Beberapa minggu yang lalu, saya menulis tentang betapa terkejutnya saya dengan kinerja fungsi asli baru di SQL Server 2016, STRING_SPLIT() :
- Kejutan dan Asumsi Kinerja :STRING_SPLIT()
Setelah posting diterbitkan, saya mendapat beberapa komentar (secara publik dan pribadi) dengan saran ini (atau pertanyaan yang saya ubah menjadi saran):
- Menentukan tipe data keluaran eksplisit untuk pendekatan JSON, sehingga metode tersebut tidak mengalami potensi overhead kinerja karena fallback
nvarchar(max). - Menguji pendekatan yang sedikit berbeda, di mana sesuatu benar-benar dilakukan dengan data – yaitu
SELECT INTO #temp. - Menampilkan bagaimana taksiran jumlah baris dibandingkan dengan metode yang ada, terutama saat menyarangkan operasi pemisahan.
Saya memang menanggapi beberapa orang secara offline, tetapi menurut saya ada baiknya memposting tindak lanjut di sini.
Menjadi lebih adil terhadap JSON
Fungsi JSON asli tampak seperti ini, tanpa spesifikasi untuk tipe data keluaran:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Saya menamainya, dan membuat dua lagi, dengan definisi berikut:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Saya pikir ini akan meningkatkan kinerja secara drastis, tetapi sayangnya, ini tidak terjadi. Saya menjalankan tes lagi dan hasilnya adalah sebagai berikut:
