Mempertimbangkan kasus penggunaan utama database saat ini untuk mengambil data, menjadi sangat penting bahwa kinerjanya sangat tinggi dan hanya dapat dicapai jika data diambil dengan cara yang paling efisien dari penyimpanan. Ada banyak penemuan dan implementasi yang berhasil dilakukan untuk mencapai hal yang sama. Salah satu pendekatan terkenal yang diadopsi oleh sebagian besar database adalah memiliki indeks di atas meja.
Apa itu Indeks Basis Data?
Database Index, seperti namanya, memelihara indeks ke data aktual dan dengan demikian meningkatkan kinerja untuk mengambil data dari tabel aktual. Dalam terminologi basis data yang lebih, indeks memungkinkan pengambilan halaman yang berisi data yang diindeks dalam traversal yang sangat minimal karena data diurutkan dalam urutan tertentu. Manfaat indeks datang dengan biaya ruang penyimpanan tambahan untuk menulis data tambahan. Indeks khusus untuk tabel yang mendasarinya dan terdiri dari satu atau lebih kunci (yaitu satu atau lebih kolom dari tabel yang ditentukan). Terutama ada dua jenis arsitektur indeks
- Indeks Berkelompok – Data indeks disimpan bersama dengan bagian lain dari data dan data diurutkan berdasarkan kunci indeks. Paling banyak hanya ada satu indeks dalam kategori ini untuk tabel tertentu.
- Indeks Non-Clustered – Data indeks disimpan secara terpisah dan memiliki penunjuk ke penyimpanan tempat bagian lain dari data disimpan. Ini juga dikenal sebagai indeks sekunder. Jumlah indeks kategori ini bisa sebanyak yang Anda inginkan pada tabel tertentu.
Ada berbagai struktur data yang digunakan untuk mengimplementasikan indeks, beberapa yang secara luas diadopsi oleh mayoritas basis data adalah B-Tree dan Hash.
Apa itu Indeks PostgreSQL?
PostgreSQL hanya mendukung indeks non-cluster. Itu berarti data indeks dan data lengkap (selanjutnya disebut sebagai data tumpukan ) disimpan di tempat penyimpanan tersendiri. Indeks non-cluster seperti "Daftar Isi" dalam dokumen apa pun, di mana pertama-tama kami memeriksa nomor halaman dan kemudian memeriksa nomor halaman tersebut untuk membaca seluruh konten. Untuk mendapatkan data lengkap berdasarkan indeks, ia mempertahankan pointer ke data tumpukan yang sesuai. Sama halnya setelah mengetahui nomor halaman, ia harus pergi ke halaman tersebut dan mendapatkan isi halaman yang sebenarnya.
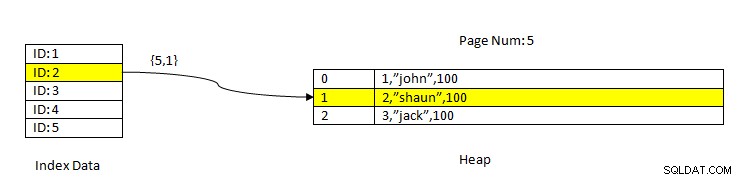 PostgreSQL:Data dibaca menggunakan Indeks
PostgreSQL:Data dibaca menggunakan Indeks Misalnya, pertimbangkan tabel dengan tiga kolom dan indeks pada kolom ID . Untuk MEMBACA data berdasarkan ID kunci=2, terlebih dahulu dicari data yang diindeks dengan nilai ID 2. Ini berisi pointer (disebut sebagai Pointer Item) dalam hal nomor halaman (yaitu nomor blok) dan offset data dalam halaman itu. Dalam contoh saat ini, indeks menunjuk ke halaman nomor 5 dan item baris kedua di halaman yang pada gilirannya menjaga offset ke seluruh data(2,"Shaun",100). Perhatikan seluruh data juga berisi data yang diindeks yang berarti data yang sama diulang dalam dua penyimpanan.
Bagaimana INDEX membantu meningkatkan kinerja? Nah, untuk memilih catatan INDEX apa pun, itu tidak memindai semua halaman secara berurutan, melainkan hanya perlu memindai sebagian halaman menggunakan struktur data Indeks yang mendasarinya. Tapi ada twist, karena setiap record yang ditemukan dari data Index, perlu melihat data Heap untuk keseluruhan data, yang menyebabkan banyak I/O acak dan dianggap berkinerja lebih lambat daripada I/O Sequential. Jadi hanya jika sebagian kecil catatan dipilih (yang diputuskan berdasarkan Biaya pengoptimal PostgreSQL), maka hanya PostgreSQL yang memilih Pemindaian Indeks jika tidak, meskipun ada indeks di tabel, PostgreSQL terus menggunakan Pemindaian Urutan.
