
Indeks SQL Server digunakan untuk membantu mengambil data lebih cepat dan mengurangi kemacetan yang berdampak pada sumber daya penting. Indeks pada tabel database berfungsi sebagai teknik pengoptimalan performa. Anda mungkin bertanya-tanya – bagaimana indeks meningkatkan kinerja kueri? Apakah ada indeks yang baik dan buruk? Misalkan Anda memiliki tabel dengan 50 kolom, apakah ide yang baik untuk membuat indeks pada setiap kolom? Jika kita membuat beberapa indeks, apakah itu membantu kueri SQL berjalan lebih cepat?
Semua pertanyaan bagus, tetapi sebelum kita menyelami, penting untuk mengetahui mengapa indeks mungkin diperlukan sejak awal.
Bayangkan Anda mengunjungi perpustakaan kota yang memiliki ribuan koleksi buku. Anda sedang mencari buku tertentu, tetapi bagaimana Anda akan menemukannya? Jika Anda membaca setiap buku, di setiap rak, bisa memakan waktu berhari-hari untuk menemukannya. Hal yang sama berlaku untuk database saat Anda mencari catatan dari jutaan baris yang disimpan dalam tabel.
Indeks SQL Server dibentuk dalam format B-Tree yang terdiri dari simpul akar di bagian atas dan simpul daun di bagian bawah. Untuk contoh buku perpustakaan kami, pengguna mengeluarkan kueri untuk mencari buku dengan ID 391. Dalam kasus ini, mesin kueri mulai melintasi dari simpul akar dan berpindah ke simpul daun.
Root Node –> Intermediate node –> Leaf node.
Mesin kueri mencari halaman referensi di tingkat menengah. Dalam contoh ini, simpul perantara pertama terdiri dari ID buku dari 1-500 dan simpul perantara kedua terdiri dari 501-1000.
Berdasarkan node perantara, mesin kueri melintasi B-Tree untuk mencari node perantara yang sesuai dan node daun. Node daun ini dapat terdiri dari data aktual atau menunjuk ke halaman data aktual berdasarkan jenis indeks. Pada gambar di bawah ini, kita melihat cara melintasi indeks untuk mencari data menggunakan indeks SQL Server. Dalam hal ini, SQL Server tidak harus menelusuri setiap halaman, membacanya, dan mencari konten ID buku tertentu.
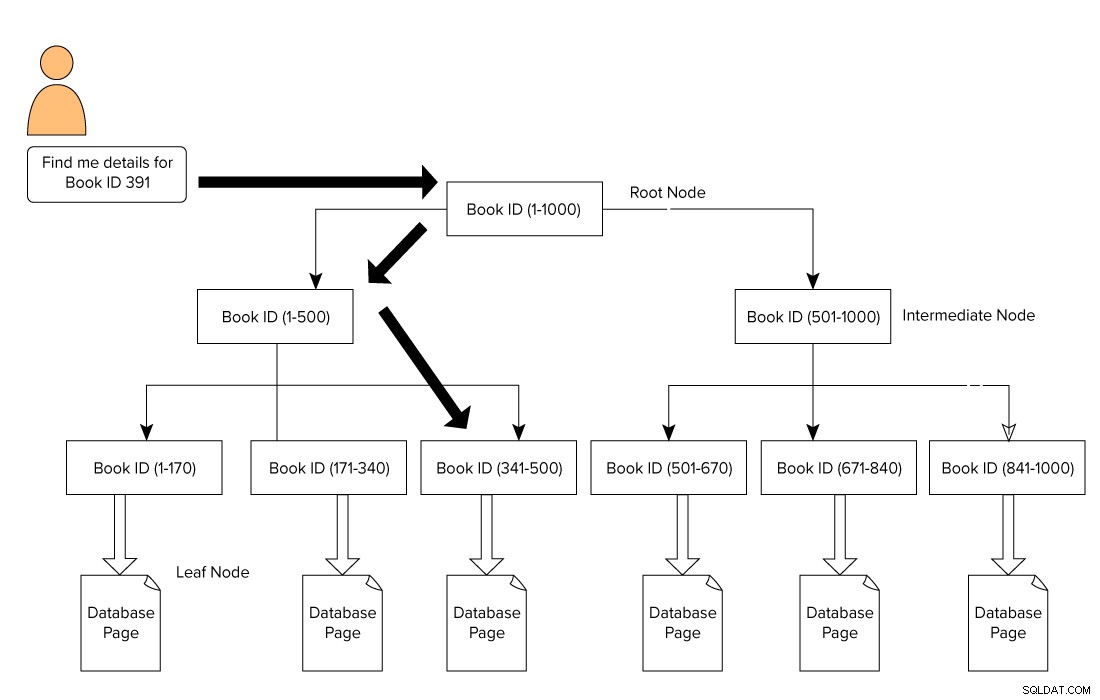
Dampak indeks pada kinerja SQL Server
Dalam contoh perpustakaan sebelumnya, kami memeriksa potensi dampak kinerja indeks. Mari kita lihat kinerja kueri dengan dan tanpa indeks.