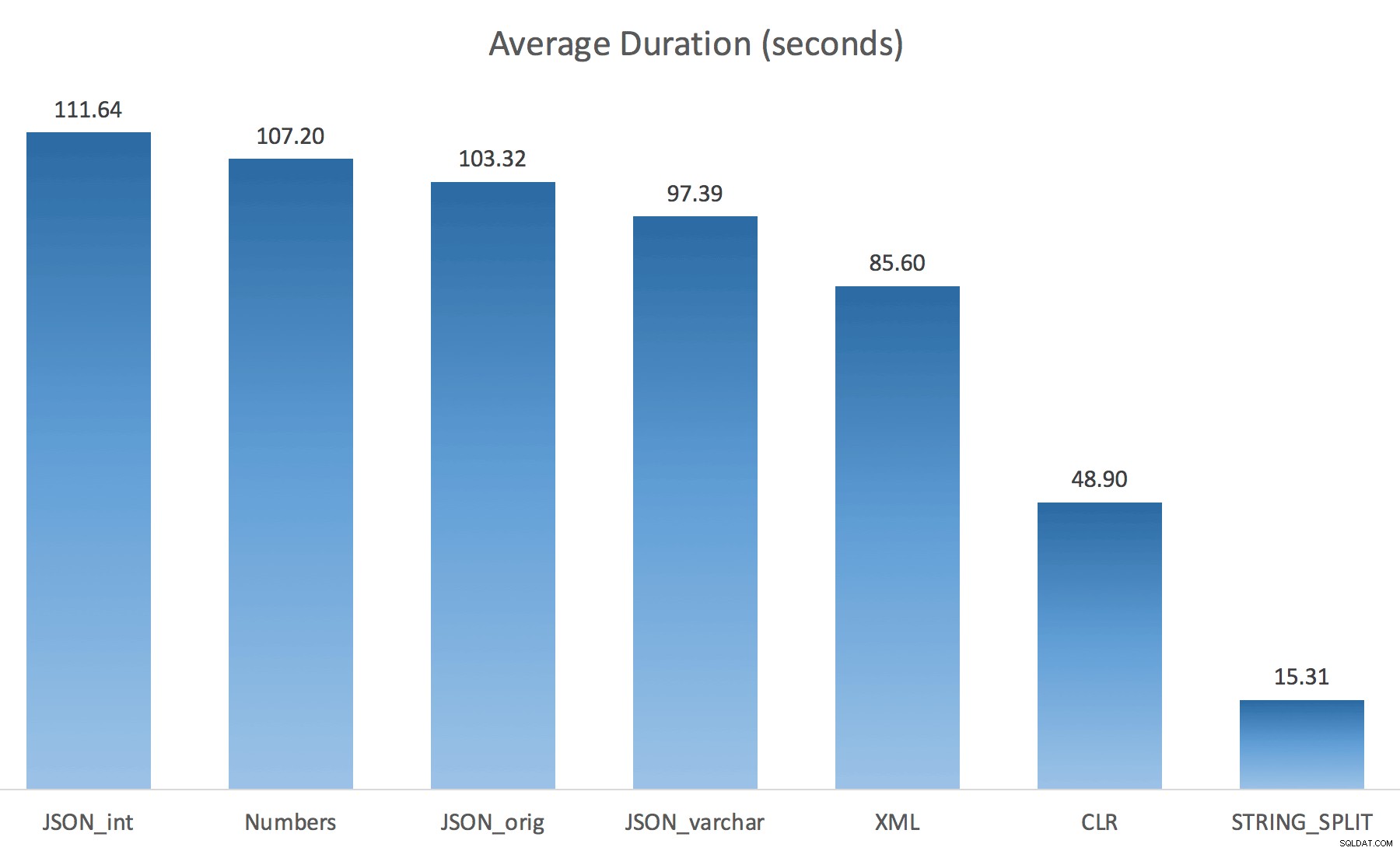
Penantian diamati selama pengujian acak (difilter ke yang> 25):
| CLR | IO_COMPLETION | 1.595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6.294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4.307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6.110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Angka | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1,917 |
| IO_COMPLETION | 1,616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Menunggu diamati> 25 (perhatikan tidak ada entri untuk STRING_SPLIT )
Saat mengubah dari default ke varchar(100) memang sedikit meningkatkan kinerja, perolehannya dapat diabaikan, dan berubah menjadi int sebenarnya membuatnya lebih buruk. Tambahkan ke ini yang mungkin perlu Anda tambahkan STRING_ESCAPE() ke string yang masuk dalam beberapa skenario, untuk berjaga-jaga jika mereka memiliki karakter yang akan mengacaukan penguraian JSON. Kesimpulan saya adalah bahwa ini adalah cara yang rapi untuk menggunakan fungsi JSON baru, tetapi sebagian besar merupakan hal baru yang tidak sesuai untuk skala yang wajar.
Mewujudkan Output
Jonathan Magnan membuat pengamatan yang cerdik ini pada posting saya sebelumnya:
