Memindahkan data Anda ke layanan cloud publik adalah keputusan besar. Semua vendor cloud utama menawarkan layanan database cloud, dengan Amazon RDS untuk MySQL mungkin yang paling populer.
Di blog ini, kita akan melihat lebih dekat apa itu, cara kerjanya, dan membandingkan kelebihan dan kekurangannya.
RDS (Layanan Database Relasional) adalah penawaran Amazon Web Services. Singkatnya, ini adalah Database as a Service, tempat Amazon menyebarkan dan mengoperasikan database Anda. Ini menangani tugas-tugas seperti mencadangkan dan menambal perangkat lunak basis data, serta ketersediaan tinggi. Beberapa database didukung oleh RDS, kami di sini terutama tertarik pada MySQL - Amazon mendukung MySQL dan MariaDB. Ada juga Aurora, yang merupakan tiruan MySQL dari Amazon, yang ditingkatkan, terutama di bidang replikasi dan ketersediaan tinggi.
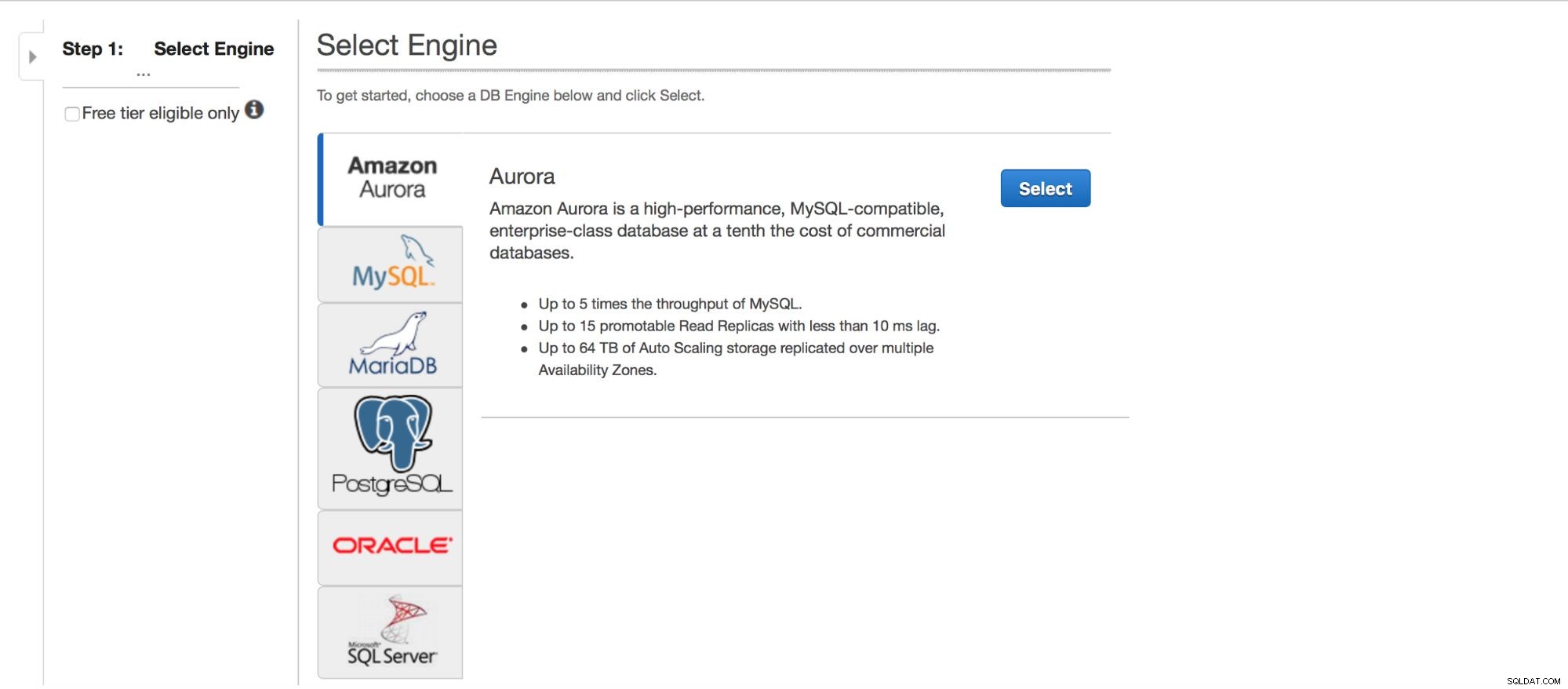
Menyebarkan MySQL melalui RDS
Mari kita lihat penerapan MySQL melalui RDS. Kami memilih MySQL dan kemudian kami disajikan dengan beberapa pola penerapan untuk dipilih.