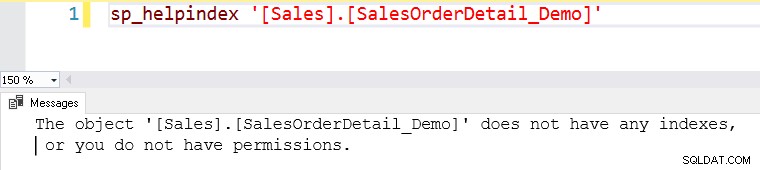
Misalkan kita memerlukan data untuk [SalesOrderID] 56958 dari tabel [SalesOrderDetail_Demo].
PILIH *
FROM [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
di mana SalesOrderID=56958
Tabel ini tidak memiliki indeks di atasnya. Tabel tanpa indeks disebut tabel heap di SQL Server.
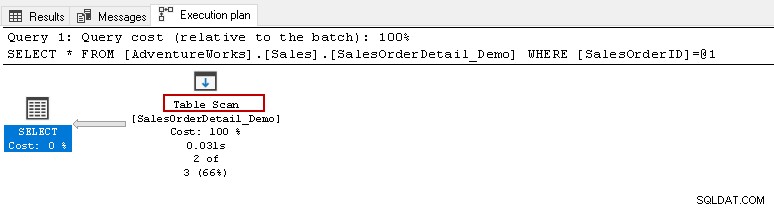
Dari sini, Anda ingin menjalankan pernyataan pilih di atas dan melihat rencana eksekusi yang sebenarnya. Tabel ini memiliki 121317 record di dalamnya. Ini melakukan pemindaian tabel, yang berarti membaca semua baris dalam tabel untuk menemukan [SalesOrderID] tertentu.
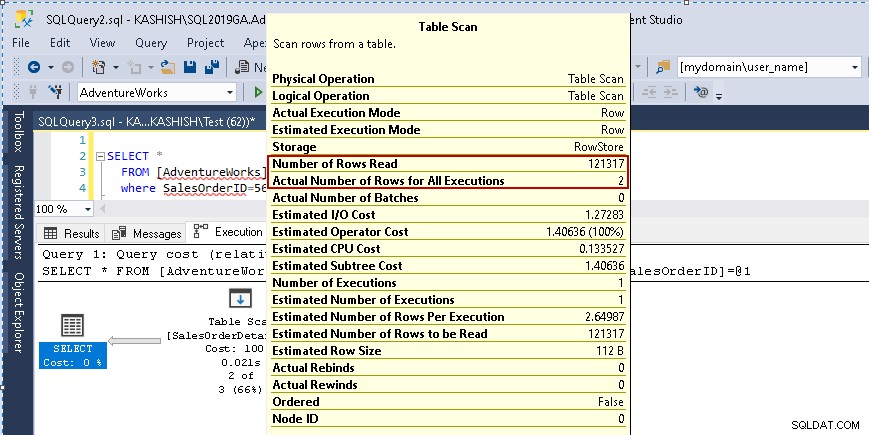
Saat Anda mengarahkan kursor ke ikon Pemindaian Tabel, ini menunjukkan bahwa kumpulan hasil aktual berisi 2 baris, tetapi untuk tujuan ini, ia membaca semua baris dalam tabel itu.
- Jumlah baris yang dibaca:121317
- Jumlah baris aktual untuk eksekusi:2
Sekarang, pikirkan tabel dengan jutaan atau miliaran baris. Bukan praktik yang baik untuk melintasi semua catatan dalam tabel untuk memfilter beberapa baris. Dalam sistem database pemrosesan transaksi online (OLTP) ekstensif, tidak menggunakan sumber daya server (CPU, IO, memori) secara efektif, oleh karena itu, pengguna dapat menghadapi masalah kinerja.
Sekarang, mari kita jalankan pernyataan pilih di atas dengan tabel yang memiliki indeks. Tabel ini memiliki indeks berkerumun kunci utama dan dua indeks yang tidak berkerumun pada kolom [ProductID] dan [rowguid]. Kita akan berbicara nanti tentang berbagai jenis indeks di SQL Server.