STRING_SPLIT memang sangat cepat, namun juga sangat lambat ketika bekerja dengan tabel sementara (kecuali jika diperbaiki di build mendatang).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Akan JAUH lebih lambat daripada solusi SQL CLR (15x dan lebih banyak lagi!).
Jadi, saya menggali. Saya membuat kode yang akan memanggil setiap fungsi saya dan membuang hasilnya ke tabel #temp, dan mengatur waktunya:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
Saya hanya menjalankan setiap tes sekali (daripada mengulang 100 kali), karena saya tidak ingin sepenuhnya menghancurkan I/O pada sistem saya. Namun, setelah rata-rata tiga kali uji coba, Jonathan benar-benar, 100% benar. Berikut adalah durasi mengisi tabel #temp dengan ~500.000 baris menggunakan setiap metode:
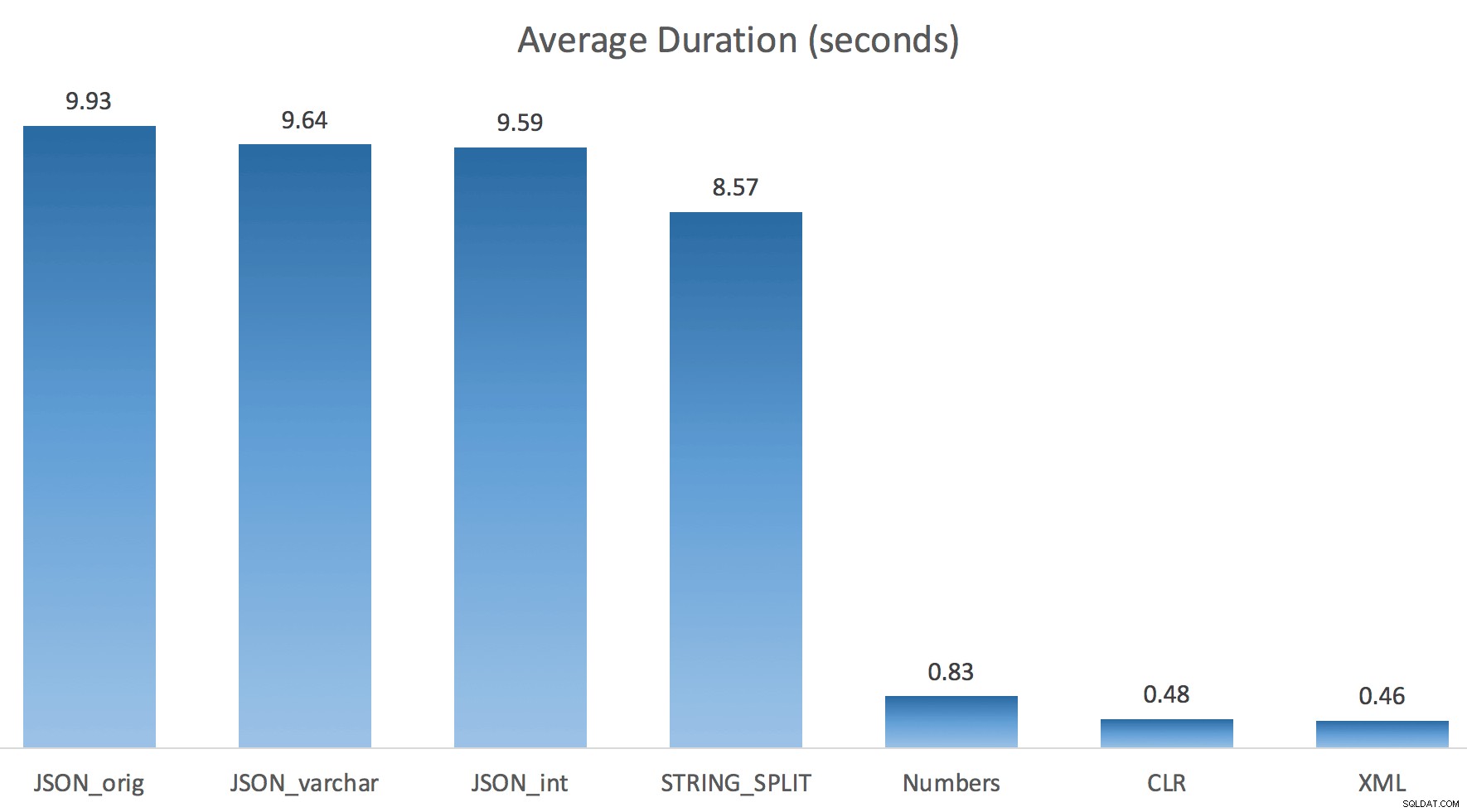
Jadi di sini, JSON dan STRING_SPLIT masing-masing metode membutuhkan waktu sekitar 10 detik, sedangkan pendekatan tabel Numbers, CLR, dan XML membutuhkan waktu kurang dari satu detik. Bingung, saya menyelidiki penantian, dan tentu saja, empat metode di sebelah kiri menghasilkan LATCH_EX yang signifikan menunggu (sekitar 25 detik) tidak terlihat di tiga lainnya, dan tidak ada menunggu signifikan lainnya untuk dibicarakan.
