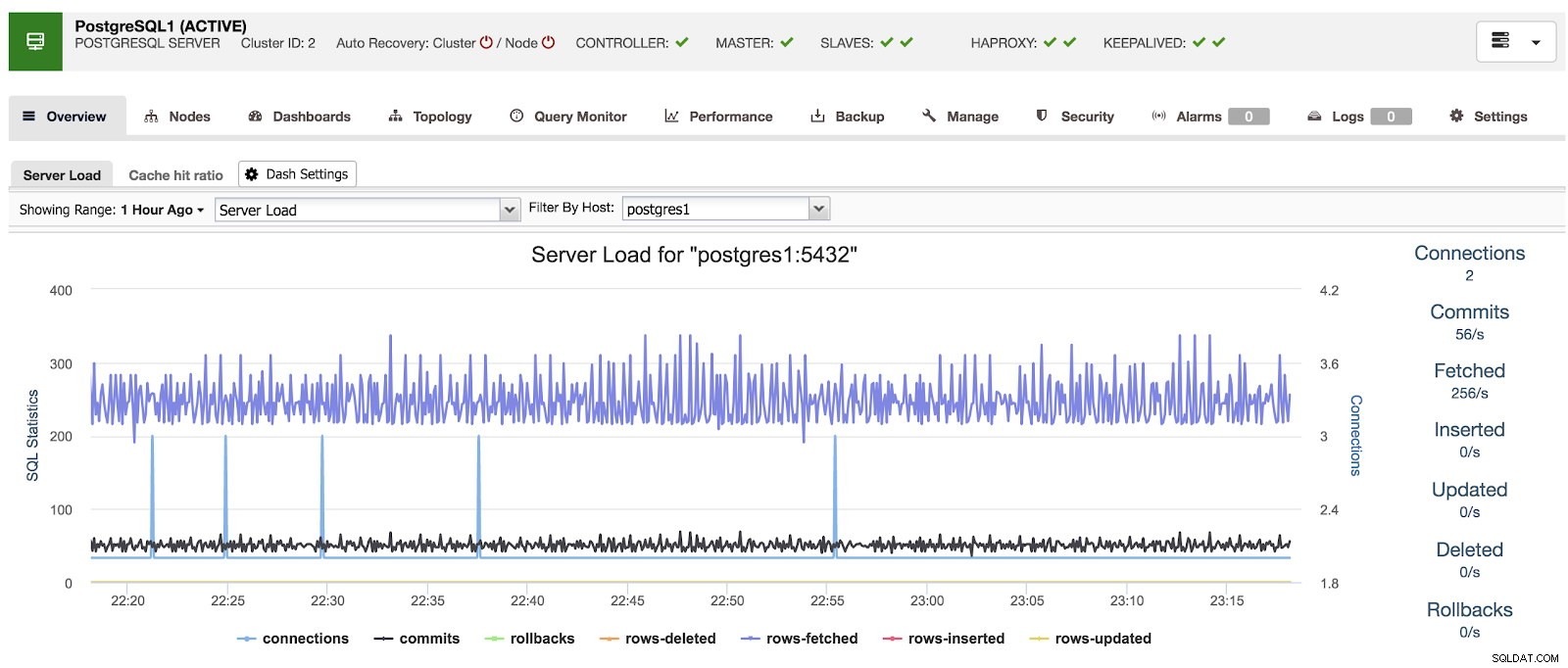 Ikhtisar Kontrol Cluster
Ikhtisar Kontrol Cluster Jika kita masuk ke opsi “Dasbor”, kita dapat melihat pesan seperti berikut.
