Membangun Ketersediaan Tinggi, Selangkah demi Selangkah
Ketika datang ke infrastruktur database, kita semua menginginkannya. Kita semua berusaha untuk membangun setup yang sangat tersedia. Redundansi adalah kuncinya. Kami mulai menerapkan redundansi di level terendah dan melanjutkan tumpukan. Dimulai dengan perangkat keras - catu daya yang berlebihan, pendinginan yang berlebihan, disk hot-swap. Lapisan jaringan - beberapa NIC terikat bersama dan terhubung ke sakelar berbeda yang menggunakan router yang berlebihan. Untuk penyimpanan kami menggunakan disk yang diatur dalam RAID, yang memberikan kinerja lebih baik tetapi juga redundansi. Kemudian, pada tingkat perangkat lunak, kami menggunakan teknologi pengelompokan:beberapa node basis data yang bekerja bersama untuk mengimplementasikan redundansi:Cluster MySQL, Cluster Galera.
Semua ini tidak baik jika Anda memiliki semuanya dalam satu pusat data:saat pusat data mati, atau sebagian layanan (tetapi yang penting) offline, atau bahkan jika Anda kehilangan konektivitas ke pusat data, layanan Anda akan mati - tidak peduli jumlah redundansi di tingkat yang lebih rendah. Dan ya, hal itu terjadi.
- Gangguan layanan S3 mendatangkan malapetaka di wilayah AS-Timur-1 pada Februari 2017
- Gangguan Layanan EC2 dan RDS di wilayah AS-Timur pada bulan April 2011
- EC2, EBS, dan RDS terganggu di wilayah UE-Barat pada Agustus 2011
- Pemadaman listrik menyebabkan Rackspace Texas DC pada bulan Juni 2009
- Kegagalan UPS menyebabkan ratusan server offline di Rackspace London DC pada Januari 2010
Ini sama sekali bukan daftar lengkap kegagalan, ini hanya hasil pencarian cepat Google. Ini berfungsi sebagai contoh bahwa segala sesuatunya mungkin dan akan salah jika Anda meletakkan semua telur Anda ke dalam keranjang yang sama. Satu contoh lagi adalah Badai Sandy, yang menyebabkan eksodus besar data dari AS-Timur ke AS-Barat DC - pada saat itu Anda hampir tidak dapat memutar contoh di AS-Barat karena semua orang bergegas memindahkan infrastruktur mereka ke pantai lain dengan harapan bahwa North Virginia DC akan sangat terpengaruh oleh cuaca.
Jadi, pengaturan multi-pusat data adalah suatu keharusan jika Anda ingin membangun lingkungan ketersediaan tinggi. Dalam posting blog ini, kita akan membahas bagaimana membangun infrastruktur tersebut menggunakan Galera Cluster untuk MySQL/MariaDB.
Konsep Galera
Sebelum kita melihat solusi tertentu, mari kita luangkan waktu untuk menjelaskan dua konsep yang sangat penting dalam pengaturan Galera multi-DC yang sangat tersedia.
Kuorum
Ketersediaan tinggi membutuhkan sumber daya - yaitu, Anda memerlukan sejumlah node dalam cluster untuk membuatnya sangat tersedia. Sebuah cluster dapat mentolerir hilangnya beberapa anggotanya, tetapi hanya sampai batas tertentu. Di luar tingkat kegagalan tertentu, Anda mungkin melihat skenario otak terbelah.
Mari kita ambil contoh dengan setup 2 node. Jika salah satu node mati, bagaimana node lainnya dapat mengetahui bahwa peernya crash dan itu bukan kegagalan jaringan? Dalam hal ini, node lain mungkin juga aktif dan berjalan, melayani lalu lintas. Tidak ada cara yang baik untuk menangani kasus seperti itu… Inilah sebabnya toleransi kesalahan biasanya dimulai dari tiga node. Galera menggunakan perhitungan kuorum untuk menentukan apakah cluster tersebut aman untuk menangani lalu lintas, atau jika harus menghentikan operasinya. Setelah kegagalan, semua node yang tersisa mencoba untuk terhubung satu sama lain dan menentukan berapa banyak dari mereka yang naik. Kemudian dibandingkan dengan status cluster sebelumnya, dan selama lebih dari 50% node aktif, cluster dapat terus beroperasi.
Ini menghasilkan:
2 cluster node - tidak ada toleransi kesalahan
3 node cluster - hingga 1 crash
4 node cluster - hingga 1 crash (jika dua node crash, hanya 50% dari cluster akan tersedia, Anda memerlukan lebih dari 50% node untuk bertahan)
5 node cluster - hingga 2 error
6 node cluster - hingga 2 error
Anda mungkin melihat polanya - Anda ingin cluster Anda memiliki jumlah node yang ganjil - dalam hal ketersediaan tinggi, tidak ada gunanya berpindah dari 5 ke 6 node dalam cluster. Jika Anda ingin toleransi kesalahan yang lebih baik, Anda harus memilih 7 node.
Segmen
Biasanya, dalam kluster Galera, semua komunikasi mengikuti pola all to all. Setiap node berbicara dengan semua node lain dalam cluster.
