UDF skalar selalu menjadi pedang bermata dua – mereka bagus untuk pengembang, yang dapat mengabstraksi logika yang membosankan alih-alih mengulanginya di seluruh kueri mereka, tetapi mereka mengerikan untuk kinerja runtime dalam produksi, karena pengoptimal tidak' t menangani mereka dengan baik. Pada dasarnya yang terjadi adalah eksekusi UDF disimpan terpisah dari rencana eksekusi lainnya, sehingga mereka dipanggil sekali untuk setiap baris dan tidak dapat dioptimalkan berdasarkan perkiraan atau jumlah baris aktual atau dilipat ke dalam sisa rencana.
Karena, terlepas dari upaya terbaik kami sejak SQL Server 2000, kami tidak dapat secara efektif menghentikan penggunaan UDF skalar, bukankah bagus untuk membuat SQL Server menanganinya dengan lebih baik?
SQL Server 2019 memperkenalkan fitur baru yang disebut Scalar UDF Inlining. Alih-alih menjaga fungsi terpisah, itu dimasukkan ke dalam rencana keseluruhan. Ini menghasilkan rencana eksekusi yang jauh lebih baik dan, pada gilirannya, kinerja runtime yang lebih baik.
Tetapi pertama-tama, untuk lebih menggambarkan sumber masalahnya, mari kita mulai dengan sepasang tabel sederhana dengan hanya beberapa baris, dalam database yang berjalan di SQL Server 2017 (atau pada 2019 tetapi dengan tingkat kompatibilitas yang lebih rendah):
CREATE DATABASE Whatever; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140; GO USE Whatever; GO CREATE TABLE dbo.Languages ( LanguageID int PRIMARY KEY, Name sysname ); CREATE TABLE dbo.Employees ( EmployeeID int PRIMARY KEY, LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID) ); INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon'); INSERT dbo.Employees(EmployeeID, LanguageID) SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END FROM sys.all_objects;
Sekarang, kami memiliki kueri sederhana di mana kami ingin menunjukkan setiap karyawan dan nama bahasa utama mereka. Katakanlah kueri ini digunakan di banyak tempat dan/atau dengan cara yang berbeda, jadi, alih-alih membuat gabungan ke dalam kueri, kami menulis UDF skalar untuk mengabstraksi gabungan itu:
CREATE FUNCTION dbo.GetLanguage(@id int) RETURNS sysname AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END
Kemudian kueri kami yang sebenarnya terlihat seperti ini:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Jika kita melihat rencana eksekusi untuk kueri, ada sesuatu yang anehnya hilang:
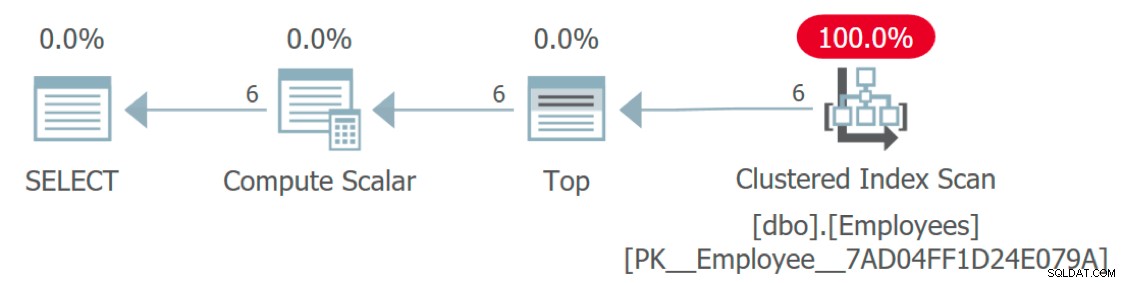 Rencana eksekusi menunjukkan akses ke Karyawan tetapi tidak ke Bahasa
Rencana eksekusi menunjukkan akses ke Karyawan tetapi tidak ke Bahasa
Bagaimana tabel Bahasa diakses? Rencana ini terlihat sangat efisien karena – seperti fungsi itu sendiri – ia mengabstraksikan beberapa kerumitan yang terlibat. Sebenarnya, rencana grafis ini identik dengan kueri yang hanya menetapkan konstanta atau variabel ke Language kolom:
SELECT TOP (6) EmployeeID, Language = N'Sanskrit' FROM dbo.Employees;
Tetapi jika Anda menjalankan pelacakan terhadap kueri asli, Anda akan melihat bahwa sebenarnya ada enam panggilan ke fungsi (satu untuk setiap baris) selain kueri utama, tetapi paket ini tidak dikembalikan oleh SQL Server.