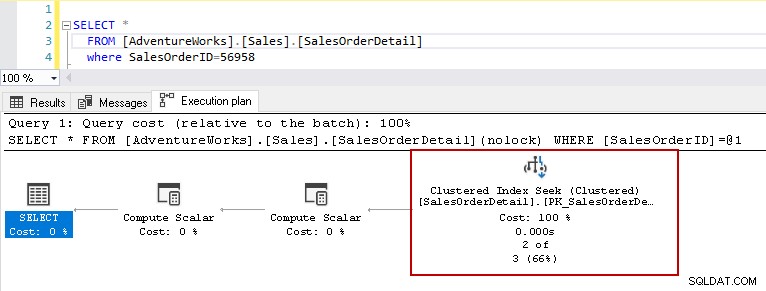
Sekarang, jika Anda menjalankan kembali pernyataan pilih dengan predikat yang sama, rencana eksekusi menunjukkan masalah kinerja. Pengoptimal kueri memutuskan untuk menggunakan pencarian indeks berkerumun sebagai ganti pemindaian indeks berkerumun.
Dalam detail pencarian indeks berkerumun, ini menunjukkan pengoptimal kueri secara tepat membaca baris yang diberikannya dalam output.
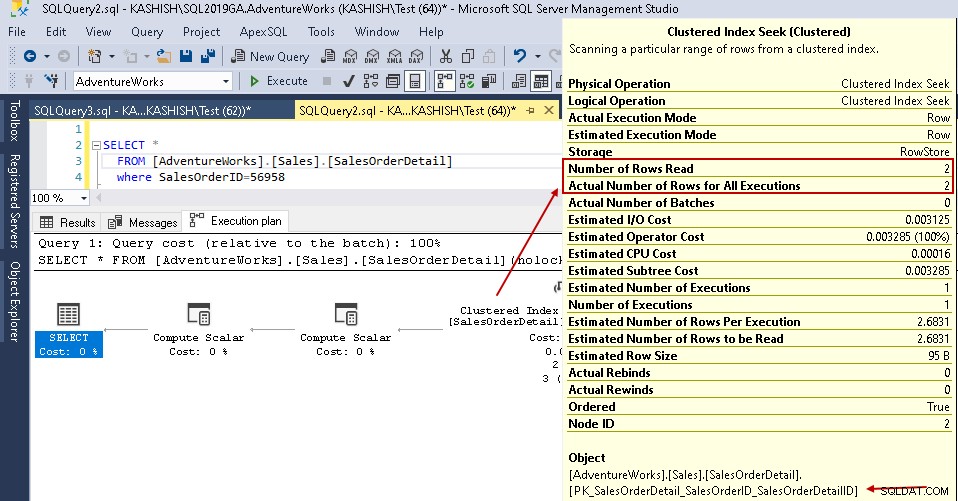
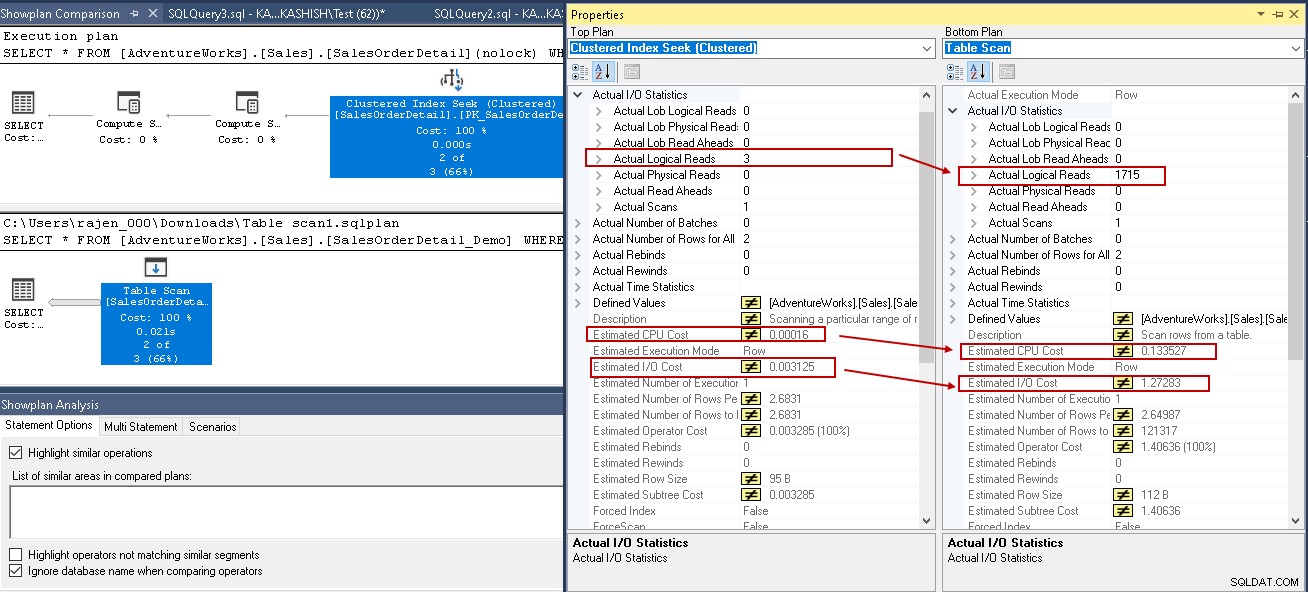
Untuk memberi Anda analisis komparatif, mari bandingkan rencana eksekusi dengan dan tanpa indeks SQL Server. Anda dapat merujuk ke artikel Cara membandingkan rencana eksekusi kueri di SQL Server 2016 SQL Shack untuk wawasan lebih lanjut.