Dan karena gerendel menunggu lebih lama dari total durasi, itu memberi saya petunjuk bahwa ini ada hubungannya dengan paralelisme (mesin khusus ini memiliki 4 inti). Jadi saya membuat kode pengujian lagi, mengubah hanya satu baris untuk melihat apa yang akan terjadi tanpa paralelisme:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Sekarang STRING_SPLIT bernasib jauh lebih baik (seperti halnya metode JSON), tetapi setidaknya dua kali lipat waktu yang dibutuhkan oleh CLR:
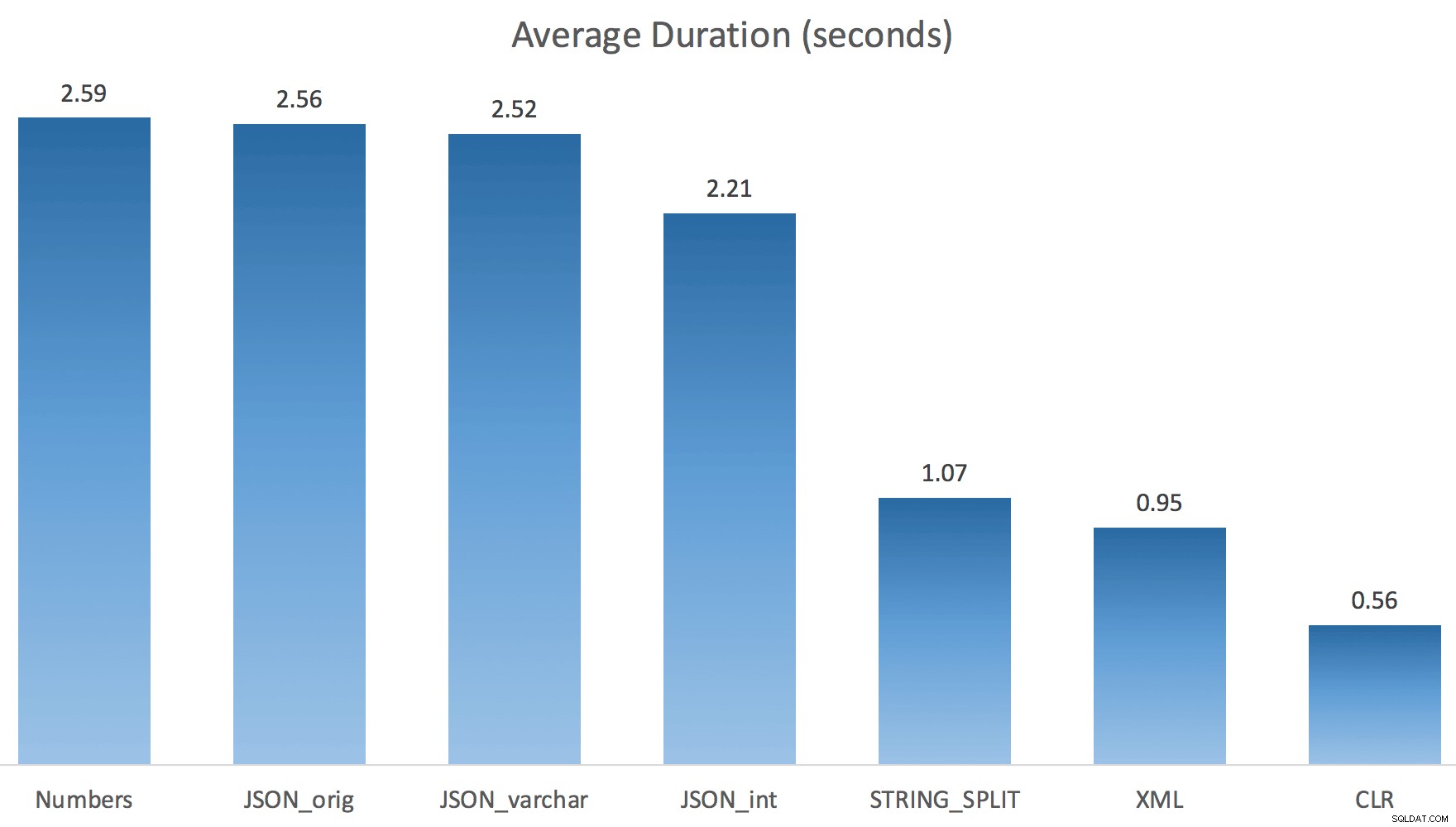
Jadi, mungkin ada masalah yang tersisa dalam metode baru ini ketika paralelisme terlibat. Itu bukan masalah distribusi utas (saya memeriksanya), dan CLR sebenarnya memiliki perkiraan yang lebih buruk (100x aktual vs. hanya 5x untuk STRING_SPLIT ); hanya beberapa masalah mendasar dengan kait koordinasi di antara utas yang saya kira. Untuk saat ini, mungkin ada baiknya menggunakan MAXDOP 1 jika Anda tahu Anda sedang menulis hasilnya ke halaman baru.