Singkatnya, meskipun pembuatan Indeks mempercepat kinerja, itu harus dipilih dengan cermat karena memiliki overhead dalam hal penyimpanan, menurunkan kinerja INSERT.
Sekarang kita mungkin bertanya-tanya, jika kita hanya membutuhkan bagian indeks data, dapatkah kita mengambil hanya dari halaman penyimpanan indeks? Nah, jawabannya terkait langsung dengan cara kerja MVCC pada penyimpanan indeks seperti yang akan dijelaskan selanjutnya.
Menggunakan MVCC untuk Pengindeksan
Seperti halaman Heap, halaman indeks mempertahankan beberapa versi tupel indeks tetapi tidak mempertahankan informasi visibilitas. Seperti yang dijelaskan di MVCC saya sebelumnya blog, untuk memutuskan versi tupel yang terlihat sesuai, diperlukan transaksi yang membandingkan. Transaksi yang memasukkan/memperbarui/menghapus tupel dipertahankan bersama dengan tupel heap tetapi hal yang sama tidak dipertahankan dengan tupel indeks. Ini murni dilakukan untuk menghemat penyimpanan dan ini merupakan pertukaran antara ruang dan kinerja.
Sekarang kembali ke pertanyaan awal, karena informasi visibilitas di Tuple Indeks tidak ada, perlu berkonsultasi dengan tupel tumpukan yang sesuai untuk melihat apakah data yang dipilih terlihat. Jadi meskipun bagian lain dari data dari heap tuple tidak diperlukan, masih perlu mengakses halaman heap untuk memeriksa visibilitas. Tetapi sekali lagi, ada perubahan jika semua tupel pada halaman tertentu (halaman yang ditunjuk oleh indeks yaitu ItemPointer) terlihat maka tidak perlu merujuk setiap item halaman Heap untuk "pemeriksaan visibilitas" dan karenanya data hanya dapat dikembalikan dari halaman Indeks. Kasus khusus ini disebut "Pemindaian Hanya Indeks". Untuk mendukung ini, PostgreSQL memelihara peta visibilitas untuk setiap halaman untuk memeriksa visibilitas tingkat halaman.
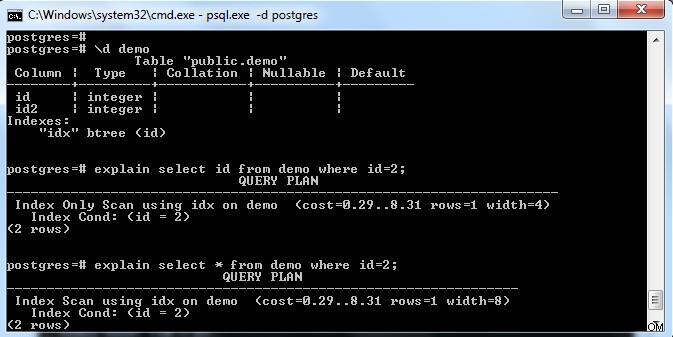
Seperti terlihat pada gambar di atas, terdapat indeks pada tabel “demo” dengan key pada kolom “id”. Jika kami mencoba untuk memilih hanya bidang indeks (yaitu id) maka ia memilih "Pemindaian Hanya Indeks" (mengingat halaman rujukan terlihat sepenuhnya).
Indeks Tergugus
Tidak ada dukungan indeks berkerumun langsung di PostgreSQL tetapi ada cara tidak langsung untuk sebagian mencapai hal yang sama. Ini dicapai dengan perintah SQL di bawah ini:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]Perintah pertama menginstruksikan database untuk mengelompokkan tabel (yaitu mengurutkan tabel) menggunakan indeks yang diberikan. Indeks ini seharusnya sudah dibuat. Pengelompokan ini hanya satu kali operasi dan dampaknya tidak tetap setelah operasi berikutnya pada tabel ini yaitu jika lebih banyak catatan dimasukkan/diperbarui, tabel mungkin tidak tetap dipesan. Jika diperlukan oleh pengguna untuk tetap menjaga tabel berkerumun (terurut) maka mereka dapat menggunakan perintah pertama tanpa memberikan nama indeks.
Perintah kedua hanya berguna untuk mengelompokkan ulang tabel (yaitu tabel yang sudah di-cluster menggunakan beberapa indeks). Perintah ini mengelompokkan ulang semua tabel dalam database saat ini yang dapat dilihat oleh pengguna yang terhubung saat ini.