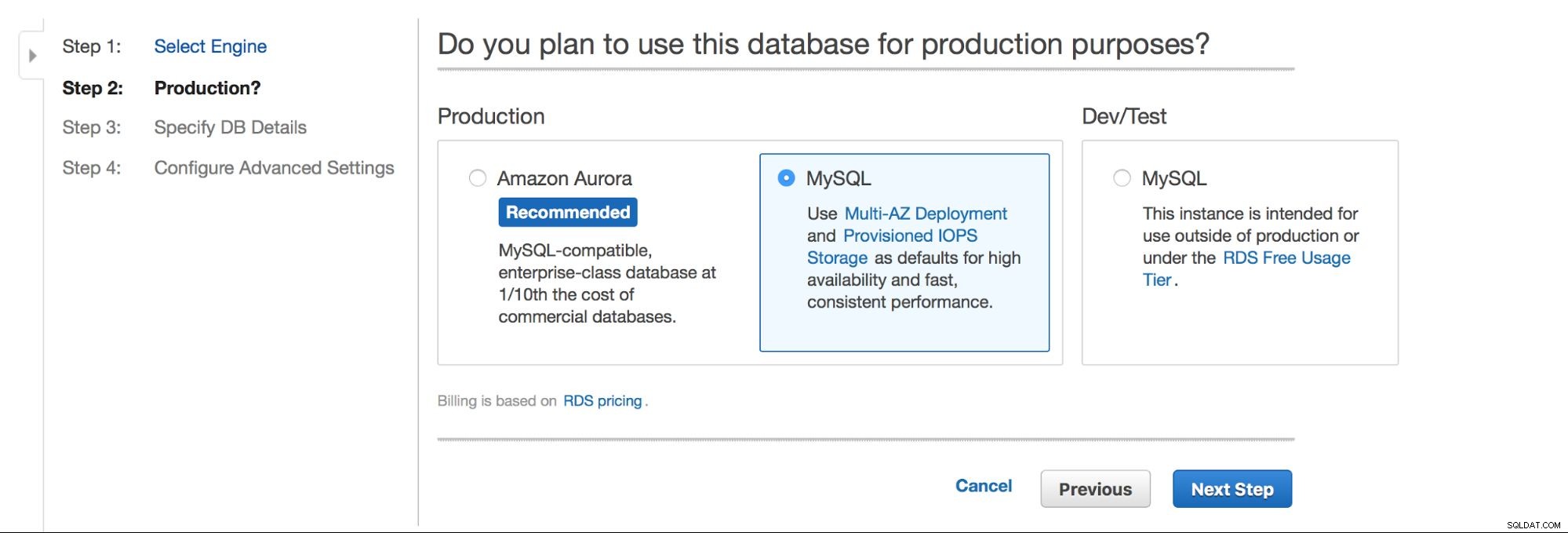
Pilihan utama adalah - apakah kita ingin memiliki ketersediaan tinggi atau tidak? Aurora juga dipromosikan.
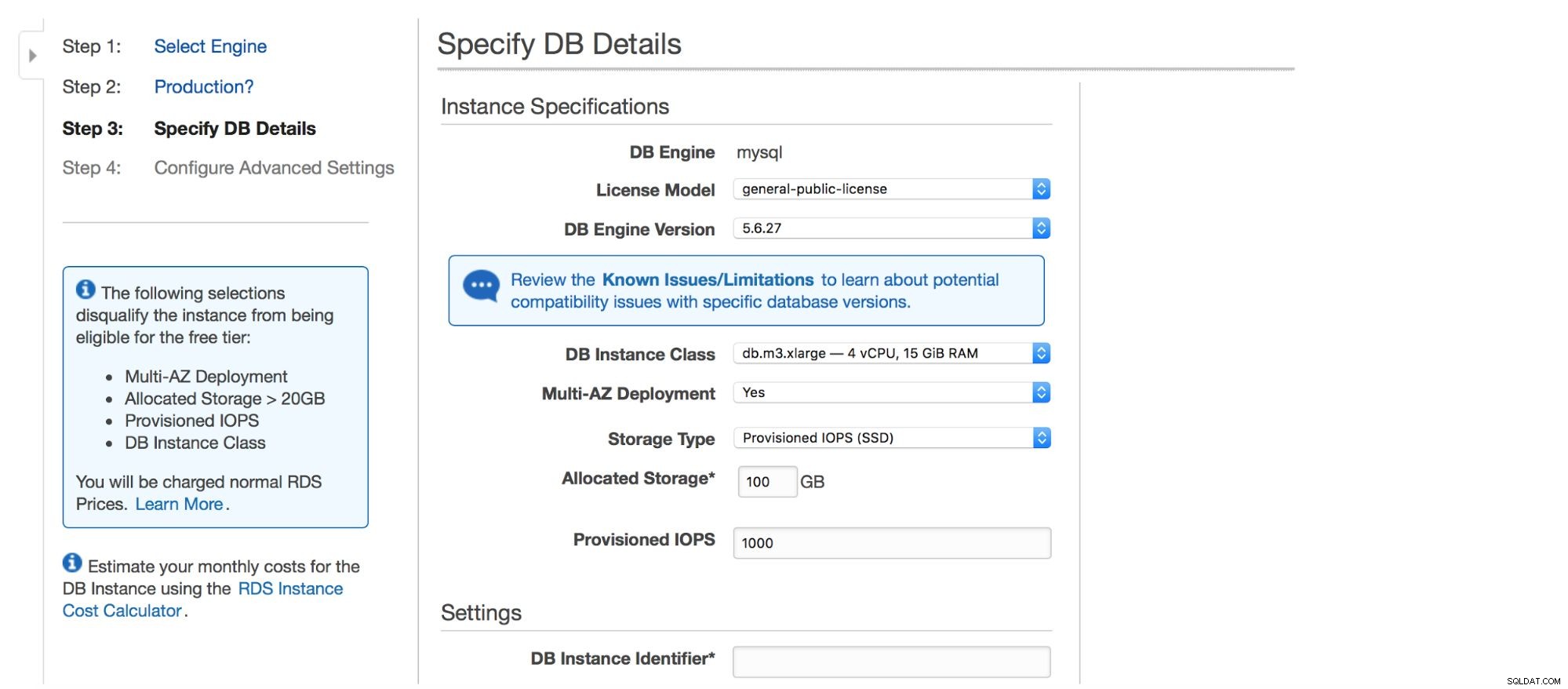
Kotak dialog berikutnya memberi kita beberapa opsi untuk menyesuaikan. Anda dapat memilih salah satu dari banyak versi MySQL - beberapa versi 5.5, 5.6 dan 5.7 tersedia. Instance database - Anda dapat memilih dari ukuran instans umum yang tersedia di wilayah tertentu.