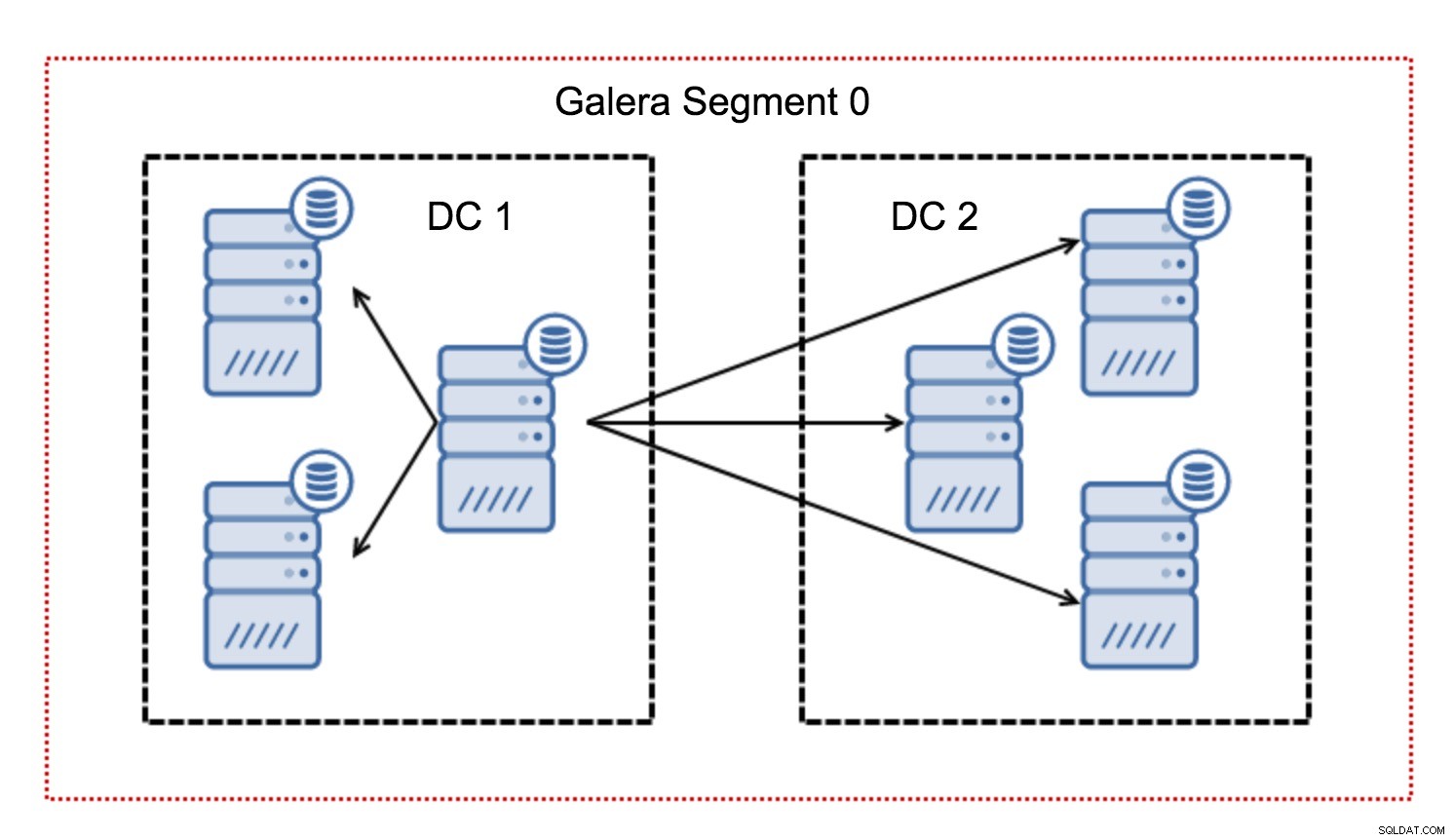
Seperti yang Anda ketahui, setiap writeset di Galera harus disertifikasi oleh semua node dalam cluster - oleh karena itu setiap penulisan yang terjadi pada sebuah node harus ditransfer ke semua node dalam cluster. Ini berfungsi dengan baik di lingkungan latensi rendah. Tetapi jika kita berbicara tentang pengaturan multi-DC, kita perlu mempertimbangkan latensi yang jauh lebih tinggi daripada di jaringan lokal. Untuk membuatnya lebih tertahankan dalam kluster yang mencakup Jaringan Area Luas, Galera memperkenalkan segmen.
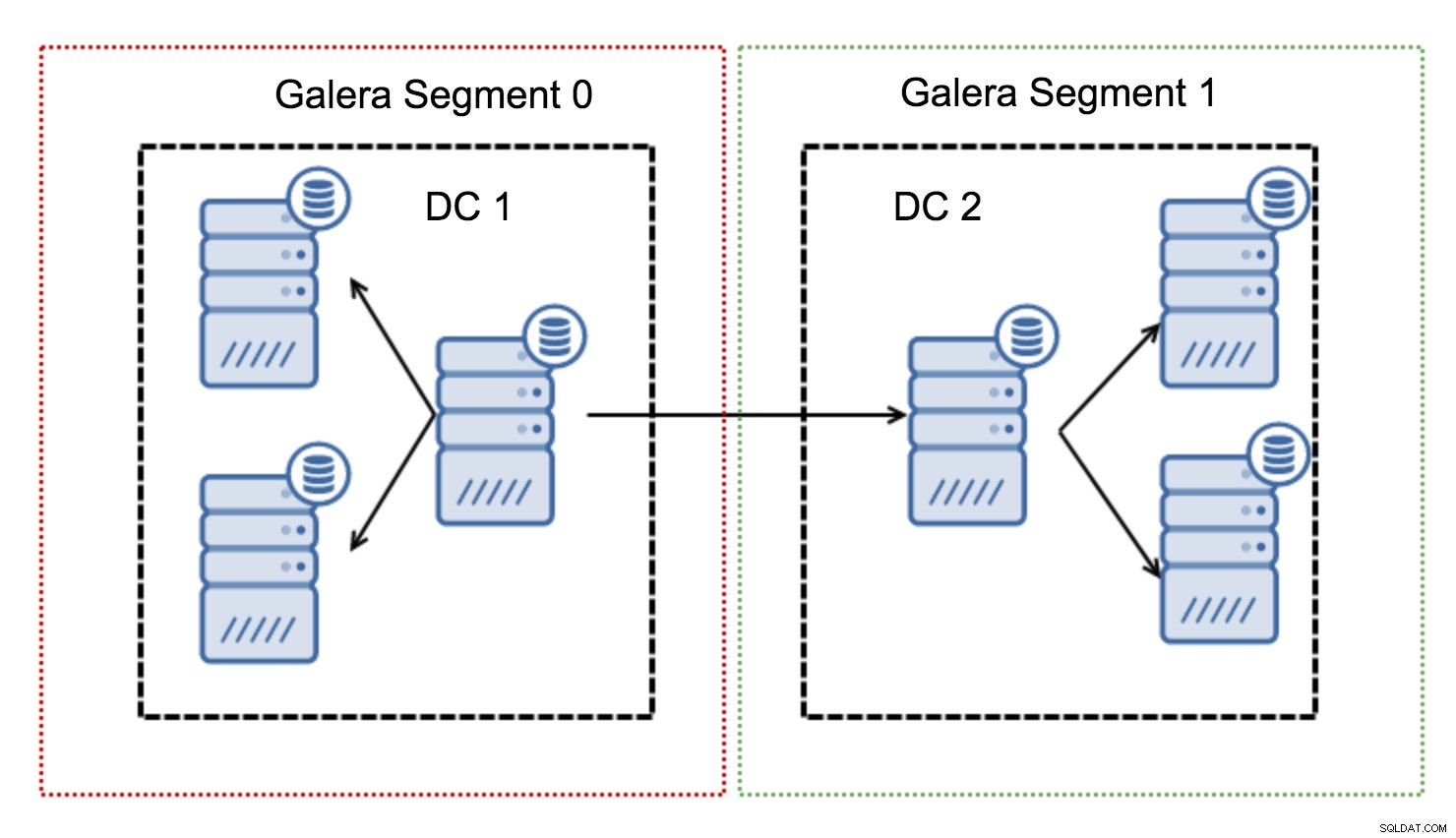
Mereka bekerja dengan memuat lalu lintas Galera dalam sekelompok node (segmen). Semua node dalam satu segmen bertindak seolah-olah mereka berada di jaringan lokal - mereka mengasumsikan komunikasi satu ke semua. Untuk lalu lintas lintas segmen, semuanya berbeda - di setiap segmen, satu simpul "relai" dipilih, semua lalu lintas lintas segmen melewati simpul tersebut. Ketika node relay turun, node lain dipilih. Ini tidak banyak mengurangi latensi - lagi pula, latensi WAN akan tetap sama tidak peduli apakah Anda membuat koneksi ke satu host jarak jauh atau ke beberapa host jarak jauh, tetapi mengingat bahwa tautan WAN cenderung terbatas dalam bandwidth dan mungkin ada biaya untuk jumlah data yang ditransfer, pendekatan tersebut memungkinkan Anda untuk membatasi jumlah data yang dipertukarkan antar segmen. Pilihan penghematan waktu dan biaya lainnya adalah kenyataan bahwa node di segmen yang sama diprioritaskan ketika donor diperlukan - sekali lagi, ini membatasi jumlah data yang ditransfer melalui WAN dan, kemungkinan besar, mempercepat SST karena jaringan lokal hampir selalu akan lebih cepat daripada tautan WAN.