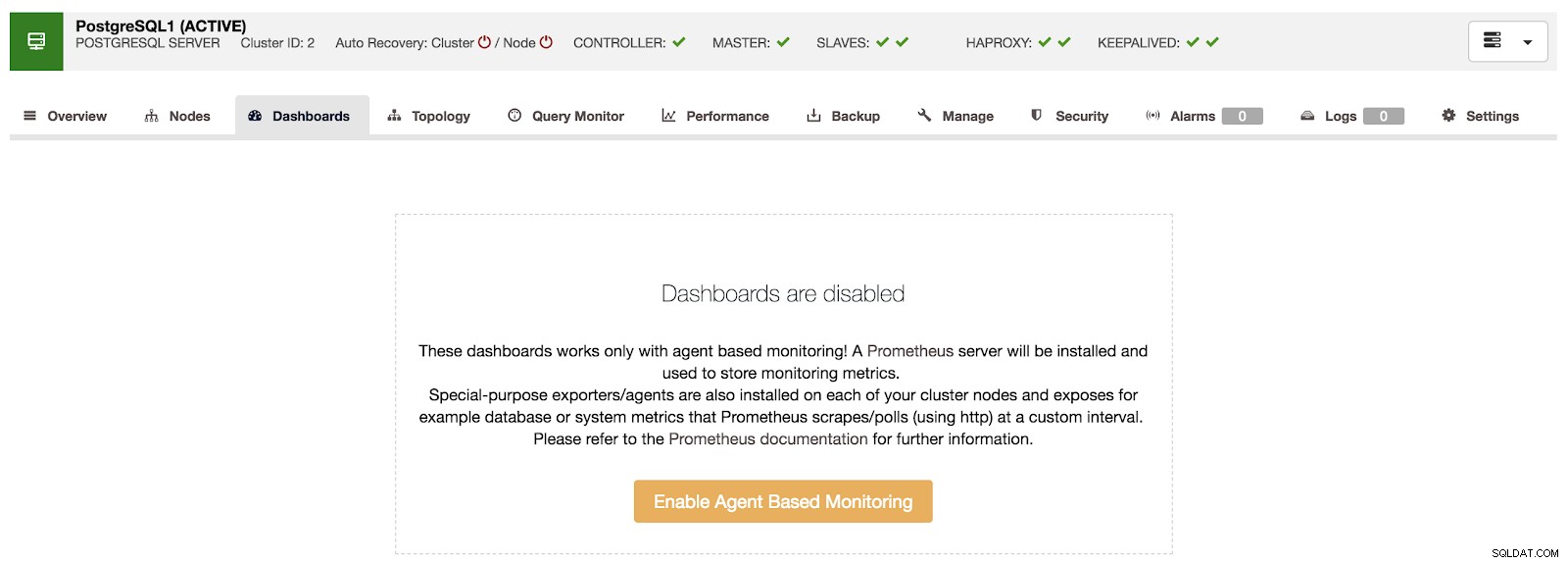 Dasbor Kontrol Cluster Dinonaktifkan
Dasbor Kontrol Cluster Dinonaktifkan Untuk menggunakan fitur ini, kita harus mengaktifkan agen yang disebutkan di atas. Untuk ini, kita hanya perlu menekan tombol "Aktifkan Pemantauan Berbasis Agen" di bagian ini.
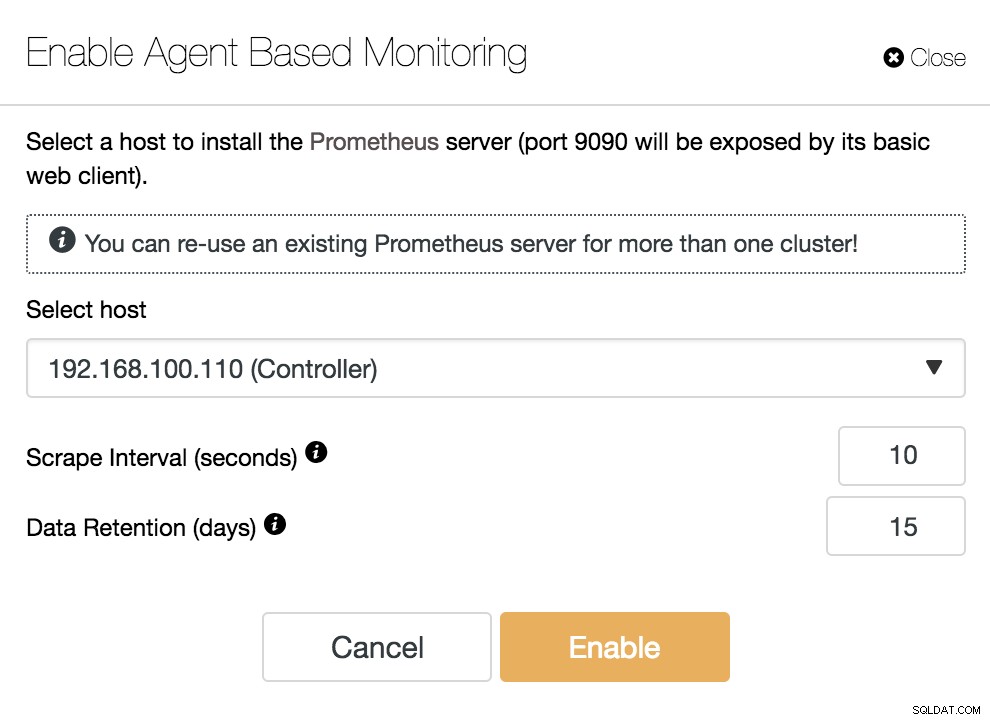 ClusterControl Aktifkan Pemantauan Berbasis Agen
ClusterControl Aktifkan Pemantauan Berbasis Agen Untuk mengaktifkan agen kami, kami harus menentukan host tempat kami akan menginstal server Prometheus kami, yang, seperti yang dapat kita lihat dalam contoh, dapat menjadi server ClusterControl kami.