Opsi selanjutnya adalah pilihan yang cukup penting - apakah Anda ingin menggunakan penerapan multi-AZ atau tidak? Ini semua tentang ketersediaan tinggi. Jika Anda tidak ingin menggunakan penerapan multi-AZ, satu instans akan diinstal. Jika terjadi kegagalan, yang baru akan diputar dan volume datanya akan dipasang ulang. Proses ini membutuhkan waktu, di mana database Anda tidak akan tersedia. Tentu saja, Anda dapat meminimalkan dampak ini dengan menggunakan budak dan mempromosikan salah satunya, tetapi ini bukan proses otomatis. Jika Anda ingin memiliki ketersediaan tinggi otomatis, Anda harus menggunakan penerapan multi-AZ. Apa yang akan terjadi adalah bahwa dua contoh database akan dibuat. Satu terlihat oleh Anda. Instance kedua, di zona ketersediaan terpisah, tidak terlihat oleh pengguna. Ini akan bertindak sebagai salinan bayangan, siap untuk mengambil alih lalu lintas setelah simpul aktif gagal. Ini masih bukan solusi sempurna karena lalu lintas harus dialihkan dari instance yang gagal ke instance bayangan. Dalam pengujian kami, dibutuhkan waktu ~45 detik untuk melakukan failover tetapi, tentu saja, ini mungkin bergantung pada ukuran instans, kinerja I/O, dll. Namun, ini jauh lebih baik daripada failover non-otomatis yang hanya melibatkan slave.