Sekarang setelah kita menyelesaikan beberapa konsep ini, mari kita lihat beberapa aspek penting lainnya dari penyiapan multi-DC untuk kluster Galera.
Masalah yang Akan Anda Hadapi
Saat bekerja di lingkungan yang mencakup seluruh WAN, ada beberapa masalah yang perlu Anda pertimbangkan saat mendesain lingkungan Anda.
Perhitungan Kuorum
Di bagian sebelumnya, kami menjelaskan bagaimana perhitungan kuorum terlihat seperti di cluster Galera - singkatnya, Anda ingin memiliki jumlah node ganjil untuk memaksimalkan survivabilitas. Semua itu masih berlaku dalam pengaturan multi-DC, tetapi beberapa elemen lagi ditambahkan ke dalam campuran. Pertama-tama, Anda perlu memutuskan apakah Anda ingin Galera menangani kegagalan pusat data secara otomatis. Ini akan menentukan berapa banyak pusat data yang akan Anda gunakan. Bayangkan dua DC - jika Anda akan membagi node Anda 50% - 50%, jika satu pusat data turun, yang kedua tidak memiliki 50%+1 node untuk mempertahankan status "utama". Jika Anda membagi node Anda dengan cara yang tidak merata, menggunakan sebagian besar dari mereka di pusat data "utama", ketika pusat data itu turun, DC "cadangan" tidak akan memiliki 50% + 1 node untuk membentuk kuorum. Anda dapat menetapkan bobot yang berbeda ke node tetapi hasilnya akan sama persis - tidak