Kami juga harus menentukan:
- Interval Pengikisan (detik):Setel seberapa sering simpul digores untuk metrik. Standarnya adalah 10 detik.
- Retensi Data (hari):Setel berapa lama metrik disimpan sebelum dihapus. Standarnya adalah 15 hari.
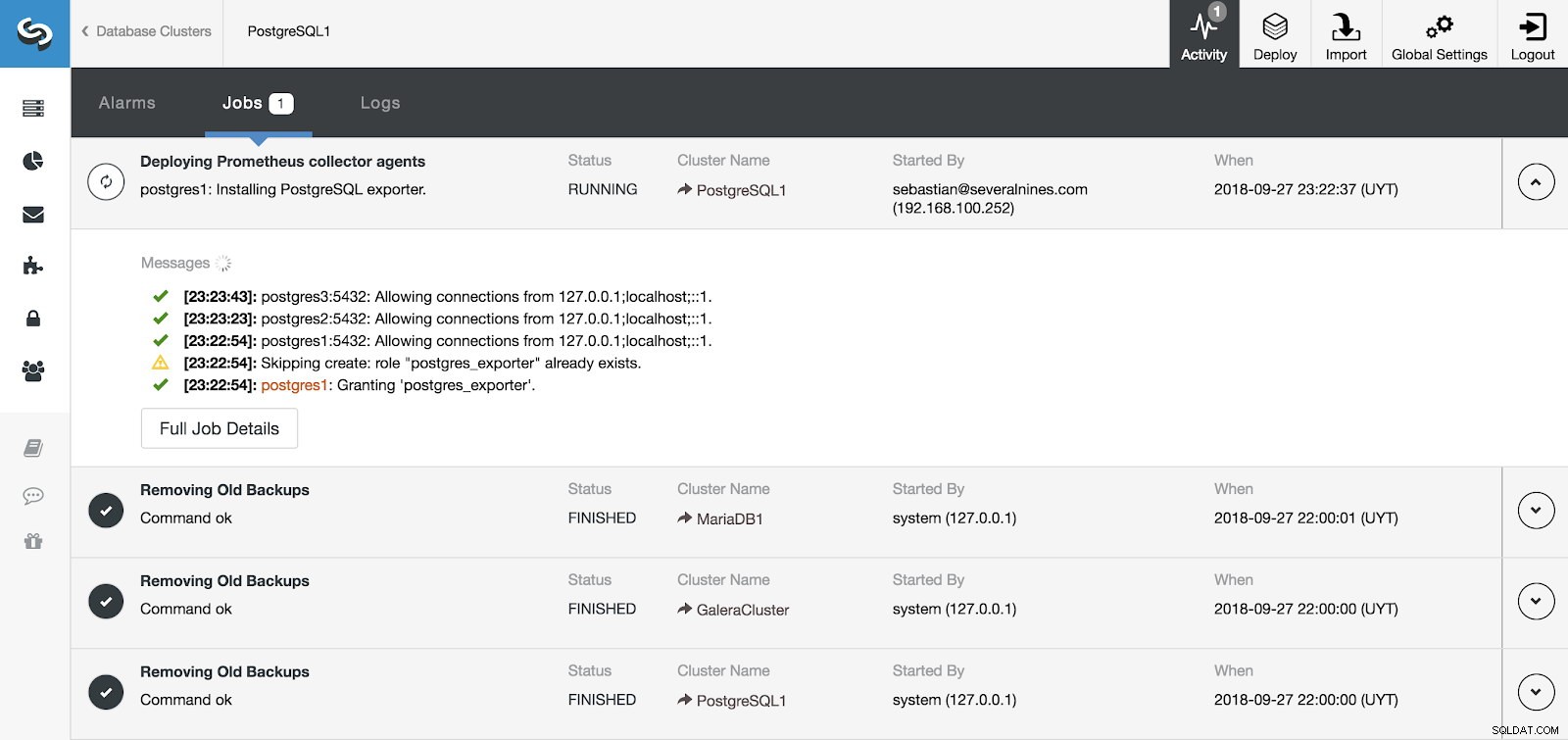 Bagian Aktivitas Kontrol Cluster
Bagian Aktivitas Kontrol Cluster Kami dapat memantau instalasi server dan agen kami dari bagian Aktivitas di ClusterControl dan, setelah selesai, kami dapat melihat cluster kami dengan agen diaktifkan dari layar ClusterControl utama.
