Meskipun baik untuk bertanya-tanya tentang bagaimana hal itu dapat dijelaskan bahwa Anda sering melihat urutan yang sama, saya ingin menunjukkan bahwa tidak pernah merupakan ide yang baik untuk mengandalkan urutan implisit yang disebabkan oleh implementasi tertentu dari mesin database yang mendasarinya. Dengan kata lain, senang mengetahui alasannya, tetapi Anda tidak boleh bergantung padanya. Untuk MS SQL, satu-satunya hal yang andal mengirimkan baris dalam urutan tertentu, adalah ORDER BY eksplisit klausa.
Tidak hanya RDMBS-es yang berbeda berperilaku berbeda, satu instance tertentu dapat berperilaku berbeda karena pembaruan (tambalan). Tidak hanya itu, bahkan status perangkat lunak RDBMS dapat berdampak:database "hangat" berperilaku berbeda dari database "dingin", tabel kecil berperilaku berbeda dari yang besar.
Bahkan jika Anda memiliki informasi latar belakang tentang implementasi (mis:"ada indeks berkerumun, sehingga kemungkinan data akan dikembalikan berdasarkan urutan indeks berkerumun"), selalu ada kemungkinan bahwa ada mekanisme lain yang tidak Anda lakukan. t tahu tentang itu menyebabkan baris dikembalikan dalam urutan yang berbeda (mis1:"jika sesi lain baru saja melakukan pemindaian tabel penuh dengan ORDER BY eksplisit hasil mungkin telah di-cache; pemindaian penuh berikutnya akan mencoba mengembalikan baris dari cache"; ex2:"a GROUP BY dapat diimplementasikan dengan menyortir data, sehingga memengaruhi urutan baris yang dikembalikan"; ex3:"Jika kolom yang dipilih semuanya ada dalam indeks sekunder yang sudah di-cache di memori, mesin dapat memindai indeks sekunder alih-alih tabel, kemungkinan besar mengembalikan baris berdasarkan urutan indeks sekunder").
Berikut adalah tes yang sangat sederhana yang menggambarkan beberapa poin saya.
Pertama, mulai SQL server (saya menggunakan 2008). Buat tabel ini:
create table test_order (
id int not null identity(1,1) primary key
, name varchar(10) not null
)
Periksa tabel dan saksikan bahwa indeks berkerumun dibuat untuk mendukung primary key pada id kolom. Misalnya, di studio manajemen server sql, Anda dapat menggunakan tampilan hierarki dan menavigasi ke folder indeks di bawah tabel Anda. Di sana Anda akan melihat satu indeks, dengan nama seperti:PK__test_ord__3213E83F03317E3D (Clustered)
Sisipkan baris pertama dengan pernyataan ini:
insert into test_order(name)
select RAND()
Sisipkan lebih banyak baris dengan mengulangi pernyataan ini sebanyak 16 kali:
insert into test_order(name)
select RAND()
from test_order
Anda sekarang harus memiliki 65536 baris:
select COUNT(*)
from test_order
Sekarang, pilih semua baris tanpa menggunakan perintah dengan:
select *
from test_order
Kemungkinan besar, hasilnya akan dikembalikan berdasarkan urutan kunci utama (walaupun tidak ada jaminan). Berikut hasil yang saya dapatkan (yang memang berdasarkan urutan primary key):
# id name
1 1 0.605831
2 2 0.517251
3 3 0.52326
. . .......
65536 65536 0.902214
(# bukan kolom tetapi posisi ordinal baris dalam hasil)
Sekarang, buat indeks sekunder pada name kolom:
create index idx_name on test_order(name)
Pilih semua baris, tetapi ambil hanya name kolom:
select name
from test_order
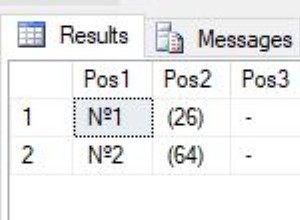
Kemungkinan besar hasilnya akan dikembalikan berdasarkan urutan indeks sekunder idx_name, karena kueri dapat diselesaikan hanya dengan memindai indeks (i.o.w. idx_name adalah penutup indeks). Inilah hasil yang saya dapatkan, yang memang atas perintah name .
# name
1 0.0185732
2 0.0185732
. .........
65536 0.981894
Sekarang, pilih semua kolom dan semua baris lagi:
select *
from test_order
Inilah hasil yang saya dapatkan:
# id name
1 17 0.0185732
2 18 0.0185732
3 19 0.0185732
... .. .........
seperti yang Anda lihat, sangat berbeda dari pertama kali kami menjalankan kueri ini. (Sepertinya baris diurutkan oleh indeks sekunder, tetapi saya tidak memiliki penjelasan mengapa harus demikian).
Bagaimanapun, intinya adalah - jangan mengandalkan pesanan implisit. Anda dapat memikirkan penjelasan mengapa urutan tertentu dapat diamati, tetapi meskipun demikian Anda tidak selalu dapat memprediksinya (seperti dalam kasus terakhir) tanpa memiliki pengetahuan mendalam tentang implementasi dan status runtime.