ada cara untuk secara otomatis melakukan failover antara dua DC tanpa intervensi manual. Untuk menerapkan failover otomatis, Anda memerlukan lebih dari dua DC. Sekali lagi, idealnya angka ganjil - tiga pusat data adalah pengaturan yang sangat bagus. Selanjutnya, pertanyaannya adalah - berapa banyak node yang harus Anda miliki? Anda ingin mereka didistribusikan secara merata di seluruh pusat data. Sisanya hanyalah masalah berapa banyak node gagal yang harus ditangani oleh penyiapan Anda.
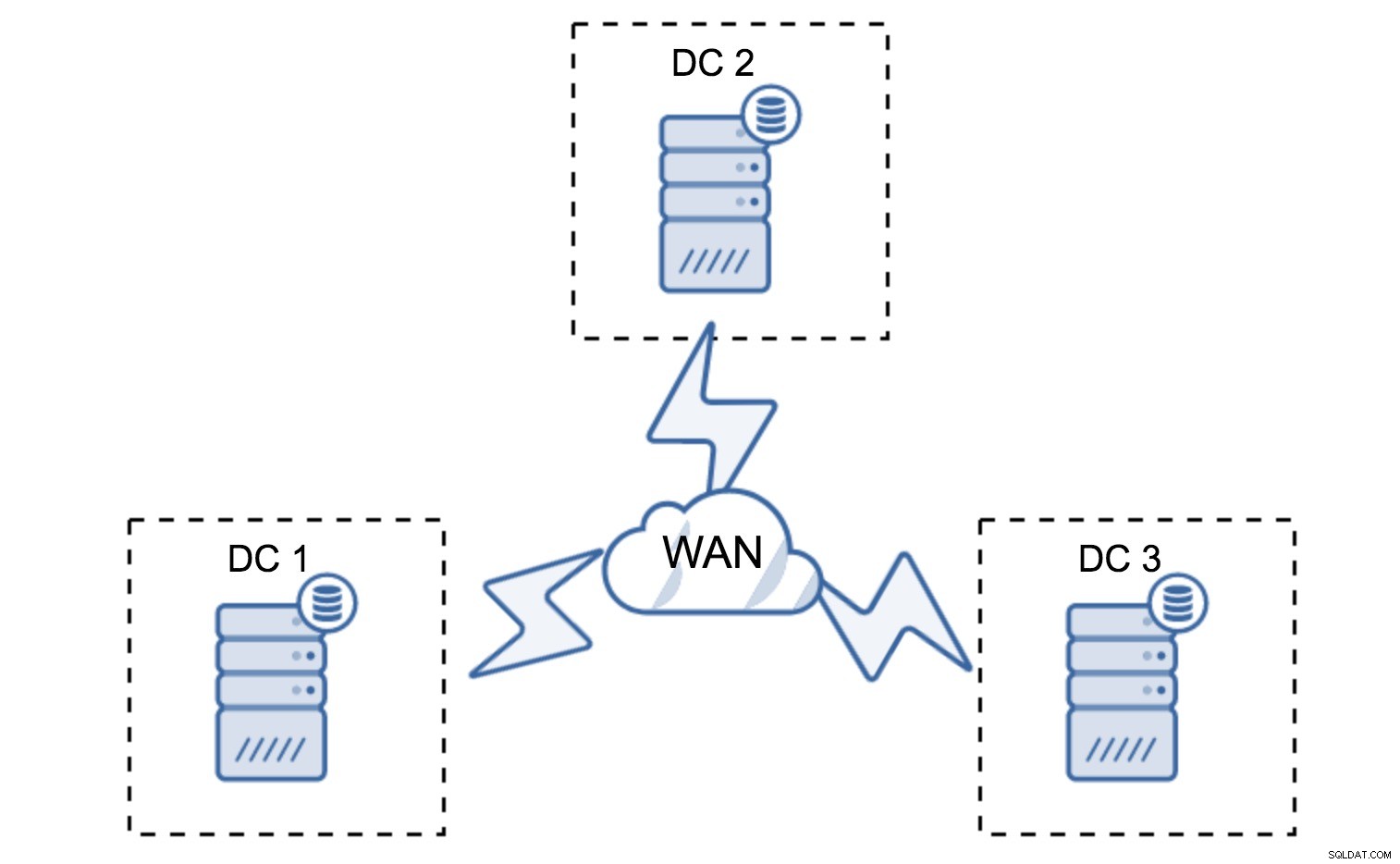
Pengaturan minimal akan menggunakan satu node per pusat data - ini memiliki kelemahan serius. Setiap transfer status akan memerlukan pemindahan data di seluruh WAN dan ini mengakibatkan waktu yang dibutuhkan lebih lama untuk menyelesaikan SST atau biaya yang lebih tinggi.
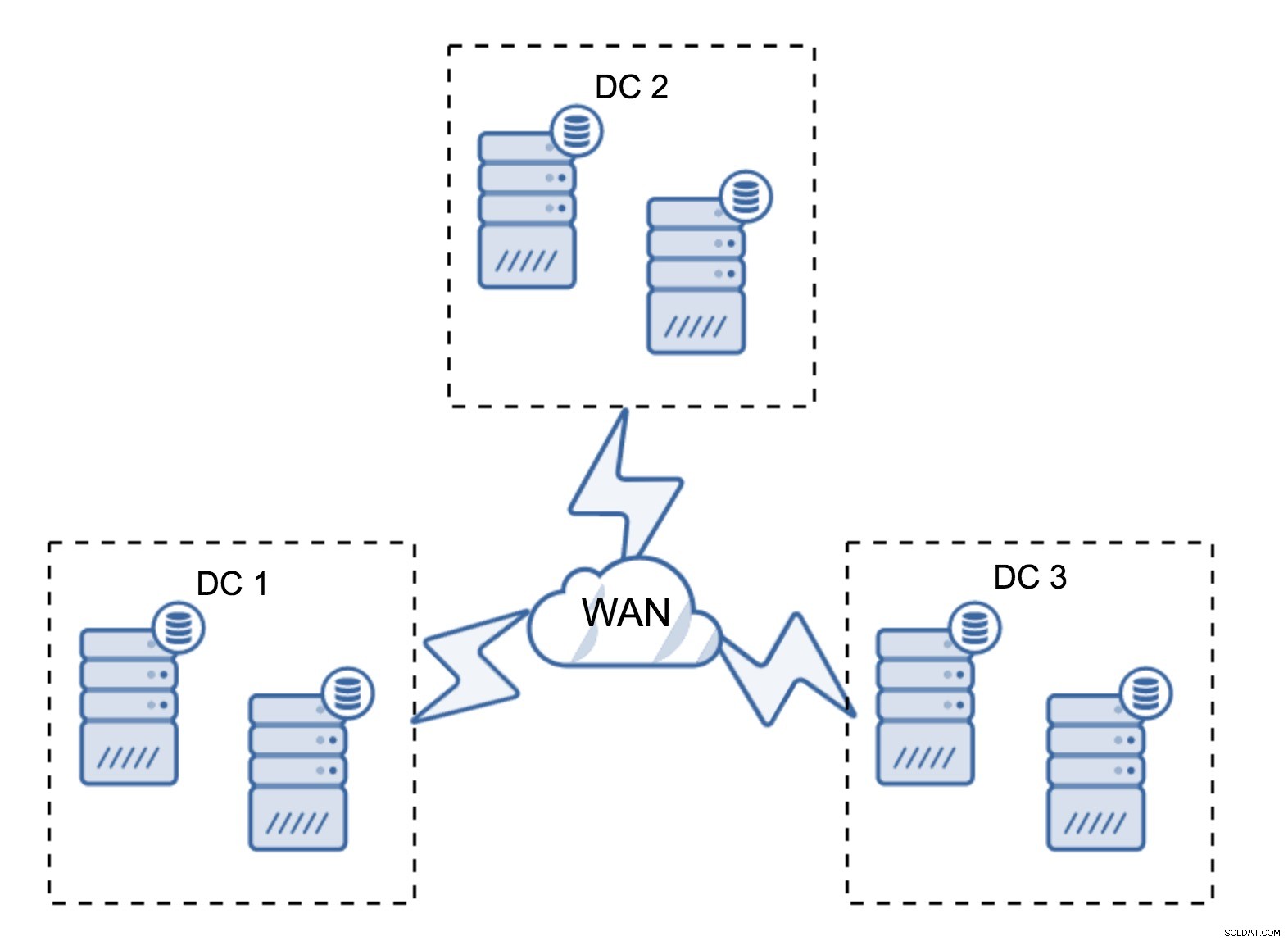
Pengaturan yang cukup umum adalah memiliki enam node, dua per pusat data. Pengaturan ini tampaknya tidak terduga karena memiliki jumlah node yang genap. Namun, ketika Anda memikirkannya, itu mungkin bukan masalah besar:sangat kecil kemungkinannya bahwa tiga node akan turun sekaligus, dan pengaturan seperti itu akan bertahan dari crash hingga dua node. Seluruh pusat data mungkin offline dan dua DC yang tersisa akan terus beroperasi. Ini juga memiliki keuntungan besar dibandingkan pengaturan minimal - ketika sebuah node offline, selalu ada node kedua di pusat data yang dapat berfungsi sebagai donor. Sebagian besar waktu, WAN tidak akan digunakan untuk SST.