Terakhir, kami memiliki pengaturan penyimpanan - jenis, ukuran, PIOPS (jika berlaku) dan pengaturan basis data - pengenal, pengguna, dan kata sandi.
Pada langkah berikutnya, beberapa opsi lagi menunggu masukan pengguna.
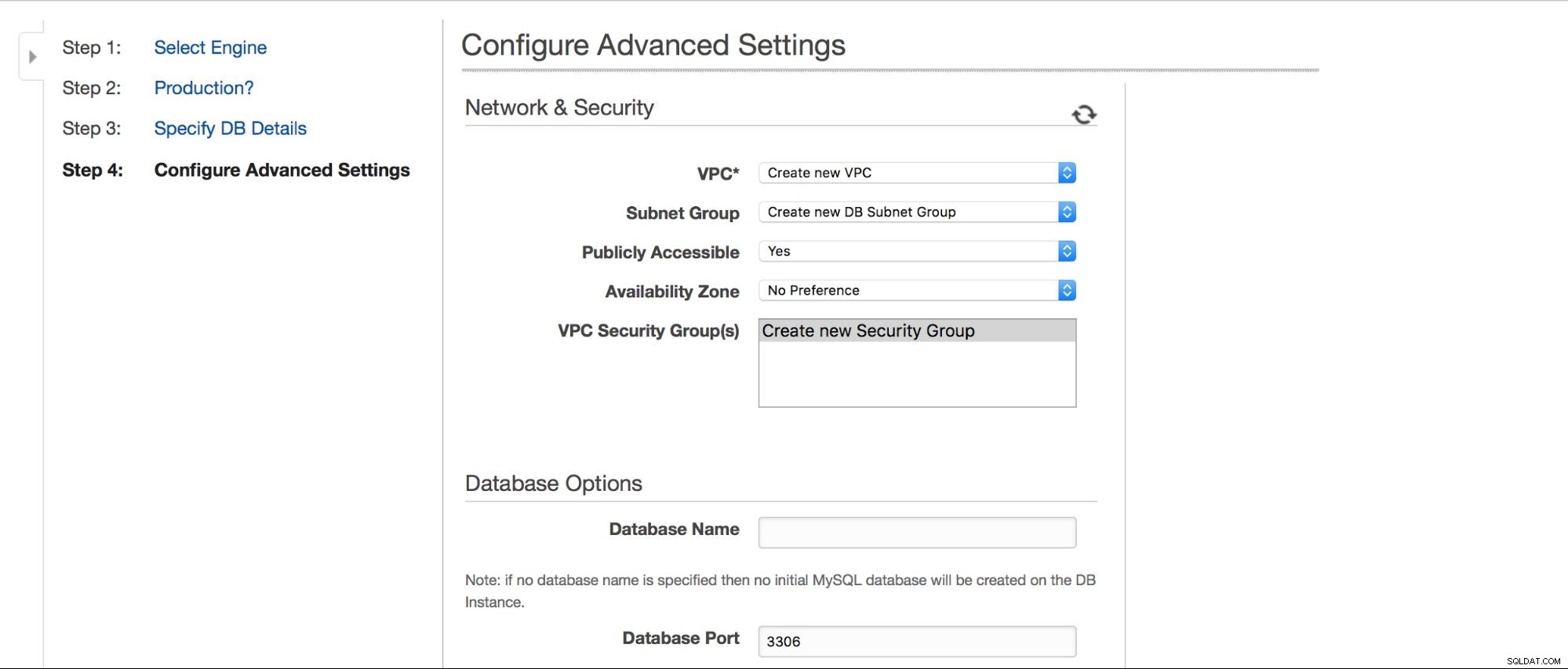
Kita dapat memilih di mana instance harus dibuat:VPC, subnet, apakah tersedia untuk umum atau tidak (seperti dalam - jika IP publik ditetapkan ke instance RDS), zona ketersediaan, dan Grup Keamanan VPC. Kemudian, kami memiliki opsi database:skema pertama yang akan dibuat, port, parameter, dan grup opsi, apakah tag metadata harus disertakan dalam snapshot atau tidak, pengaturan enkripsi.
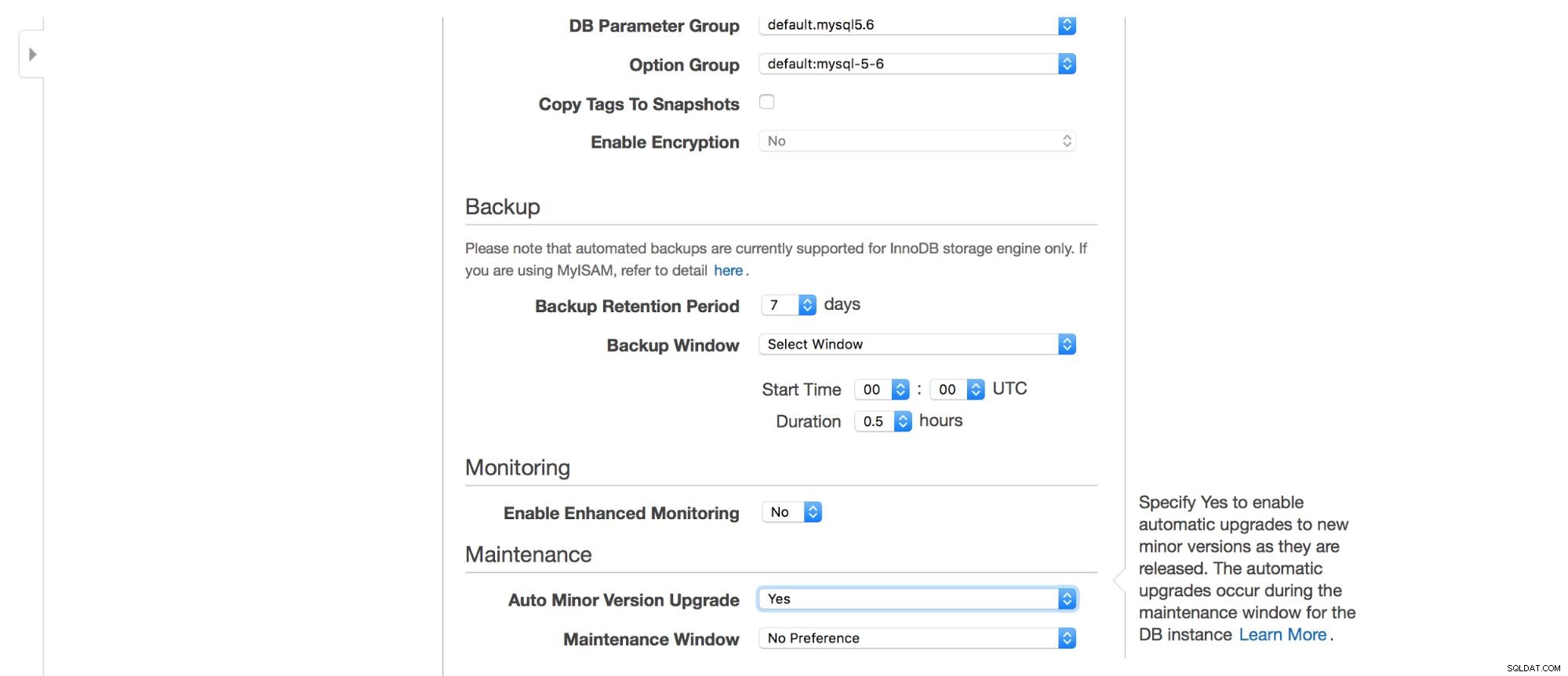
Selanjutnya, opsi pencadangan - berapa lama Anda ingin menyimpan cadangan? Kapan Anda ingin mereka diambil? Penyiapan serupa terkait dengan pemeliharaan - terkadang administrator Amazon harus melakukan pemeliharaan pada instans RDS Anda - itu akan terjadi dalam jendela yang telah ditentukan yang dapat Anda atur di sini. Harap dicatat, tidak ada opsi untuk tidak memilih setidaknya 30 menit untuk periode pemeliharaan, itulah mengapa memiliki instans multi-AZ pada produksi sangat penting. Pemeliharaan dapat mengakibatkan node restart atau kurangnya ketersediaan untuk beberapa waktu. Tanpa multi-AZ, Anda harus menerima waktu henti itu. Dengan penerapan multi-AZ, terjadi failover.