 Agen Kontrol Cluster Diaktifkan
Agen Kontrol Cluster Diaktifkan Dasbor
Setelah agen kami diaktifkan, jika kami pergi ke bagian Dasbor, kami akan melihat sesuatu seperti ini:
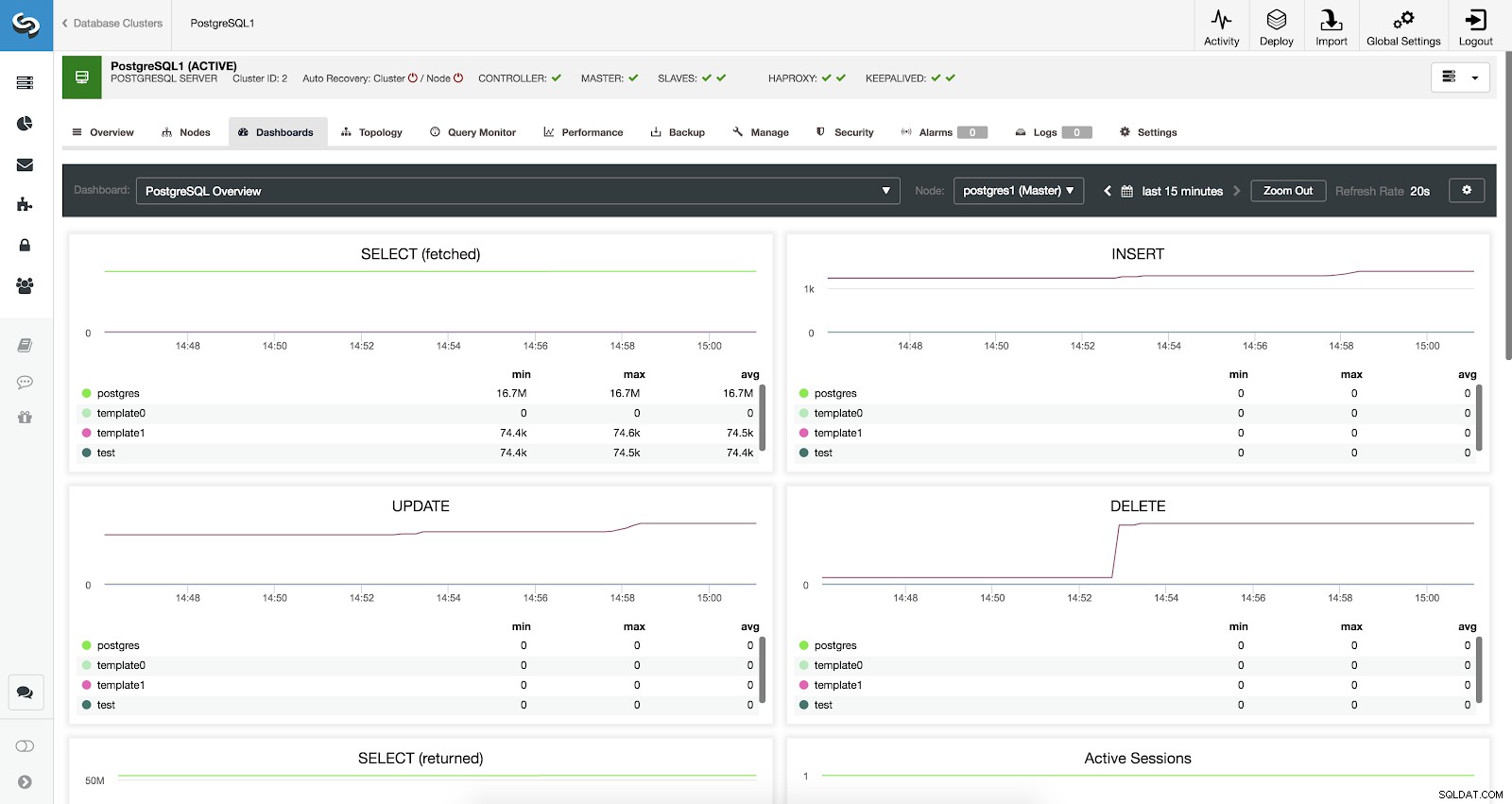 Dasbor Kontrol Cluster Diaktifkan
Dasbor Kontrol Cluster Diaktifkan Kami memiliki tiga jenis dasbor yang tersedia, Tinjauan Sistem, Grafik Lintas Server, dan Tinjauan PostgreSQL. Yang terakhir adalah apa yang kita lihat secara default saat memasuki bagian ini.