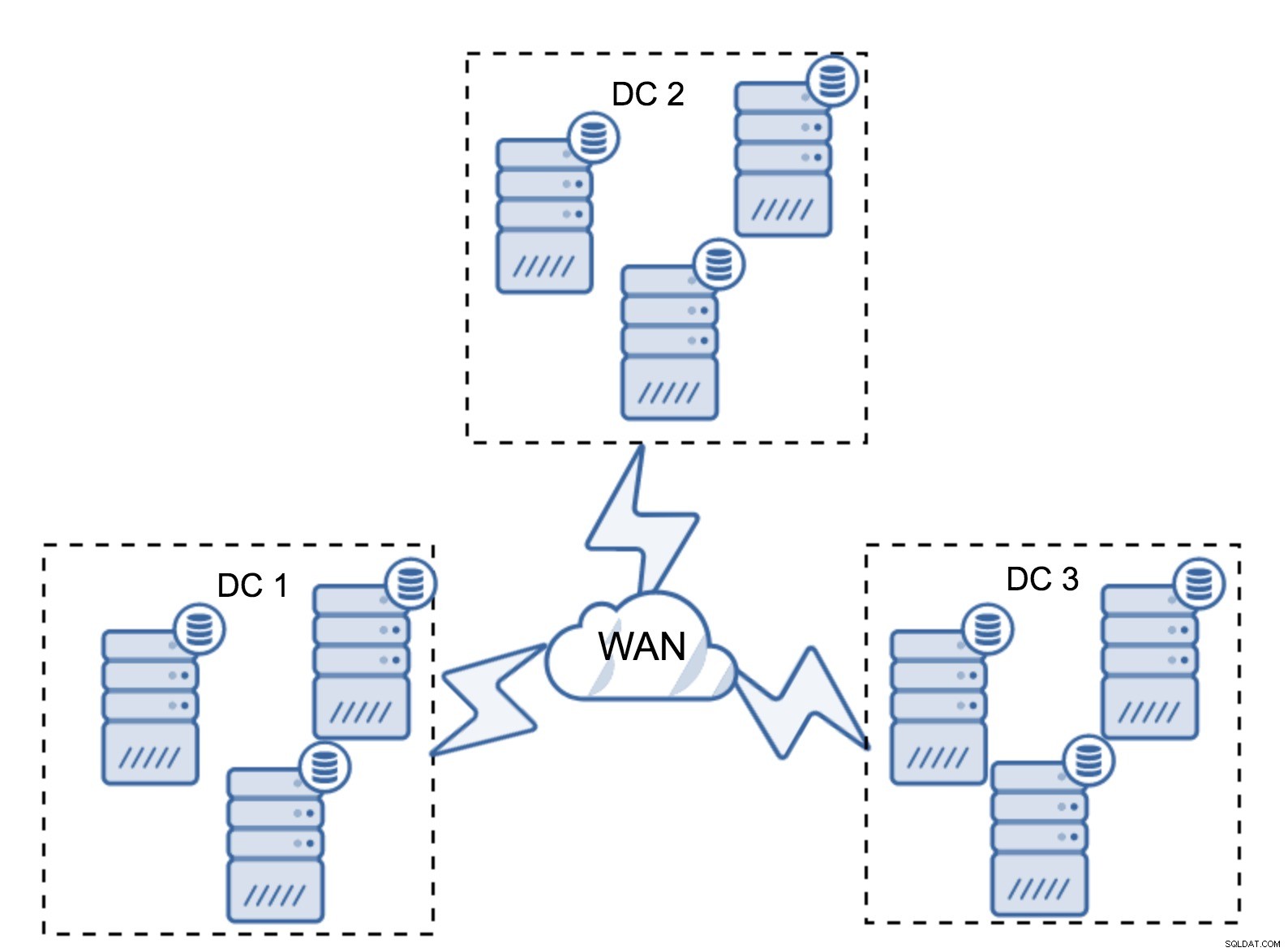
Tentu saja, Anda dapat meningkatkan jumlah node menjadi tiga per cluster, total sembilan. Ini memberi Anda kemampuan bertahan yang lebih baik:hingga empat node mungkin macet dan cluster akan tetap bertahan. Di sisi lain, Anda harus ingat bahwa, bahkan dengan penggunaan segmen, lebih banyak node berarti overhead operasi yang lebih tinggi dan Anda dapat menskalakan kluster Galera hanya sampai batas tertentu.
Mungkin saja tidak diperlukan pusat data ketiga karena, katakanlah, aplikasi Anda hanya terletak di dua pusat data tersebut. Tentu saja, persyaratan tiga pusat data masih berlaku sehingga Anda tidak akan menyia-nyiakannya, tetapi tidak apa-apa menggunakan Arbiter Galera (garbd) alih-alih server basis data yang terisi penuh.