Saya telah menyertakan rencana grafis yang membandingkan pendekatan CLR dengan yang asli, untuk eksekusi paralel dan serial (saya juga telah mengunggah file Analisis Kueri yang dapat Anda buka di SQL Sentry Plan Explorer untuk mengintip sendiri):
STRING_SPLIT
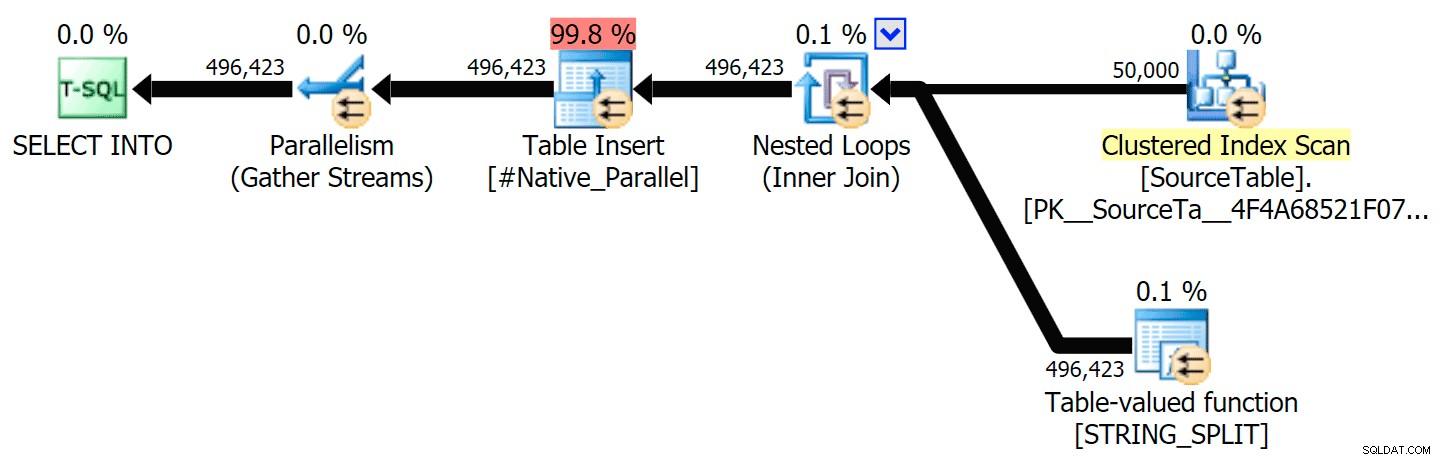
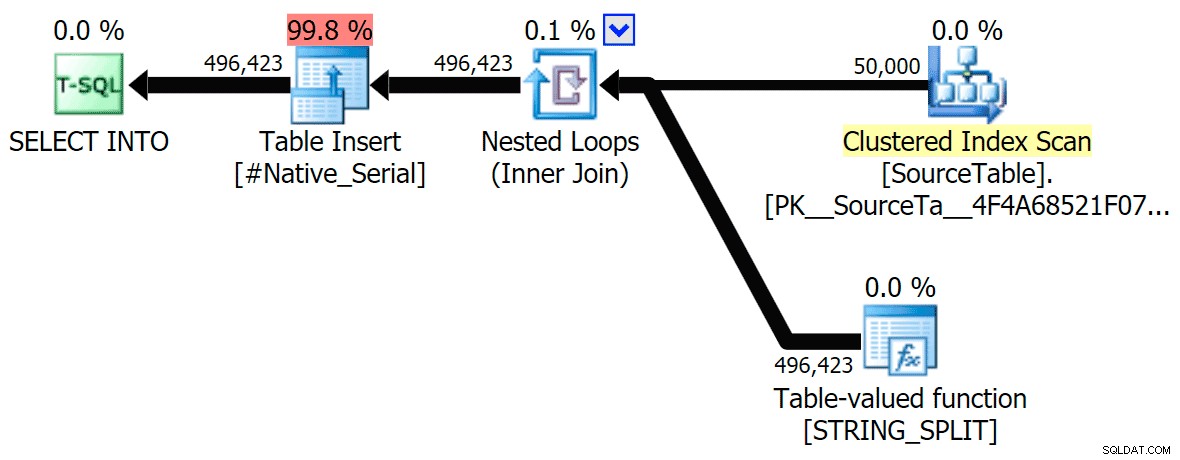
CLR
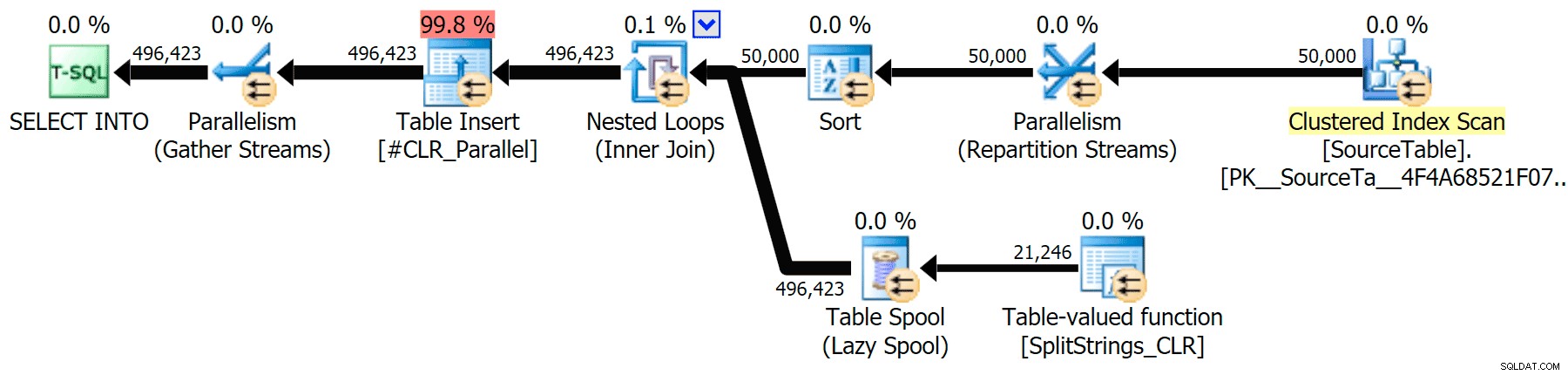