Anda juga dapat memverifikasi ini dengan memeriksa sys.dm_exec_function_stats , tapi ini bukan jaminan :
SELECT [function] = OBJECT_NAME([object_id]), execution_count FROM sys.dm_exec_function_stats WHERE object_name(object_id) IS NOT NULL;
function execution_count ----------- --------------- GetLanguage 6
SentryOne Plan Explorer akan menampilkan pernyataan jika Anda membuat rencana aktual dari dalam produk, tetapi kami hanya dapat memperolehnya dari jejak, dan masih belum ada paket yang dikumpulkan atau ditampilkan untuk panggilan fungsi individual:
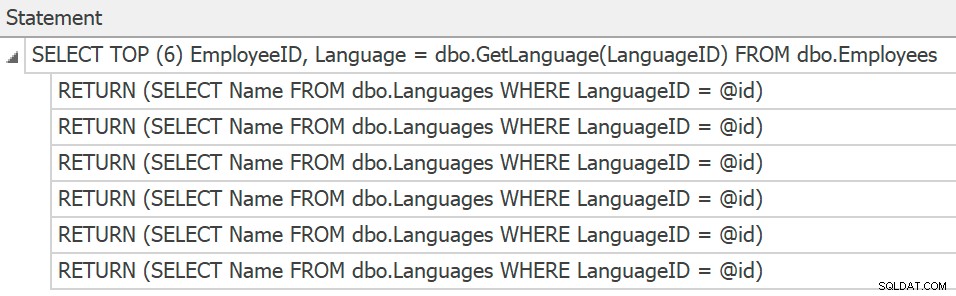 Lacak pernyataan untuk pemanggilan UDF skalar individual
Lacak pernyataan untuk pemanggilan UDF skalar individual
Ini semua membuat mereka sangat sulit untuk dipecahkan, karena Anda harus memburu mereka, bahkan ketika Anda sudah tahu mereka ada di sana. Ini juga dapat membuat analisis kinerja menjadi kacau jika Anda membandingkan dua paket berdasarkan hal-hal seperti perkiraan biaya, karena tidak hanya operator terkait yang bersembunyi dari diagram fisik, biaya juga tidak dimasukkan di mana pun dalam rencana.
Maju Cepat ke SQL Server 2019
Setelah bertahun-tahun mengalami perilaku bermasalah dan akar penyebab yang tidak jelas, mereka berhasil membuat beberapa fungsi dapat dioptimalkan ke dalam rencana eksekusi secara keseluruhan. Scalar UDF Inlining membuat objek yang mereka akses terlihat untuk pemecahan masalah *dan* memungkinkan mereka untuk dimasukkan ke dalam strategi rencana eksekusi. Sekarang perkiraan kardinalitas (berdasarkan statistik) memungkinkan strategi penggabungan yang tidak mungkin dilakukan saat fungsi dipanggil sekali untuk setiap baris.
Kita dapat menggunakan contoh yang sama seperti di atas, baik membuat kumpulan objek yang sama pada database SQL Server 2019, atau menggosok cache paket dan menaikkan tingkat kompatibilitas ke 150:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150; GO
Sekarang ketika kita menjalankan kueri enam baris kita lagi:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Kami mendapatkan paket yang menyertakan tabel Bahasa dan biaya yang terkait dengan mengaksesnya:
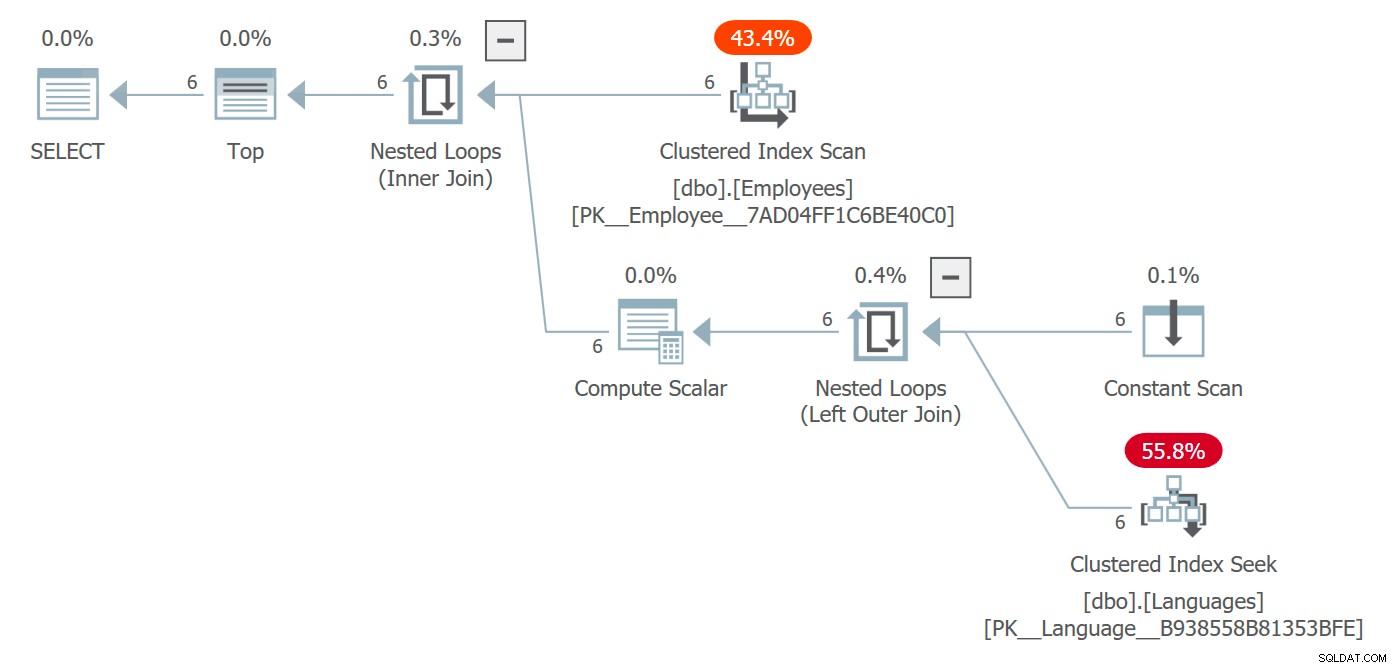 Paket yang menyertakan akses ke objek yang dirujuk di dalam UDF skalar
Paket yang menyertakan akses ke objek yang dirujuk di dalam UDF skalar
Di sini, pengoptimal memilih gabungan loop bersarang tetapi, dalam keadaan yang berbeda, ia dapat memilih strategi gabungan yang berbeda, memikirkan paralelisme, dan pada dasarnya bebas untuk sepenuhnya mengubah bentuk rencana. Anda kemungkinan tidak akan melihat ini dalam kueri yang mengembalikan 6 baris dan sama sekali bukan masalah kinerja, tetapi pada skala yang lebih besar hal ini bisa terjadi.