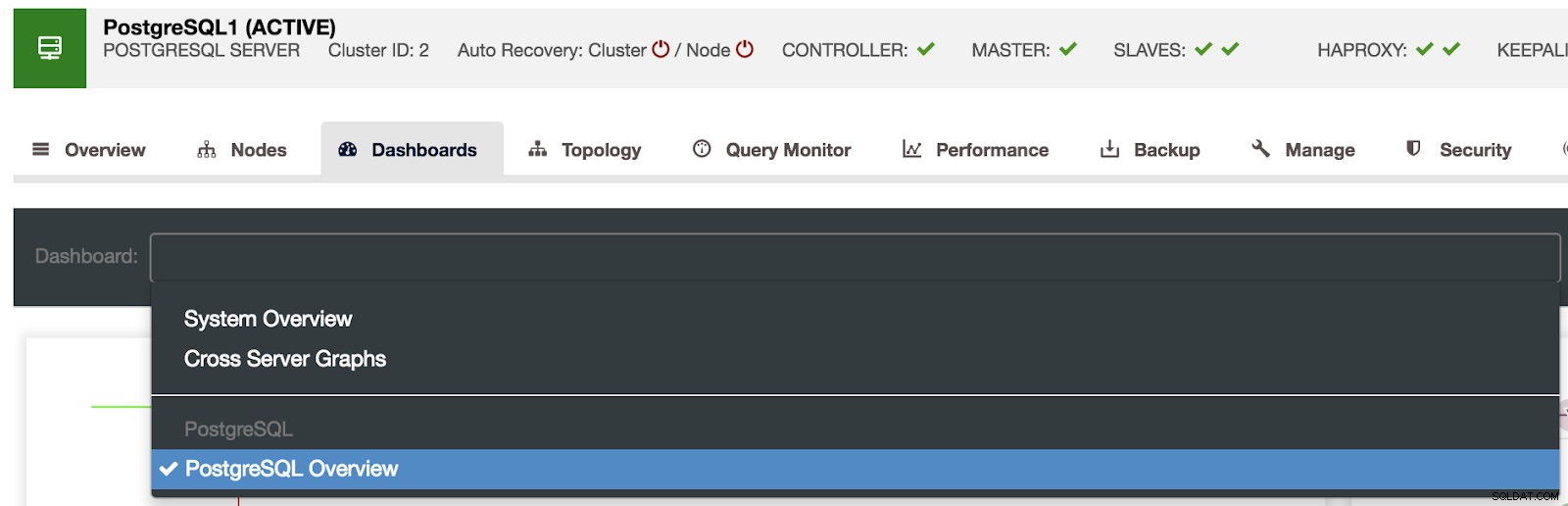 Pilihan Dasbor Kontrol Cluster
Pilihan Dasbor Kontrol Cluster Di sini kita juga dapat menentukan node mana yang akan dipantau, rentang waktu, dan kecepatan refresh.
 Opsi Dasbor Kontrol Cluster
Opsi Dasbor Kontrol Cluster Di bagian konfigurasi, kami dapat mengaktifkan atau menonaktifkan agen kami (Eksportir), memeriksa status agen dan memverifikasi versi server Prometheus kami.
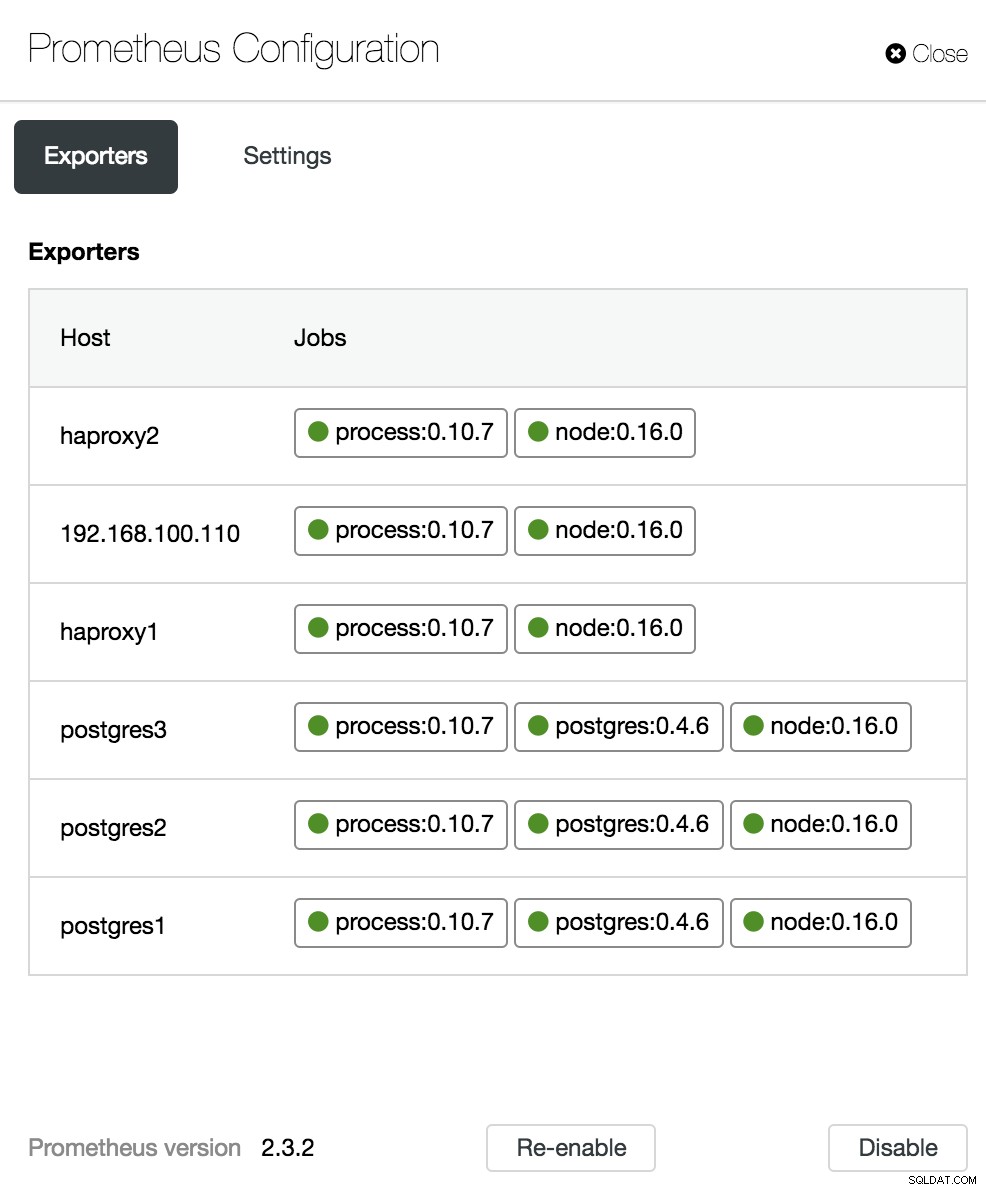 Konfigurasi Dasbor Kontrol Cluster
Konfigurasi Dasbor Kontrol Cluster Metrik Ikhtisar PostgreSQL
Sekarang mari kita lihat metrik apa yang tersedia untuk setiap database PostgreSQL kita (semuanya untuk node yang dipilih).
- PILIH (diambil):Jumlah baris yang dipilih (diambil) untuk setiap database. Baris yang diambil mengacu pada baris langsung yang diambil dari tabel.
- PILIH (dikembalikan):Jumlah baris yang dipilih (dikembalikan) untuk setiap database. Baris yang dikembalikan merujuk ke semua baris yang dibaca dari tabel, yang mencakup baris mati dan baris yang belum--belum dikomit (berbeda dengan baris yang diambil yang hanya menghitung tupel aktif).
- INSERT:Jumlah baris yang disisipkan untuk setiap database.
- PERBARUI:Jumlah baris yang diperbarui untuk setiap basis data.
- HAPUS:Jumlah baris yang dihapus untuk setiap database.
- Sesi Aktif:Jumlah sesi aktif (min, maks, dan rata-rata) untuk setiap database.
- Sesi Idle:Jumlah sesi idle (min, maks, dan rata-rata) untuk setiap database.
- Tabel Kunci:Jumlah kunci (min, maks, dan rata-rata) yang dipisahkan menurut jenis untuk setiap database.