Untuk contoh ini, lihat nilai yang disorot dalam pencarian indeks berkerumun dan pemindaian tabel:
- Pembacaan logis:Mesin database SQL Server membaca halaman dari cache buffer dan menyebabkan pembacaan logis. Di bawah ini, kami melihat pembacaan logis dikurangi dari 1715 menjadi 3 setelah Anda membuat indeks.
- Perkiraan biaya CPU juga turun dari 0,133527 menjadi 0,00016
- Perkiraan biaya IO turun dari 1,27283 menjadi 0,003125
Gambar di bawah menunjukkan perbedaan antara pemindaian tabel dan pencarian indeks.
Indeks yang baik (berguna) dan indeks yang buruk di SQL Server
Seperti namanya, indeks yang baik meningkatkan kinerja kueri dan meminimalkan pemanfaatan sumber daya. Bisakah indeks mengurangi kinerja kueri di SQL Server? Terkadang kami membuat indeks pada kolom tertentu, tetapi tidak pernah digunakan. Misalkan Anda memiliki indeks pada kolom dan Anda melakukan banyak penyisipan dan pembaruan untuk kolom itu. Untuk setiap pembaruan, pembaruan indeks yang sesuai juga diperlukan. Jika beban kerja Anda memiliki lebih banyak aktivitas menulis, dan Anda memiliki banyak indeks di kolom, itu akan memperlambat kinerja kueri Anda secara keseluruhan. Indeks yang tidak digunakan juga dapat menyebabkan kinerja yang lambat untuk pernyataan tertentu. Pengoptimal kueri menggunakan statistik untuk membuat rencana eksekusi. Ia membaca semua indeks dan pengambilan sampel datanya, dan berdasarkan itu, ia membangun rencana eksekusi kueri yang dioptimalkan. Anda dapat melacak penggunaan indeks menggunakan tampilan pengelolaan dinamis sys.dm_db_index_usage_stats dan memantau sumber daya, seperti pemindaian pengguna, pencarian pengguna, dan pencarian pengguna.
Jenis dan pertimbangan indeks SQL Server
SQL Server memiliki dua indeks utama – indeks berkerumun dan tidak berkerumun. Indeks berkerumun menyimpan data aktual di simpul daun indeks. Ini secara fisik mengurutkan data dalam halaman data berdasarkan kunci indeks berkerumun. SQL Server memungkinkan satu indeks berkerumun per tabel. Anda dapat bergabung dengan beberapa kolom untuk membangun kunci indeks berkerumun. Indeks non-clustered adalah indeks logis, dan memiliki kolom kunci indeks yang menunjuk ke kunci indeks berkerumun.
Kita juga dapat memiliki indeks lain di SQL Server seperti indeks XML, indeks penyimpanan kolom, indeks spasial, indeks teks lengkap, indeks hash, dll.
Anda harus mempertimbangkan poin-poin berikut sebelum membuat indeks di SQL Server:
- Beban Kerja
- Kolom yang membutuhkan indeks
- Ukuran meja
- Urutan data kolom naik atau turun
- Urutan kolom
- Jenis indeks
- Faktor pengisian, indeks pad, dan urutan pengurutan TempDB
Manfaat, implikasi, dan rekomendasi indeks SQL Server
Indeks dalam database bisa menjadi pedang bermata dua. Indeks SQL Server yang berguna meningkatkan kueri dan kinerja sistem tanpa memengaruhi kueri lainnya. Di sisi lain, jika Anda membuat indeks tanpa persiapan atau pertimbangan apa pun, hal itu dapat menyebabkan penurunan kinerja, pengambilan data yang lambat, dan dapat menghabiskan lebih banyak sumber daya penting seperti CPU, IO, dan memori. Indeks juga meningkatkan tugas pemeliharaan database Anda. Dengan mengingat faktor-faktor ini, yang terbaik adalah selalu menguji indeks yang sesuai di lingkungan pra-produksi dengan beban kerja produksi yang setara, kemudian menganalisis kinerja dan memutuskan apakah yang terbaik untuk menerapkannya pada database produksi. Ada banyak lagi rekomendasi yang perlu dipertimbangkan, lihat 11 praktik terbaik indeks teratas saya untuk wawasan lebih lanjut.