Misalnya pada gambar di bawah ini, SELECT pertama mengembalikan catatan dalam urutan yang tidak disortir karena tidak ada indeks berkerumun. Meskipun sudah ada indeks non-cluster tetapi record dipilih dari area heap dimana record tidak diurutkan.
SELECT kedua mengembalikan catatan yang diurutkan berdasarkan kolom "id" karena telah dikelompokkan menggunakan indeks yang berisi kolom "id".
SELECT ketiga mengembalikan sebagian catatan dalam urutan yang diurutkan tetapi catatan yang baru dimasukkan tidak diurutkan. SELECT keempat kembali mengembalikan semua catatan dalam urutan yang diurutkan karena tabel telah dikelompokkan lagi
 Perintah Cluster PostgreSQL
Perintah Cluster PostgreSQL Jenis Indeks
PostgreSQL menyediakan beberapa jenis indeks seperti di bawah ini:
- B-Pohon
- Hash
- Inti
- GIN
- BRIN
Setiap jenis indeks mengimplementasikan berbagai jenis struktur data yang mendasarinya, yang paling cocok untuk berbagai jenis kueri. Secara default indeks B-Tree dibuat, yang merupakan indeks yang banyak digunakan. Detail dari setiap jenis indeks akan dibahas di blog mendatang.
Lain-lain:Indeks Parsial dan Ekspresi
Kami hanya membahas tentang indeks pada satu atau lebih kolom tabel tetapi ada dua cara lain untuk membuat indeks di PostgreSQL
- Indeks Parsial: Partial Index adalah indeks yang dibangun menggunakan subset dari kolom kunci untuk tabel tertentu. Subset didefinisikan oleh ekspresi kondisional yang diberikan selama membuat indeks. Jadi dengan indeks parsial, ruang penyimpanan untuk menyimpan data indeks akan disimpan. Jadi pengguna harus memilih kondisi sedemikian rupa sehingga itu bukan nilai yang sangat umum, karena untuk nilai yang lebih sering (umum) tetap indeks scan tidak akan dipilih. Fungsi lainnya tetap sama seperti untuk indeks normal. Contoh:Indeks Sebagian
- Indeks Ekspresi: Indeks ekspresi memberikan jenis fleksibilitas lain di PostgreSQL. Semua indeks yang dibahas sampai sekarang, termasuk indeks parsial, berada pada kumpulan kolom tertentu. Tetapi bagaimana jika kueri melibatkan akses tabel berdasarkan ekspresi (ekspresi yang melibatkan satu atau lebih kolom), tanpa indeks ekspresi, itu tidak akan memilih pemindaian indeks. Jadi untuk mengakses kueri semacam ini dengan cepat, PostgreSQL memungkinkan untuk membuat indeks pada ekspresi. Fungsi lainnya tetap sama seperti untuk indeks normal.
 Contoh:Indeks Ekspresi
Contoh:Indeks Ekspresi
Penyimpanan Indeks di InnoDB
Penggunaan dan fungsionalitas Index sebagian besar sama dengan yang ada di PostgreSQL dengan perbedaan utama dalam hal Clustered Index.
InnoDB mendukung dua kategori Indeks:
- Indeks Terkelompok
- Indeks Sekunder
Indeks Tergugus
Clustered Index adalah jenis indeks khusus di InnoDB. Di sini data yang diindeks tidak disimpan secara terpisah melainkan merupakan bagian dari seluruh data baris. Dengan kata lain, indeks berkerumun hanya memaksa data tabel untuk diurutkan secara fisik menggunakan kolom kunci indeks. Ini dapat dianggap sebagai “Kamus”, di mana data diurutkan berdasarkan alfabet.
Karena indeks klaster mengurutkan baris menggunakan kunci indeks, hanya ada satu indeks berkerumun. Juga, harus ada satu indeks berkerumun karena InnoDB menggunakan yang sama untuk memanipulasi data secara optimal selama berbagai operasi data.
Indeks berkerumun dibuat secara otomatis (sebagai bagian dari pembuatan tabel) menggunakan salah satu kolom tabel sesuai prioritas di bawah ini:
- Menggunakan kunci utama jika kunci utama disebutkan sebagai bagian dari pembuatan tabel.
- Memilih kolom unik yang semua kolom kuncinya BUKAN NULL.
- Jika tidak, secara internal menghasilkan indeks berkerumun tersembunyi pada kolom sistem yang berisi ID baris setiap baris.
Tidak seperti indeks non-clustered PostgreSQL, InnoDB mengakses baris menggunakan indeks cluster lebih cepat karena pencarian indeks mengarah langsung ke halaman dengan semua data baris dan karenanya menghindari I/O acak.