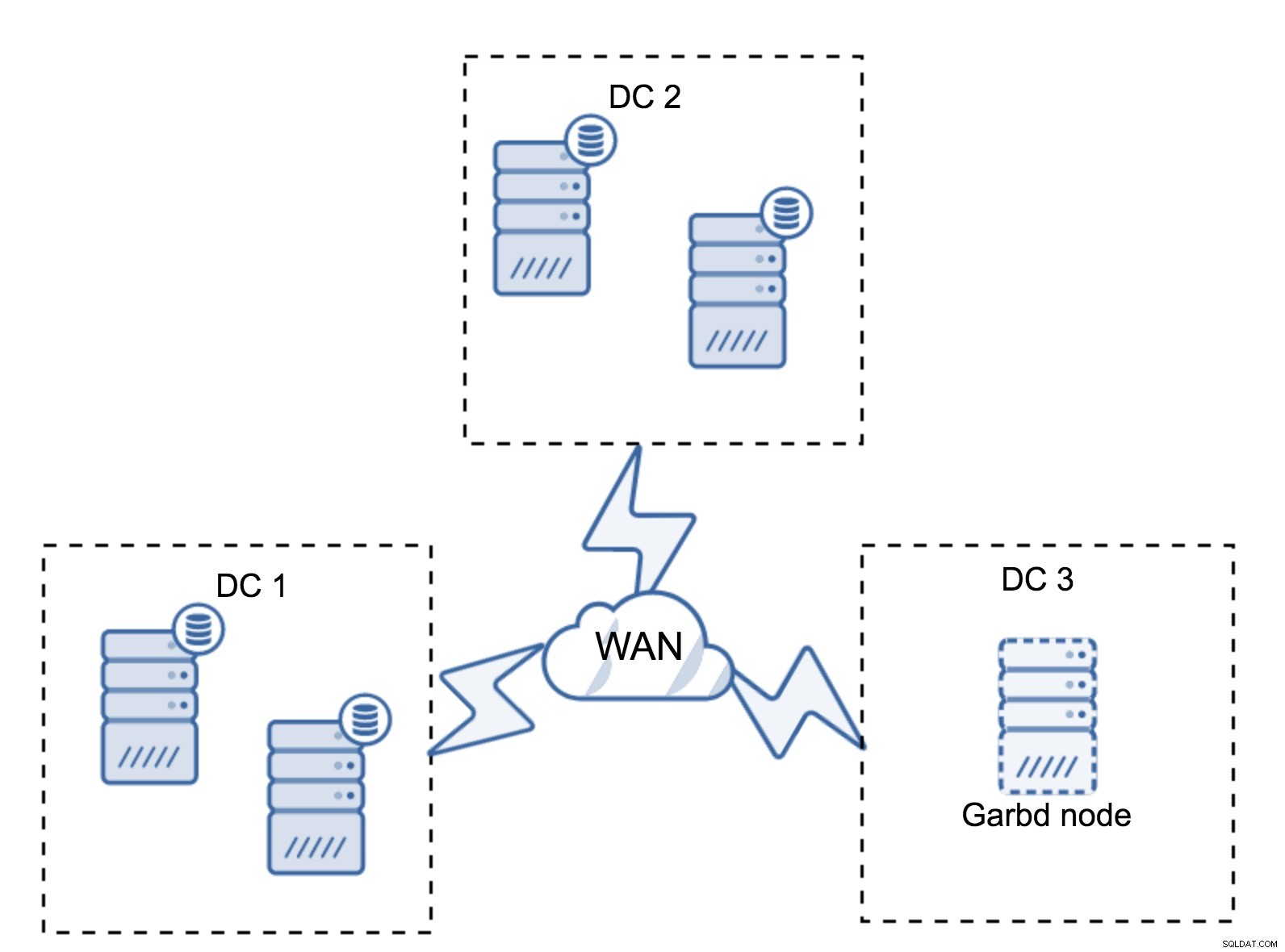
Garbd dapat diinstal pada node yang lebih kecil, bahkan server virtual. Itu tidak memerlukan perangkat keras yang kuat, itu tidak menyimpan data apa pun atau menerapkan set tulis apa pun. Tapi itu tidak melihat semua lalu lintas replikasi, dan mengambil bagian dalam perhitungan kuorum. Berkat itu, Anda dapat menerapkan pengaturan seperti empat node, dua per DC + garbd di yang ketiga - Anda memiliki total lima node, dan cluster tersebut dapat menerima hingga dua kegagalan. Jadi itu berarti dapat menerima shutdown penuh dari salah satu pusat data.
Pilihan mana yang lebih baik untuk Anda? Tidak ada solusi terbaik untuk semua kasus, semuanya tergantung pada kebutuhan infrastruktur Anda. Untungnya, ada beberapa opsi berbeda untuk dipilih:lebih banyak atau lebih sedikit node, 3 DC penuh atau 2 DC dan garbd di yang ketiga - kemungkinan besar Anda akan menemukan sesuatu yang cocok untuk Anda.
Latensi Jaringan
Saat bekerja dengan pengaturan multi-DC, Anda harus ingat bahwa latensi jaringan akan jauh lebih tinggi daripada yang Anda harapkan dari lingkungan jaringan lokal. Ini dapat sangat mengurangi kinerja kluster Galera saat Anda membandingkannya dengan instans MySQL mandiri atau penyiapan replikasi MySQL. Persyaratan bahwa semua node harus mengesahkan writeset berarti bahwa semua node harus menerimanya, tidak peduli seberapa jauh mereka. Dengan replikasi asinkron, tidak perlu menunggu sebelum komit. Tentu saja, replikasi memiliki masalah dan kekurangan lain, tetapi latensi bukanlah yang utama. Masalahnya terutama terlihat ketika database Anda memiliki hot spot - baris, yang sering diperbarui (penghitung, antrian, dll). Baris tersebut tidak dapat diperbarui lebih dari sekali per perjalanan pulang pergi jaringan. Untuk kluster yang tersebar di seluruh dunia, ini dapat dengan mudah berarti bahwa Anda tidak akan dapat memperbarui satu baris lebih sering dari 2 - 3 kali per detik. Jika ini menjadi batasan bagi Anda, itu mungkin berarti bahwa cluster Galera tidak cocok untuk beban kerja khusus Anda.
Lapisan Proxy di Cluster Galera Multi-DC
Tidaklah cukup memiliki klaster Galera yang mencakup beberapa pusat data, Anda masih memerlukan aplikasi Anda untuk mengaksesnya. Salah satu metode populer untuk menyembunyikan kompleksitas lapisan basis data dari suatu aplikasi adalah dengan menggunakan proxy. Proxy digunakan sebagai titik masuk ke database, mereka melacak status node database dan harus selalu mengarahkan lalu lintas hanya ke node yang tersedia. Di bagian ini, kami akan mencoba mengusulkan desain lapisan proxy yang dapat digunakan untuk cluster Galera multi-DC. Kami akan menggunakan ProxySQL, yang memberi Anda sedikit fleksibilitas dalam menangani node database, tetapi Anda dapat menggunakan proxy lain, selama proxy tersebut dapat melacak status node Galera.
Di mana Menemukan Proksi?
Singkatnya, ada dua pola umum di sini:Anda dapat menerapkan ProxySQL pada node terpisah atau Anda dapat menerapkannya pada host aplikasi. Mari kita lihat pro dan kontra dari masing-masing penyiapan ini.