Terakhir, kami memiliki setelan yang terkait dengan pemantauan tambahan - apakah kami ingin mengaktifkannya atau tidak?
Mengelola RDS
Dalam bab ini kita akan melihat lebih dekat bagaimana mengelola MySQL RDS. Kami tidak akan membahas setiap opsi yang tersedia di luar sana, tetapi kami ingin menyoroti beberapa fitur yang disediakan Amazon.
Snapshot
MySQL RDS menggunakan volume EBS sebagai penyimpanan, sehingga dapat menggunakan snapshot EBS untuk tujuan yang berbeda. Cadangan, budak - semua berdasarkan snapshot. Anda dapat membuat snapshot secara manual atau dapat diambil secara otomatis, ketika kebutuhan tersebut muncul. Penting untuk diingat bahwa snapshot EBS, secara umum (tidak hanya pada instans RDS), menambahkan beberapa overhead ke operasi I/O. Jika Anda ingin mengambil snapshot, perkirakan kinerja I/O Anda akan turun. Kecuali jika Anda menggunakan penerapan multi-AZ, yaitu. Dalam kasus seperti itu, instans “bayangan” akan digunakan sebagai sumber snapshot dan tidak ada pengaruh yang akan terlihat pada instans produksi.
Panduan Manynines DevOps untuk Manajemen DatabasePelajari tentang apa yang perlu Anda ketahui untuk mengotomatisasi dan mengelola database open source AndaUnduh GratisCadangan
Cadangan didasarkan pada snapshot. Seperti disebutkan di atas, Anda dapat menentukan jadwal dan retensi pencadangan saat membuat instans baru. Tentu saja, Anda dapat mengedit setelan tersebut setelahnya, melalui opsi “modifikasi instance”.
Setiap saat Anda dapat memulihkan snapshot - Anda harus pergi ke bagian snapshot, memilih snapshot yang ingin Anda pulihkan, dan Anda akan disajikan dengan dialog yang mirip dengan yang Anda lihat saat membuat instance baru. Ini tidak mengejutkan karena Anda hanya dapat memulihkan snapshot ke instans baru - tidak ada cara untuk memulihkannya di salah satu instans RDS yang ada. Ini mungkin mengejutkan, tetapi bahkan di lingkungan cloud, mungkin masuk akal untuk menggunakan kembali perangkat keras (dan instans yang sudah Anda miliki). Dalam lingkungan bersama, kinerja satu instans virtual mungkin berbeda - Anda dapat memilih untuk tetap menggunakan profil kinerja yang sudah Anda kenal. Sayangnya, itu tidak mungkin di RDS.
Pilihan lain di RDS adalah pemulihan point-in-time - fitur yang sangat penting, persyaratan bagi siapa saja yang perlu menjaga datanya dengan baik. Di sini segalanya lebih kompleks dan kurang cerah. Sebagai permulaan, penting untuk diingat bahwa MySQL RDS menyembunyikan log biner dari pengguna. Anda dapat mengubah beberapa pengaturan dan membuat daftar binlog yang dibuat, tetapi Anda tidak memiliki akses langsung ke sana - untuk melakukan operasi apa pun, termasuk menggunakannya untuk pemulihan, Anda hanya dapat menggunakan UI atau CLI. Ini membatasi pilihan Anda untuk apa yang Amazon memungkinkan Anda lakukan, dan memungkinkan Anda untuk memulihkan cadangan Anda hingga "waktu pemulihan" terbaru yang kebetulan dihitung dalam interval 5 menit. Jadi, jika data Anda telah dihapus pada 9:33a, Anda dapat mengembalikannya hanya hingga keadaan pada 9:30a. Pemulihan point-in-time bekerja dengan cara yang sama seperti memulihkan snapshot - sebuah instance baru dibuat.