- Utilisasi IO Disk:Penggunaan IO disk server.
- Penggunaan Disk:Persentase penggunaan disk server (min, maks, dan rata-rata).
- Latensi Disk:Latensi disk server.
ClusterControl PostgreSQL Ikhtisar Metrik Metrik Ikhtisar Sistem
Untuk memantau sistem kami, kami telah menyediakan metrik berikut untuk setiap server (semuanya untuk node yang dipilih):
- Waktu Operasi Sistem:Waktu sejak server aktif.
- CPU:Jumlah CPU.
- RAM:Jumlah memori RAM.
- Memori Tersedia:Persentase memori RAM yang tersedia.
- Rata-rata Beban:Beban server minimum, maks, dan rata-rata.
- Memori:Memori server yang tersedia, total, dan terpakai.
- Penggunaan CPU:Informasi penggunaan CPU server minimum, maks, dan rata-rata.
- Distribusi Memori:Distribusi memori (buffer, cache, gratis dan bekas) pada node yang dipilih.
- Metrik Saturasi:Minimum, maks, dan rata-rata beban IO dan beban CPU pada node yang dipilih.
- Detail Lanjutan Memori:Detail penggunaan memori seperti halaman, buffer, dan lainnya, pada node yang dipilih.
- Fork:Jumlah proses fork. Fork adalah operasi di mana suatu proses membuat salinan dirinya sendiri. Biasanya panggilan sistem, diimplementasikan di kernel.
- Proses:Jumlah proses yang berjalan atau menunggu di Sistem Operasi.
- Sakelar Konteks:Sakelar konteks adalah tindakan menyimpan status proses atau utas.
- Interupsi:Jumlah interupsi. Interupsi adalah peristiwa yang mengubah aliran eksekusi normal suatu program dan dapat dihasilkan oleh perangkat keras atau bahkan oleh CPU itu sendiri.