Lapisan Proksi sebagai Kumpulan Host Terpisah
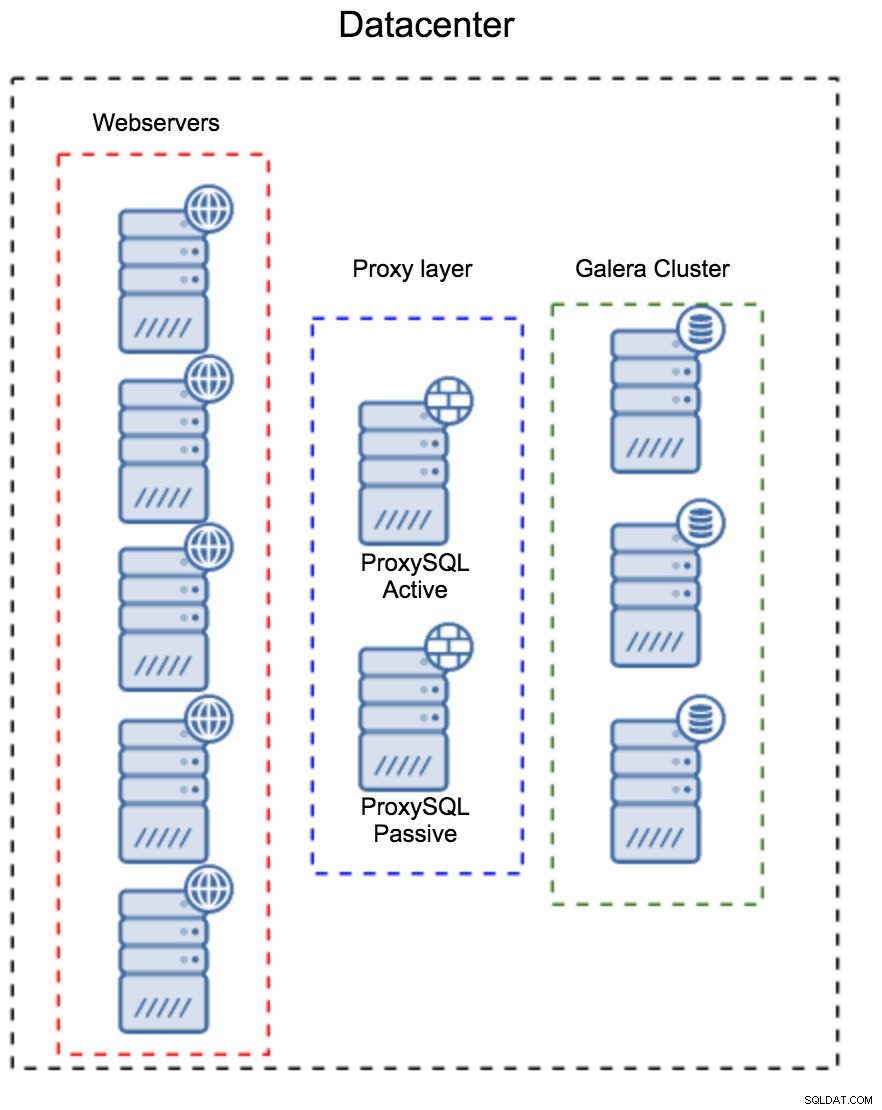
Pola pertama adalah membangun lapisan proxy menggunakan host khusus yang terpisah. Anda dapat menerapkan ProxySQL pada beberapa host, dan menggunakan IP Virtual dan tetap hidup untuk mempertahankan ketersediaan tinggi. Aplikasi akan menggunakan VIP untuk terhubung ke database, dan VIP akan memastikan bahwa permintaan akan selalu dirutekan ke ProxySQL yang tersedia. Masalah utama dengan penyiapan ini adalah Anda menggunakan paling banyak salah satu instans ProxySQL - semua node siaga tidak digunakan untuk merutekan lalu lintas. Ini mungkin memaksa Anda untuk menggunakan perangkat keras yang lebih kuat daripada yang biasanya Anda gunakan. Di sisi lain, lebih mudah untuk mempertahankan setup - Anda harus menerapkan perubahan konfigurasi pada semua node ProxySQL, tetapi hanya akan ada beberapa dari mereka. Anda juga dapat menggunakan opsi ClusterControl untuk menyinkronkan node. Penyiapan seperti itu harus diduplikasi di setiap pusat data yang Anda gunakan.
Proxy Terpasang pada Instance Aplikasi
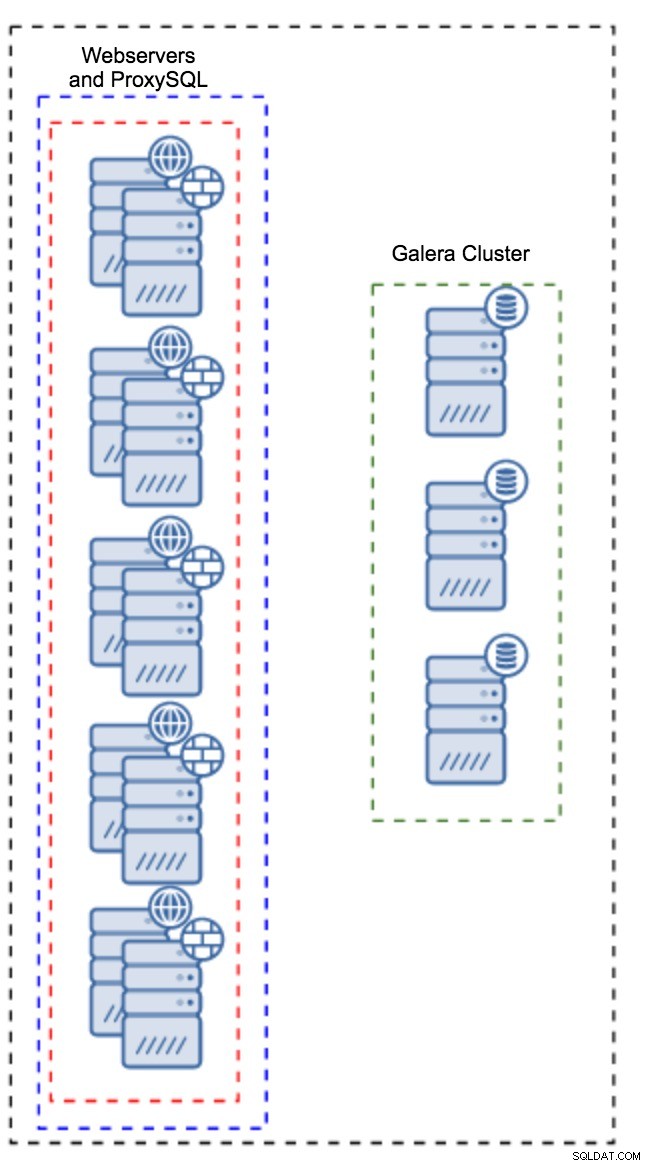
Alih-alih memiliki kumpulan host yang terpisah, ProxySQL juga dapat diinstal pada host aplikasi. Aplikasi akan terhubung langsung ke ProxySQL di localhost, bahkan bisa menggunakan soket unix untuk meminimalkan overhead koneksi TCP. Keuntungan utama dari pengaturan semacam itu adalah Anda memiliki sejumlah besar instans ProxySQL, dan beban didistribusikan secara merata di seluruh instans tersebut. Jika salah satu turun, hanya host aplikasi itu yang akan terpengaruh. Node yang tersisa akan terus bekerja. Masalah paling serius yang harus dihadapi adalah manajemen konfigurasi. Dengan sejumlah besar node ProxySQL, sangat penting untuk menemukan metode otomatis untuk menjaga konfigurasinya tetap sinkron. Anda dapat menggunakan ClusterControl, atau alat manajemen konfigurasi seperti Wayang.