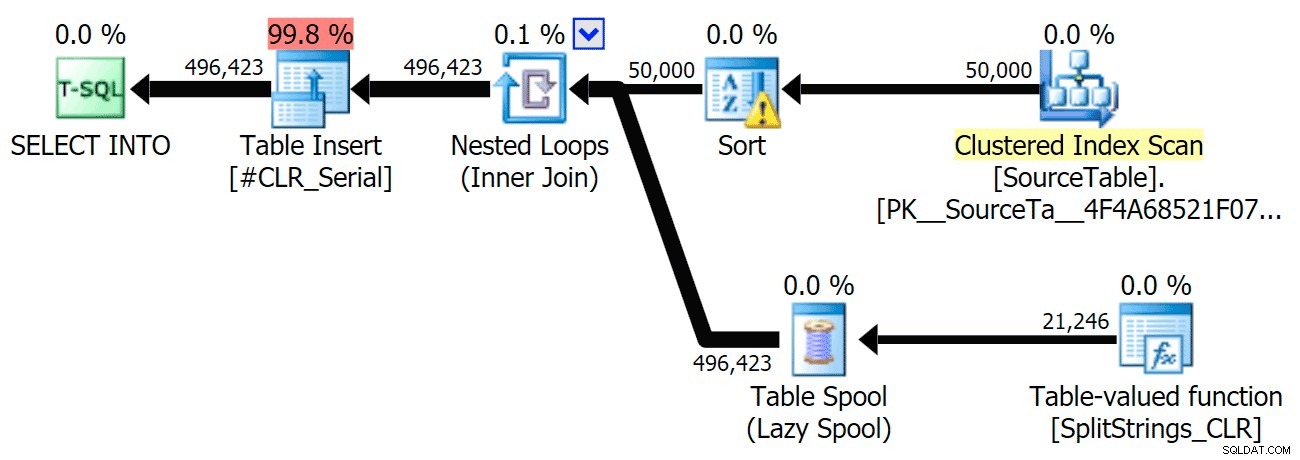
Peringatan pengurutan, FYI, tidak terlalu mengejutkan, dan jelas tidak memiliki banyak efek nyata pada durasi kueri:

- StringSplit.queryanalysis.zip (25kb)
Berlibur Untuk Musim Panas
Ketika saya melihat lebih dekat pada rencana itu, saya perhatikan bahwa dalam rencana CLR, ada gulungan malas. Ini diperkenalkan untuk memastikan bahwa duplikat