Skala, replikasi
MySQL RDS memungkinkan scale-out dengan menambahkan slave baru. Saat slave dibuat, snapshot master diambil dan digunakan untuk membuat host baru. Bagian ini bekerja dengan cukup baik. Sayangnya, Anda tidak dapat membuat topologi replikasi yang lebih kompleks seperti yang melibatkan master perantara. Anda tidak dapat membuat pengaturan master - master, yang meninggalkan HA apa pun di tangan Amazon (dan penerapan multi-AZ). Dari apa yang kami ketahui, tidak ada cara untuk mengaktifkan GTID (bukan karena Anda dapat mengambil manfaat darinya karena Anda tidak memiliki kendali atas replikasi, tidak ada CHANGE MASTER di RDS), hanya posisi binlog biasa dan kuno.
Kurangnya GTID membuatnya tidak layak untuk menggunakan replikasi multithreaded - sementara dimungkinkan untuk mengatur sejumlah pekerja menggunakan grup parameter RDS, tanpa GTID ini tidak dapat digunakan. Masalah utama adalah bahwa tidak ada cara untuk menemukan satu posisi log biner jika terjadi crash - beberapa pekerja mungkin berada di belakang, beberapa bisa lebih maju. Jika Anda menggunakan peristiwa terbaru yang diterapkan, Anda akan kehilangan data yang belum diterapkan oleh pekerja "tertinggal" tersebut. Jika Anda akan menggunakan acara terlama, kemungkinan besar Anda akan berakhir dengan kesalahan "kunci duplikat" yang disebabkan oleh peristiwa yang diterapkan oleh pekerja yang lebih maju. Tentu saja, ada cara untuk mengatasi masalah ini, tetapi ini tidak sepele dan memakan waktu - jelas bukan sesuatu yang dapat Anda otomatisasi dengan mudah.
Pengguna yang dibuat di MySQL RDS tidak memiliki hak istimewa SUPER sehingga operasi, yang sederhana di MySQL yang berdiri sendiri, tidak sepele di RDS. Amazon memutuskan untuk menggunakan prosedur tersimpan untuk memberdayakan pengguna melakukan beberapa operasi tersebut. Dari apa yang kami ketahui, sejumlah masalah potensial tercakup meskipun tidak selalu demikian - kami ingat ketika Anda tidak dapat memutar ke log biner berikutnya pada master. Master crash + binlog corrupt dapat membuat semua slave rusak - sekarang ada prosedur untuk itu:rds_next_master_log .
Seorang budak dapat secara manual dipromosikan menjadi master. Ini akan memungkinkan Anda untuk membuat semacam HA di atas mekanisme multi-AZ (atau melewatinya) tetapi telah dibuat sia-sia oleh fakta bahwa Anda tidak dapat mereslave salah satu budak yang ada ke master baru. Ingat, Anda tidak memiliki kendali atas replikasi. Ini membuat seluruh latihan menjadi sia-sia - kecuali jika master Anda dapat mengakomodasi semua lalu lintas Anda. Setelah mempromosikan master baru, Anda tidak dapat melakukan failover ke sana karena tidak memiliki budak untuk menangani beban Anda. Memutar budak baru akan memakan waktu karena snapshot EBS harus dibuat terlebih dahulu dan ini mungkin memakan waktu berjam-jam. Kemudian, Anda perlu memanaskan infrastruktur sebelum dapat memuatnya.
Kurangnya Hak Istimewa SUPER
Seperti yang kami nyatakan sebelumnya, RDS tidak memberikan hak istimewa SUPER kepada pengguna dan ini menjadi menjengkelkan bagi seseorang yang terbiasa memilikinya di MySQL. Anggap saja bahwa, dalam minggu-minggu pertama, Anda akan mempelajari seberapa sering diperlukan untuk melakukan hal-hal yang lebih sering Anda lakukan - seperti mematikan kueri atau mengoperasikan skema kinerja. Di RDS, Anda harus tetap berpegang pada daftar prosedur tersimpan yang telah ditentukan sebelumnya dan menggunakannya alih-alih melakukan sesuatu secara langsung. Anda dapat membuat daftar semuanya menggunakan kueri berikut:
SELECT specific_name FROM information_schema.routines;Seperti halnya replikasi, sejumlah tugas tercakup tetapi jika Anda berakhir dalam situasi yang belum tercakup, maka Anda kurang beruntung.
Interoperabilitas dan Penyiapan Cloud Hibrida
Ini adalah area lain di mana RDS kurang fleksibel. Katakanlah Anda ingin membangun pengaturan cloud/on-premises campuran - Anda memiliki infrastruktur RDS dan Anda ingin membuat beberapa slave di tempat. Masalah utama yang akan Anda hadapi adalah bahwa tidak ada cara untuk memindahkan data dari RDS kecuali mengambil dump logis. Anda dapat mengambil snapshot data RDS tetapi Anda tidak memiliki akses ke sana dan Anda tidak dapat memindahkannya dari AWS. Anda juga tidak memiliki akses fisik ke instans untuk menggunakan xtrabackup, rsync, atau bahkan cp. Satu-satunya pilihan bagi Anda adalah menggunakan mysqldump, mydumper atau alat serupa. Hal ini menambah kerumitan (pengaturan kumpulan karakter dan susunan berpotensi menyebabkan masalah) dan memakan waktu (perlu waktu lama untuk membuang dan memuat data menggunakan alat pencadangan logis).