Menyetel Galera dalam Lingkungan WAN
Default Galera dirancang untuk jaringan lokal dan jika Anda ingin menggunakannya di lingkungan WAN, diperlukan beberapa penyetelan. Mari kita bahas beberapa tweak dasar yang dapat Anda buat. Harap diingat bahwa penyetelan yang tepat memerlukan data produksi dan lalu lintas - Anda tidak bisa hanya membuat beberapa perubahan dan menganggapnya baik, Anda harus melakukan tolok ukur yang tepat.
Konfigurasi Sistem Operasi
Mari kita mulai dengan konfigurasi sistem operasi. Tidak semua modifikasi yang diusulkan di sini terkait dengan WAN, tetapi selalu baik untuk mengingatkan diri kita sendiri apa titik awal yang baik untuk instalasi MySQL apa pun.
vm.swappiness = 1Swappiness mengontrol seberapa agresif sistem operasi akan menggunakan swap. Ini tidak boleh disetel ke nol karena pada kernel yang lebih baru, ini mencegah OS menggunakan swap sama sekali dan dapat menyebabkan masalah kinerja yang serius.
/sys/block/*/queue/scheduler = deadline/noopPenjadwal untuk perangkat blok, yang digunakan MySQL, harus disetel ke tenggat waktu atau noop. Pilihan yang tepat bergantung pada tolok ukur tetapi kedua setelan harus memberikan kinerja yang serupa, lebih baik daripada penjadwal default, CFQ.
Untuk MySQL, Anda harus mempertimbangkan untuk menggunakan EXT4 atau XFS, tergantung pada kernel (kinerja sistem file tersebut berubah dari satu versi kernel ke versi lainnya). Lakukan beberapa tolok ukur untuk menemukan opsi yang lebih baik untuk Anda.
Selain itu, Anda mungkin ingin melihat pengaturan jaringan sysctl. Kami tidak akan membahasnya secara mendetail (Anda dapat menemukan dokumentasinya di sini) tetapi ide umumnya adalah untuk meningkatkan buffer, backlog, dan timeout, untuk memudahkan mengakomodasi stall dan tautan WAN yang tidak stabil.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Selain penyetelan OS, Anda harus mempertimbangkan untuk mengubah jaringan Galera - setelan terkait.
evs.suspect_timeout
evs.inactive_timeoutAnda mungkin ingin mempertimbangkan untuk mengubah nilai default dari variabel-variabel ini. Kedua batas waktu mengatur bagaimana cluster mengeluarkan node yang gagal. Waktu tunggu tersangka terjadi ketika semua node tidak dapat mencapai anggota yang tidak aktif. Batas waktu tidak aktif menentukan batas keras berapa lama sebuah node dapat tetap berada di cluster jika tidak merespons. Biasanya Anda akan menemukan bahwa nilai default berfungsi dengan baik. Namun dalam beberapa kasus, terutama jika Anda menjalankan klaster Galera melalui WAN (misalnya, antar wilayah AWS), meningkatkan variabel tersebut dapat menghasilkan kinerja yang lebih stabil. Sebaiknya setel keduanya ke PT1M, untuk memperkecil kemungkinan ketidakstabilan link WAN akan mengeluarkan node dari cluster.
evs.send_window
evs.user_send_windowVariabel ini, evs.send_window dan evs.user_send_window , tentukan berapa banyak paket yang dapat dikirim melalui replikasi secara bersamaan (evs.send_window ) dan berapa banyak dari mereka yang mungkin berisi data (evs.user_send_window ). Untuk koneksi berlatensi tinggi, mungkin ada baiknya meningkatkan nilai tersebut secara signifikan (512 atau 1024 misalnya).
evs.inactive_check_periodVariabel di atas juga dapat diubah. evs.inactive_check_period , secara default, diatur ke satu detik, yang mungkin terlalu sering untuk pengaturan WAN. Kami menyarankan untuk menyetelnya ke PT30S.
gcs.fc_factor
gcs.fc_limitDi sini kami ingin meminimalkan kemungkinan kontrol aliran akan muncul, oleh karena itu kami sarankan untuk mengatur gcs.fc_factor menjadi 1 dan meningkatkan gcs.fc_limit ke, misalnya, 260.
gcs.max_packet_sizeSaat kami bekerja dengan tautan WAN, di mana latensi secara signifikan lebih tinggi, kami ingin meningkatkan ukuran paket. Titik awal yang baik adalah 2097152.
Seperti yang kami sebutkan sebelumnya, hampir tidak mungkin untuk memberikan resep sederhana tentang cara mengatur parameter ini karena bergantung pada terlalu banyak faktor - Anda harus melakukan tolok ukur sendiri, menggunakan data sedekat mungkin dengan data produksi Anda, sebelum Anda dapat mengatakan sistem Anda disetel. Karena itu, pengaturan tersebut akan memberi Anda titik awal untuk penyetelan yang lebih tepat.
Itu saja untuk saat ini. Galera bekerja cukup baik di lingkungan WAN, jadi cobalah dan beri tahu kami cara Anda melakukannya.