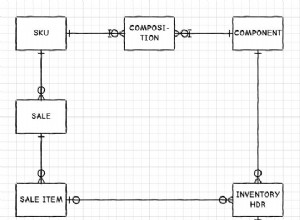
Untuk keterbacaan, saya menyusun ulang kueri... dimulai dengan level paling atas yang terlihat adalah Tabel1, yang kemudian terkait dengan Tabel3, dan kemudian tabel3 terkait dengan tabel2. Jauh lebih mudah diikuti jika Anda mengikuti rantai hubungan.
Sekarang, untuk menjawab pertanyaan Anda. Anda mendapatkan jumlah besar sebagai hasil dari produk Cartesian. Untuk setiap record pada Tabel1 yang cocok dengan Tabel3 Anda akan memiliki X * Y. Kemudian, untuk setiap kecocokan antara tabel3 dan Tabel2 akan memiliki dampak yang sama... Y * Z... Jadi hasil Anda hanya untuk satu kemungkinan ID di tabel 1 dapat memiliki catatan X * Y * Z.
Ini didasarkan pada tidak mengetahui bagaimana normalisasi atau konten untuk tabel Anda... apakah kuncinya adalah kunci UTAMA atau bukan..
Ex:
Table 1
DiffKey Other Val
1 X
1 Y
1 Z
Table 3
DiffKey Key Key2 Tbl3 Other
1 2 6 V
1 2 6 X
1 2 6 Y
1 2 6 Z
Table 2
Key Key2 Other Val
2 6 a
2 6 b
2 6 c
2 6 d
2 6 e
Jadi, Tabel 1 bergabung dengan Tabel 3 akan menghasilkan (dalam skenario ini) dengan 12 catatan (masing-masing dalam 1 bergabung dengan masing-masing dalam 3). Kemudian, semua itu lagi kali setiap catatan yang cocok di tabel 2 (5 catatan)... total 60 ( 3 tbl1 * 4 tbl3 * 5 tbl2 )hitung akan dikembalikan.
Jadi, sekarang, ambil dan kembangkan berdasarkan 1000 catatan Anda dan Anda akan melihat bagaimana struktur yang kacau dapat mencekik seekor sapi (bisa dikatakan demikian) dan membunuh kinerja.
SELECT
COUNT(*)
FROM
Table1
INNER JOIN Table3
ON Table1.DifferentKey = Table3.DifferentKey
INNER JOIN Table2
ON Table3.Key =Table2.Key
AND Table3.Key2 = Table2.Key2