Rencana tersebut mencerminkan bahwa fungsi tersebut tidak dipanggil per baris – sementara pencarian sebenarnya dijalankan enam kali, Anda dapat melihat bahwa fungsi itu sendiri tidak lagi muncul di sys.dm_exec_function_stats . Satu kelemahan yang dapat Anda ambil adalah, jika Anda menggunakan DMV ini untuk menentukan apakah suatu fungsi sedang digunakan secara aktif (seperti yang sering kita lakukan untuk prosedur dan indeks), itu tidak lagi dapat diandalkan.
Peringatan
Tidak setiap fungsi skalar tidak dapat disejajarkan dan, bahkan ketika suatu fungsi *tidak* tidak dapat disejajarkan, fungsi tersebut tidak harus disejajarkan dalam setiap skenario. Ini sering berkaitan dengan kompleksitas fungsi, kompleksitas kueri yang terlibat, atau kombinasi keduanya. Anda dapat memeriksa apakah suatu fungsi inlineable di sys.sql_modules tampilan katalog:
SELECT OBJECT_NAME([object_id]), definition, is_inlineable FROM sys.sql_modules;
Dan jika, karena alasan apa pun, Anda tidak ingin fungsi tertentu (atau fungsi apa pun dalam database) digariskan, Anda tidak perlu bergantung pada tingkat kompatibilitas database untuk mengontrol perilaku itu. Saya tidak pernah menyukai kopling longgar itu, yang mirip dengan berpindah kamar untuk menonton acara televisi yang berbeda daripada hanya mengubah saluran. Anda dapat mengontrol ini di tingkat modul menggunakan opsi INLINE:
ALTER FUNCTION dbo.GetLanguage(@id int) RETURNS sysname WITH INLINE = OFF AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END GO
Dan Anda dapat mengontrol ini di tingkat basis data, tetapi terpisah dari tingkat kompatibilitas:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Meskipun Anda harus memiliki kasus penggunaan yang cukup bagus untuk mengayunkan palu itu, IMHO.
Kesimpulan
Sekarang, saya tidak menyarankan Anda untuk pergi dan mengabstraksikan setiap bagian logika menjadi UDF skalar, dan berasumsi bahwa sekarang SQL Server hanya akan menangani semua kasus. Jika Anda memiliki basis data dengan banyak penggunaan UDF skalar, Anda harus mengunduh SQL Server 2019 CTP terbaru, memulihkan cadangan basis data Anda di sana, dan memeriksa DMV untuk melihat berapa banyak dari fungsi-fungsi itu yang tidak dapat diluruskan ketika saatnya tiba. Ini bisa menjadi poin utama saat Anda berdebat untuk peningkatan, karena pada dasarnya Anda akan mendapatkan semua kinerja itu dan membuang waktu pemecahan masalah kembali.
Sementara itu, jika Anda mengalami kinerja UDF skalar dan Anda tidak akan memutakhirkan ke SQL Server 2019 dalam waktu dekat, mungkin ada cara lain untuk membantu mengurangi masalah tersebut.
Catatan:Saya menulis dan mengantri artikel ini sebelum saya menyadari bahwa saya telah memposting bagian yang berbeda di tempat lain.