- Lalu Lintas Jaringan:Lalu lintas jaringan masuk dan keluar dalam KBytes per detik pada node yang dipilih.
- Utilisasi Jaringan Setiap Jam:Lalu lintas dikirim dan diterima di hari terakhir.
- Tukar:Tukar penggunaan (gratis dan bekas) pada node yang dipilih.
- Aktivitas Tukar:Membaca dan menulis data di swap.
- Aktivitas I/O:Halaman masuk dan halaman keluar di IO.
- Deskriptor File:Descriptor file yang dialokasikan dan dibatasi.
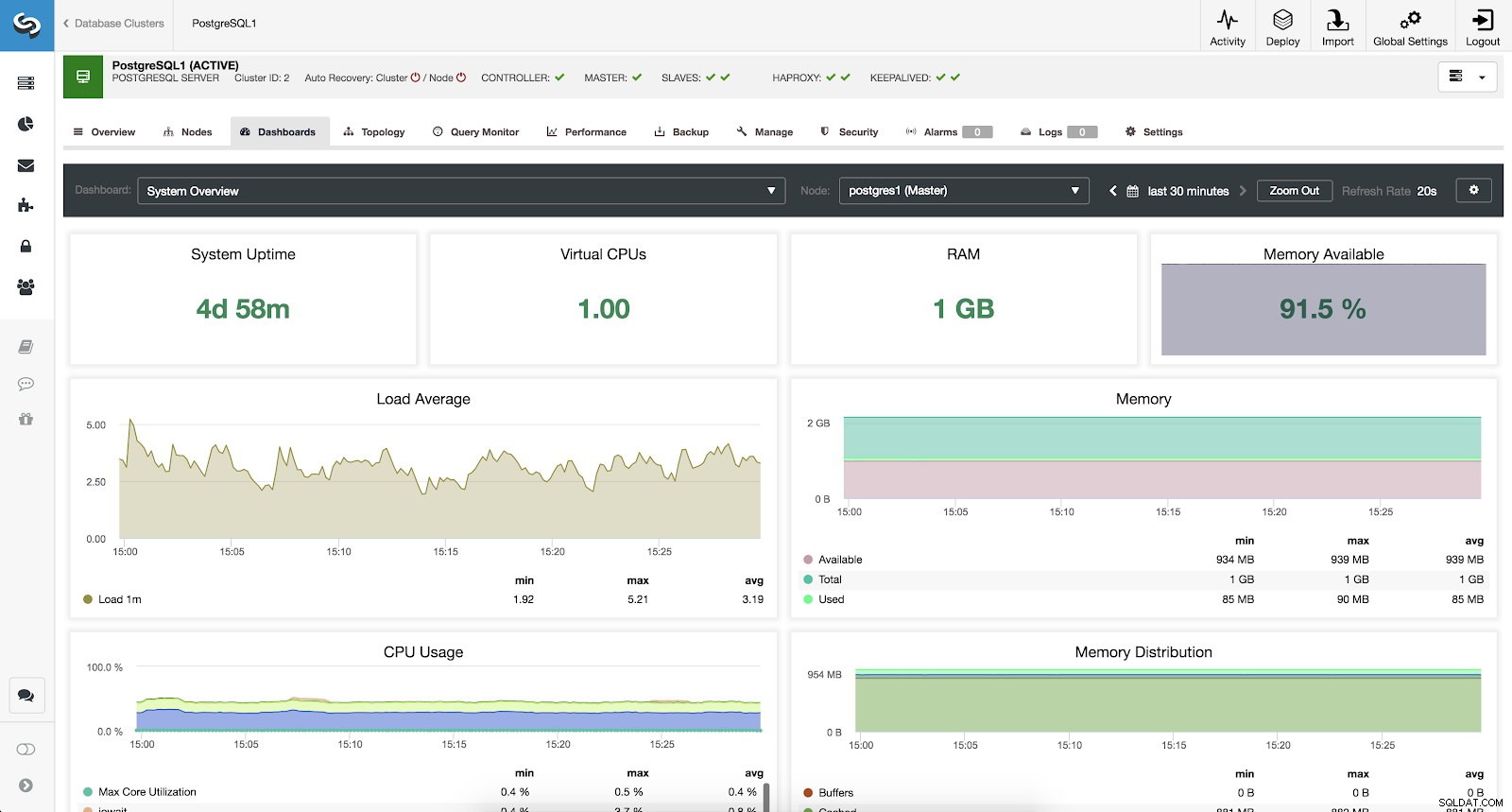 Metrik Tinjauan Sistem Kontrol Cluster
Metrik Tinjauan Sistem Kontrol Cluster Metrik Grafik Lintas Server
Jika kami ingin melihat keadaan umum semua server kami, kami dapat menggunakan dasbor ini dengan metrik berikut:
- Rata-rata Beban:Server memuat rata-rata untuk setiap server.