Dimungkinkan untuk menyiapkan replikasi antara RDS dan instans eksternal (dalam kedua cara, jadi migrasi data ke RDS juga dimungkinkan), tetapi ini bisa menjadi proses yang sangat memakan waktu.
Di sisi lain, jika Anda ingin tetap berada dalam lingkungan RDS dan menjangkau infrastruktur Anda melintasi Atlantik atau dari timur ke pantai barat AS, RDS memungkinkan Anda melakukannya - Anda dapat dengan mudah memilih wilayah saat Anda membuat budak baru.
Sayangnya, jika Anda ingin memindahkan master dari satu wilayah ke wilayah lain, ini hampir tidak mungkin dilakukan tanpa waktu henti - kecuali satu node Anda dapat menangani semua lalu lintas Anda.
Keamanan
Meskipun MySQL RDS adalah layanan terkelola, tidak semua aspek yang terkait dengan keamanan ditangani oleh para insinyur Amazon. Amazon menyebutnya "Model Tanggung Jawab Bersama". Singkatnya, Amazon menjaga keamanan jaringan dan lapisan penyimpanan (agar data ditransfer dengan cara yang aman), sistem operasi (tambalan, perbaikan keamanan). Di sisi lain, pengguna harus menjaga model keamanan lainnya. Pastikan lalu lintas ke dan dari instans RDS dibatasi dalam VPC, pastikan otentikasi tingkat basis data dilakukan dengan benar (tidak ada akun pengguna MySQL tanpa kata sandi), verifikasi bahwa keamanan API dipastikan (AMI diatur dengan benar dan dengan hak istimewa minimal yang diperlukan). Pengguna juga harus menjaga pengaturan firewall (grup keamanan) untuk meminimalkan paparan RDS dan VPC-nya ke jaringan eksternal. Pengguna juga bertanggung jawab untuk menerapkan enkripsi data saat tidak digunakan - baik di tingkat aplikasi atau di tingkat database, dengan membuat instance RDS terenkripsi terlebih dahulu.
Enkripsi tingkat basis data hanya dapat diaktifkan pada pembuatan instans, Anda tidak dapat mengenkripsi basis data yang sudah ada dan berjalan.
Batasan RDS
Jika Anda berencana untuk menggunakan RDS atau jika Anda sudah menggunakannya, Anda harus mengetahui batasan yang menyertai RDS MySQL.
Kurangnya hak istimewa SUPER bisa, seperti yang kami sebutkan, sangat mengganggu. Sementara prosedur tersimpan menangani sejumlah operasi, ini adalah kurva pembelajaran karena Anda perlu belajar melakukan sesuatu dengan cara yang berbeda. Kurangnya hak istimewa SUPER juga dapat menimbulkan masalah dalam menggunakan alat pemantauan dan tren eksternal - masih ada beberapa alat yang mungkin memerlukan hak istimewa ini untuk sebagian fungsinya.
Kurangnya akses langsung ke direktori dan log data MySQL membuat tindakan menjadi lebih sulit yang melibatkan mereka. Itu terjadi sesekali bahwa DBA perlu mengurai log biner atau kesalahan ekor, kueri lambat, atau log umum. Meskipun dimungkinkan untuk mengakses log tersebut di RDS, ini lebih rumit daripada melakukan apa pun yang Anda perlukan dengan masuk ke shell di host MySQL. Mengunduhnya secara lokal juga membutuhkan waktu dan menambahkan latensi tambahan untuk apa pun yang Anda lakukan.
Kurangnya kontrol atas topologi replikasi, ketersediaan tinggi hanya dalam penerapan multi-AZ. Karena Anda tidak memiliki kendali atas replikasi, Anda tidak dapat menerapkan mekanisme ketersediaan tinggi apa pun ke dalam lapisan basis data Anda. Tidak masalah jika Anda memiliki beberapa budak, Anda tidak dapat menggunakan beberapa dari mereka sebagai kandidat master karena bahkan jika Anda mempromosikan seorang budak menjadi seorang master, tidak ada cara untuk membebaskan budak yang tersisa dari master baru ini. Ini memaksa pengguna untuk menggunakan penerapan multi-AZ dan meningkatkan biaya (instance "bayangan" tidak gratis, pengguna harus membayarnya).
Pengurangan ketersediaan melalui waktu henti yang direncanakan. Saat menerapkan instans RDS, Anda dipaksa untuk memilih jendela waktu mingguan 30 menit selama operasi pemeliharaan dapat dijalankan pada instans RDS Anda. Di satu sisi, ini dapat dimengerti karena RDS adalah Database as a Service sehingga peningkatan perangkat keras dan perangkat lunak instans RDS Anda dikelola oleh teknisi AWS. Di sisi lain, ini mengurangi ketersediaan Anda karena Anda tidak dapat mencegah database master Anda turun selama periode pemeliharaan. Sekali lagi, dalam hal ini menggunakan pengaturan multi-AZ meningkatkan ketersediaan karena perubahan terjadi pertama kali pada instance bayangan dan kemudian failover dijalankan. Namun, failover itu sendiri tidak transparan sehingga, dengan satu atau lain cara, Anda kehilangan waktu aktif. Ini memaksa Anda untuk mendesain aplikasi Anda dengan mempertimbangkan kegagalan master MySQL yang tidak terduga. Bukannya itu pola desain yang buruk - database dapat mogok kapan saja dan aplikasi Anda harus dibangun sedemikian rupa sehingga dapat bertahan bahkan dalam skenario yang paling mengerikan sekalipun. Hanya saja dengan RDS, Anda memiliki opsi terbatas untuk ketersediaan tinggi.