Juga mendapatkan data tabel dalam urutan diurutkan menggunakan indeks berkerumun sangat cepat karena semua data sudah diurutkan dan juga seluruh data tersedia.
Indeks Sekunder
Indeks yang dibuat secara eksplisit di InnoDB dianggap sebagai indeks Sekunder, yang mirip dengan indeks non-clustered PostgreSQL. Setiap record dalam penyimpanan indeks sekunder berisi kolom kunci utama dari baris (yang digunakan untuk membuat Indeks Clustered) dan juga kolom yang ditentukan untuk membuat indeks sekunder.
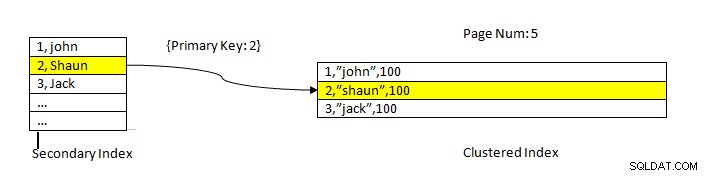 InnoDB:Data dibaca menggunakan indeks
InnoDB:Data dibaca menggunakan indeks Pengambilan data menggunakan indeks sekunder sama seperti pada kasus PostgreSQL kecuali bahwa pencarian indeks sekunder InnoDB memberikan kunci utama sebagai penunjuk untuk mengambil data yang tersisa dari indeks berkerumun.
Misalnya seperti pada gambar di atas, clustered index berada pada kolom ID, jadi data tabel diurutkan berdasarkan yang sama. Indeks sekunder ada di kolom “nama ”, sehingga kita dapat melihat indeks sekunder memiliki nilai ID dan nama. Setelah kami mencari menggunakan indeks sekunder, ia menemukan slot yang sesuai dengan nilai kunci yang sesuai. Kemudian kunci utama yang sesuai digunakan untuk merujuk ke bagian data yang tersisa dari indeks berkerumun.
MVCC untuk Indeks
MVCC indeks berkerumun menggunakan Model Undo InnoDB tradisional (Sebenarnya sama dengan MVCC seluruh data, karena indeks berkerumun tidak lain adalah seluruh data).
Tapi penggunaan MVCC Indeks sekunder pendekatan yang sedikit berbeda untuk mempertahankan MVCC. Pada pembaruan indeks sekunder, entri indeks lama ditandai dengan penghapusan dan catatan baru dimasukkan ke dalam penyimpanan yang sama yaitu UPDATE tidak ada di tempatnya. Akhirnya, entri indeks lama dibersihkan. Sekarang Anda mungkin telah memperhatikan bahwa MVCC indeks sekunder InnoDB hampir sama dengan model MVCC PostgreSQL.
Jenis Indeks
InnoDB hanya mendukung jenis Indeks B-Tree dan karenanya tidak perlu ditentukan saat membuat indeks.
Lain-lain:Indeks Hash Adaptif
Seperti yang disebutkan di bagian sebelumnya bahwa hanya indeks tipe B-Tree yang didukung oleh InnoDB tetapi ada twist. InnoDB memiliki fungsi untuk secara otomatis mendeteksi jika kueri dapat mengambil manfaat dari membangun indeks hash dan juga seluruh data tabel dapat masuk ke dalam memori, kemudian secara otomatis melakukannya.
Indeks hash dibangun menggunakan indeks B-Tree yang ada tergantung pada kueri. Jika ada beberapa indeks B-Tree sekunder, maka ia akan memilih salah satu yang memenuhi syarat sesuai kueri. Indeks hash yang dibangun tidak lengkap, hanya membangun indeks parsial sesuai dengan pola penggunaan data.
Ini adalah salah satu fitur yang sangat kuat untuk meningkatkan kinerja kueri secara dinamis.
Kesimpulan
Penggunaan indeks apa pun dalam basis data apa pun sangat membantu untuk meningkatkan kinerja READ tetapi pada saat yang sama, ini menurunkan kinerja INSERT/UPDATE karena perlu menulis data tambahan. Jadi indeks harus dipilih dengan sangat bijaksana dan harus dibuat hanya jika kunci indeks digunakan sebagai predikat untuk mengambil data.
InnoDB menyediakan fitur yang sangat bagus dalam hal indeks berkerumun, yang mungkin sangat berguna tergantung pada kasus penggunaan. Selain itu, pengindeksan hash adaptifnya sangat kuat.
Sedangkan PostgreSQL menyediakan berbagai jenis indeks, yang benar-benar dapat memberikan opsi jangkauan fitur dan satu atau semua dapat digunakan tergantung pada kasus penggunaan bisnis. Juga indeks parsial dan ekspresi cukup berguna tergantung pada kasus penggunaan.