- Penggunaan Memori:Persentase penggunaan memori untuk setiap server.
- Lalu Lintas Jaringan:Min, maks, dan rata-rata kBytes lalu lintas jaringan per detik.
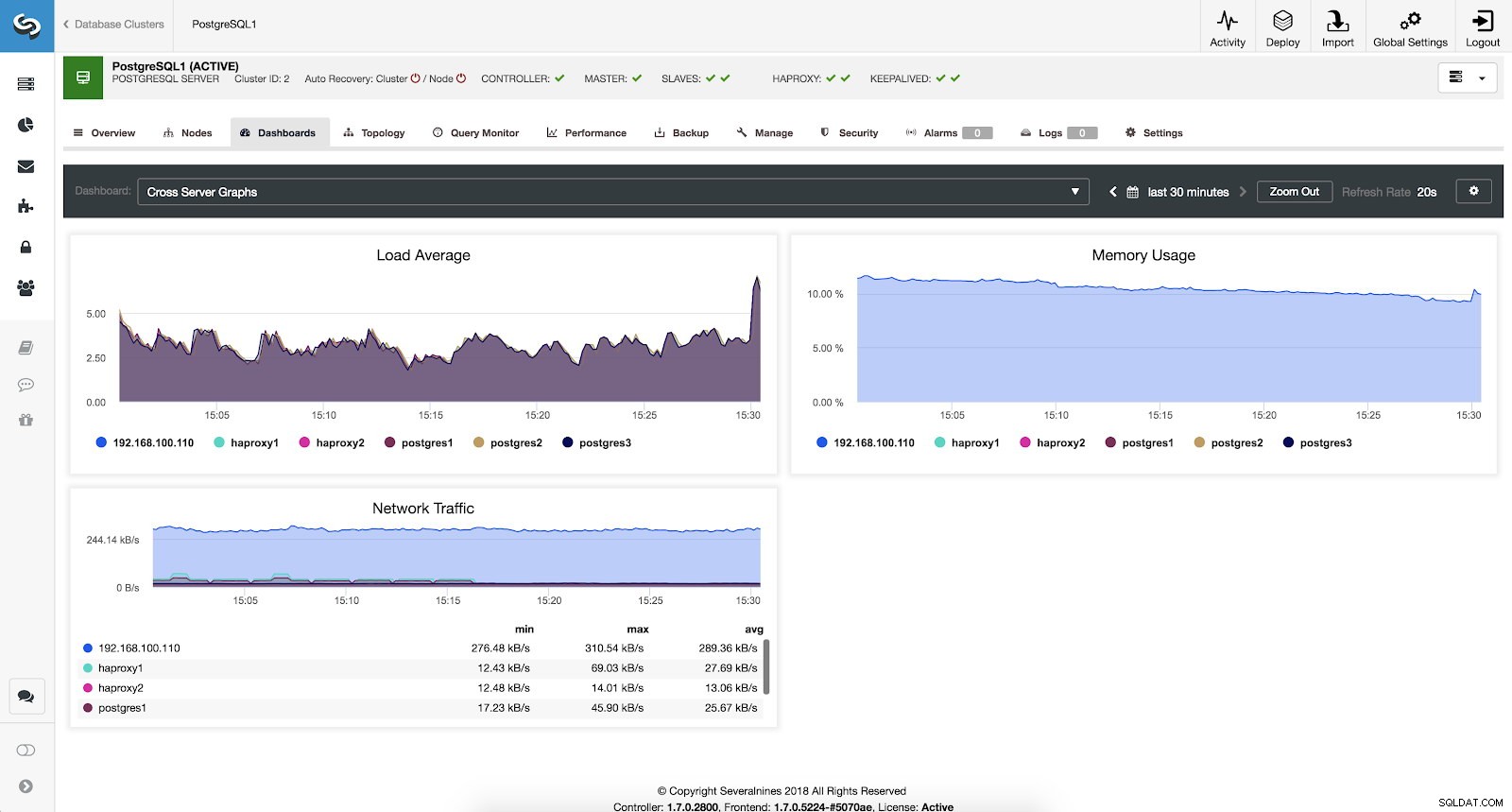 Metrik Grafik Lintas Server Kontrol Cluster
Metrik Grafik Lintas Server Kontrol Cluster Kesimpulan
Ada beberapa cara untuk memantau PostgreSQL. ClusterControl menyediakan pemantauan tanpa agen dan sekarang berbasis agen melalui Prometheus. Ini menyediakan data pemantauan resolusi lebih tinggi, serta dasbor yang berbeda untuk memahami kinerja basis data. ClusterControl juga dapat diintegrasikan dengan alat eksternal seperti Slack atau PagerDuty untuk peringatan.