Opsi yang dikurangi untuk penerapan ketersediaan tinggi. Mengingat kurangnya fleksibilitas dalam manajemen topologi replikasi, satu-satunya metode ketersediaan tinggi yang layak adalah penerapan multi-AZ. Metode ini bagus tetapi ada alat untuk replikasi MySQL yang akan meminimalkan waktu henti lebih jauh. Misalnya, MHA atau ClusterControl ketika digunakan sehubungan dengan ProxySQL dapat memberikan (dalam beberapa kondisi seperti kurangnya transaksi yang berjalan lama) proses failover transparan untuk aplikasi. Saat menggunakan RDS, Anda tidak akan dapat menggunakan metode ini.
Pengurangan wawasan tentang kinerja database Anda. Meskipun Anda bisa mendapatkan metrik dari MySQL itu sendiri, terkadang itu tidak cukup untuk mendapatkan tampilan 10 ribu kaki penuh dari situasi tersebut. Pada titik tertentu, sebagian besar pengguna harus berurusan dengan masalah yang sangat aneh yang disebabkan oleh perangkat keras yang rusak atau infrastruktur yang salah - paket jaringan yang hilang, koneksi yang terputus secara tiba-tiba, atau penggunaan CPU yang tinggi secara tak terduga. Ketika Anda memiliki akses ke host MySQL Anda, Anda dapat memanfaatkan banyak alat yang membantu Anda mendiagnosis status server Linux. Saat menggunakan RDS, Anda terbatas pada metrik apa yang tersedia di Cloudwatch, alat pemantauan dan tren Amazon. Diagnosis yang lebih rinci memerlukan menghubungi dukungan dan meminta mereka untuk memeriksa dan memperbaiki masalah. Ini mungkin cepat tetapi juga bisa menjadi proses yang sangat panjang dengan banyak komunikasi email bolak-balik.
Penguncian vendor disebabkan oleh proses yang rumit dan memakan waktu untuk mengeluarkan data dari RDS MySQL. RDS tidak memberikan akses ke direktori data MySQL sehingga tidak ada cara untuk menggunakan alat standar industri seperti xtrabackup untuk memindahkan data dengan cara biner. Di sisi lain, RDS di bawah tenda adalah MySQL yang dikelola oleh Amazon, sulit untuk mengetahui apakah itu 100% kompatibel dengan upstream atau tidak. RDS hanya tersedia di AWS, jadi Anda tidak akan dapat melakukan penyiapan hibrid.
Ringkasan
MySQL RDS memiliki kekuatan dan kelemahan. Ini adalah alat yang sangat bagus bagi mereka yang ingin fokus pada aplikasi tanpa harus khawatir mengoperasikan database. Anda menyebarkan database dan mulai mengeluarkan kueri. Tidak perlu membuat skrip cadangan atau menyiapkan solusi pemantauan karena sudah dilakukan oleh teknisi AWS - Anda hanya perlu menggunakannya.
Ada juga sisi gelap dari RDS MySQL. Kurangnya opsi untuk membangun pengaturan yang lebih kompleks dan penskalaan di luar hanya menambahkan lebih banyak budak. Kurangnya dukungan untuk ketersediaan tinggi yang lebih baik daripada yang diusulkan dalam penerapan multi-AZ. Akses rumit ke log MySQL. Kurangnya akses langsung ke direktori data MySQL dan kurangnya dukungan untuk pencadangan fisik, yang mempersulit pemindahan data dari instans RDS.
Singkatnya, RDS dapat bekerja dengan baik untuk Anda jika Anda menghargai kemudahan penggunaan daripada kontrol database yang terperinci. Anda perlu mengingat bahwa, di beberapa titik di masa mendatang, Anda mungkin akan melampaui MySQL RDS. Kami tidak harus berbicara di sini tentang kinerja saja. Ini lebih tentang kebutuhan organisasi Anda untuk topologi replikasi yang lebih kompleks atau kebutuhan untuk memiliki wawasan yang lebih baik tentang operasi database untuk menangani dengan cepat berbagai masalah yang muncul dari waktu ke waktu. Dalam hal ini, jika kumpulan data Anda sudah bertambah besar, Anda mungkin merasa sulit untuk keluar dari RDS. Sebelum membuat keputusan apa pun untuk memindahkan data Anda ke RDS, manajer informasi harus mempertimbangkan persyaratan dan batasan organisasi mereka di area tertentu.
Dalam beberapa posting blog berikutnya kami akan menunjukkan kepada Anda bagaimana mengambil data Anda dari RDS ke lokasi yang terpisah. Kami akan membahas migrasi ke EC2 dan infrastruktur lokal.