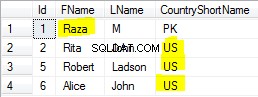
Cara mudah untuk melakukannya adalah dengan membuat penganalisis khusus yang menggunakan filter token n-gram
untuk email (=> lihat di bawah index_email_analyzer dan search_email_analyzer + email_url_analyzer untuk pencocokan email yang tepat) dan edge-ngram penyaring token
untuk ponsel (=> lihat di bawah index_phone_analyzer dan search_phone_analyzer ).
Definisi indeks lengkap tersedia di bawah ini.
PUT myindex
{
"settings": {
"analysis": {
"analyzer": {
"email_url_analyzer": {
"type": "custom",
"tokenizer": "uax_url_email",
"filter": [ "trim" ]
},
"index_phone_analyzer": {
"type": "custom",
"char_filter": [ "digit_only" ],
"tokenizer": "digit_edge_ngram_tokenizer",
"filter": [ "trim" ]
},
"search_phone_analyzer": {
"type": "custom",
"char_filter": [ "digit_only" ],
"tokenizer": "keyword",
"filter": [ "trim" ]
},
"index_email_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [ "lowercase", "name_ngram_filter", "trim" ]
},
"search_email_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [ "lowercase", "trim" ]
}
},
"char_filter": {
"digit_only": {
"type": "pattern_replace",
"pattern": "\\D+",
"replacement": ""
}
},
"tokenizer": {
"digit_edge_ngram_tokenizer": {
"type": "edgeNGram",
"min_gram": "1",
"max_gram": "15",
"token_chars": [ "digit" ]
}
},
"filter": {
"name_ngram_filter": {
"type": "ngram",
"min_gram": "1",
"max_gram": "20"
}
}
}
},
"mappings": {
"your_type": {
"properties": {
"email": {
"type": "string",
"analyzer": "index_email_analyzer",
"search_analyzer": "search_email_analyzer"
},
"phone": {
"type": "string",
"analyzer": "index_phone_analyzer",
"search_analyzer": "search_phone_analyzer"
}
}
}
}
}
Sekarang, mari kita bedah satu demi satu.
Untuk phone bidang, idenya adalah untuk mengindeks nilai ponsel dengan index_phone_analyzer , yang menggunakan tokenizer edge-ngram untuk mengindeks semua awalan nomor telepon. Jadi jika nomor telepon Anda adalah 1362435647 , token berikut akan dihasilkan:1 , 13 , 136 , 1362 , 13624 , 136243 , 1362435 , 13624356 , 13624356 , 136243564 , 1362435647 .
Kemudian saat mencari kami menggunakan penganalisis lain search_phone_analyzer yang hanya akan mengambil nomor input (mis. 136 ) dan cocokkan dengan phone kolom menggunakan match simple sederhana atau term permintaan:
POST myindex
{
"query": {
"term":
{ "phone": "136" }
}
}
Untuk email bidang, kami melanjutkan dengan cara yang sama, di mana kami mengindeks nilai email dengan index_email_analyzer , yang menggunakan filter token ngram, yang akan menghasilkan semua kemungkinan token dengan panjang yang bervariasi (antara 1 dan 20 karakter) yang dapat diambil dari nilai email. Misalnya:example@sqldat.com akan diberi token menjadi j , jo , joh , ..., gmail.com , ..., example@sqldat.com .
Kemudian saat mencari, kita akan menggunakan penganalisis lain yang disebut search_email_analyzer yang akan mengambil input dan mencoba mencocokkannya dengan token yang diindeks.
POST myindex
{
"query": {
"term":
{ "email": "@gmail.com" }
}
}
email_url_analyzer analyzer tidak digunakan dalam contoh ini tetapi saya telah menyertakannya untuk berjaga-jaga jika Anda perlu mencocokkan nilai email yang tepat.