diproses bersama (untuk menghemat pekerjaan dengan melakukan pemisahan yang lebih sedikit), tetapi gulungan ini tidak selalu memungkinkan dalam semua bentuk denah, dan ini dapat memberikan sedikit keuntungan bagi mereka yang dapat menggunakannya ( misalnya rencana CLR), tergantung pada perkiraan. Untuk membandingkan tanpa spool, saya mengaktifkan trace flag 8690, dan menjalankan tes lagi. Pertama, ini adalah paket CLR paralel tanpa spool:
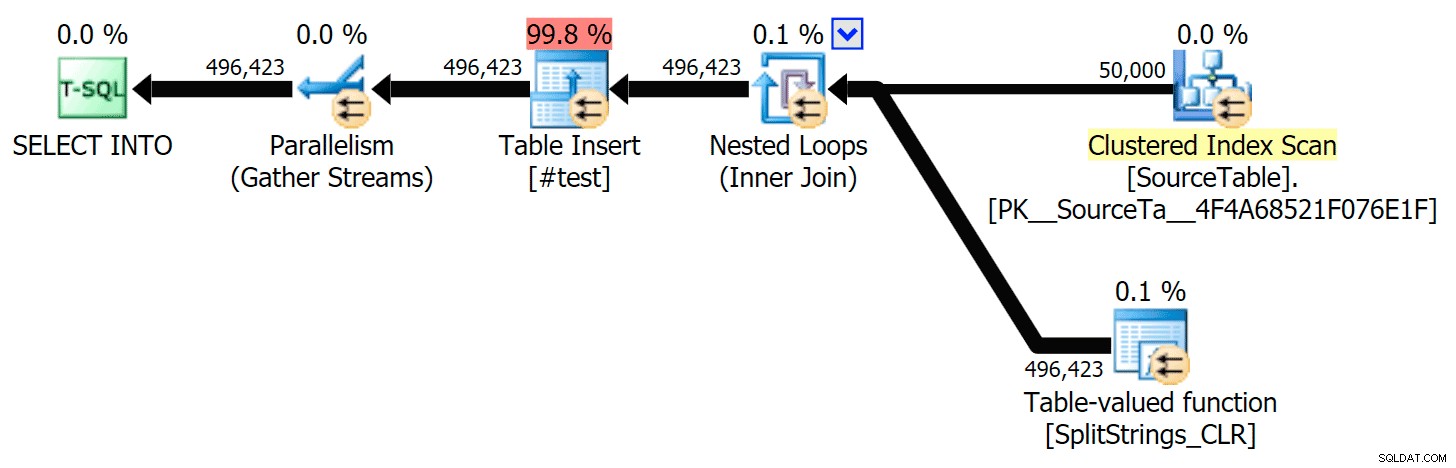
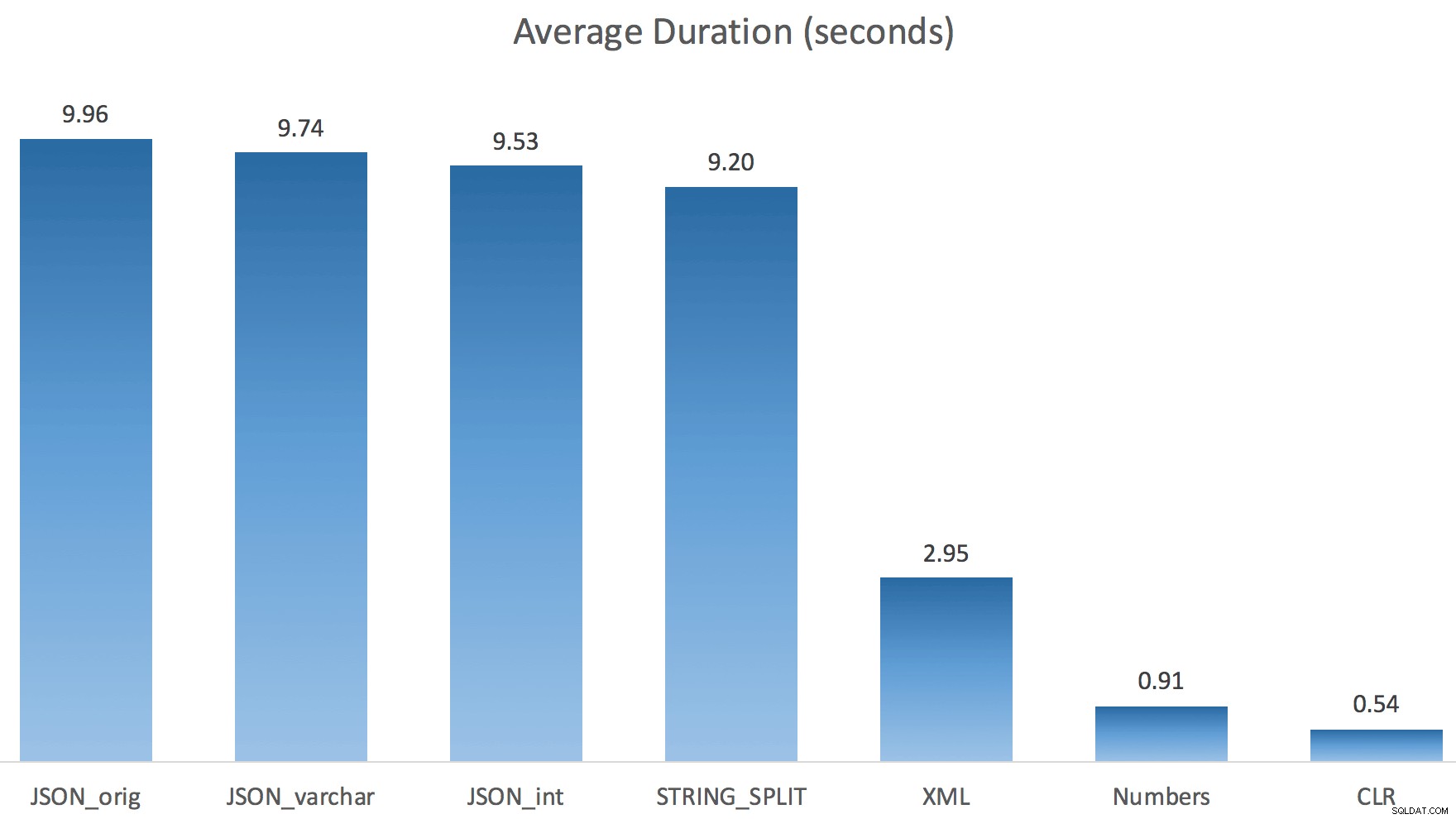
Dan berikut adalah durasi baru untuk semua kueri yang paralel dengan TF 8690 yang diaktifkan:
Sekarang, ini adalah paket CLR serial tanpa spool:
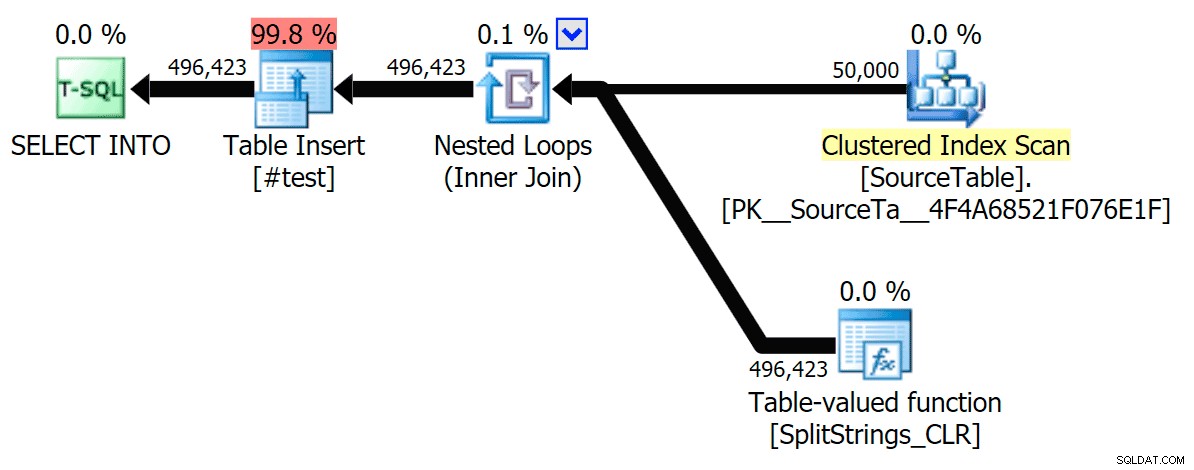
Dan inilah hasil waktu untuk kueri menggunakan TF 8690 dan MAXDOP 1 :
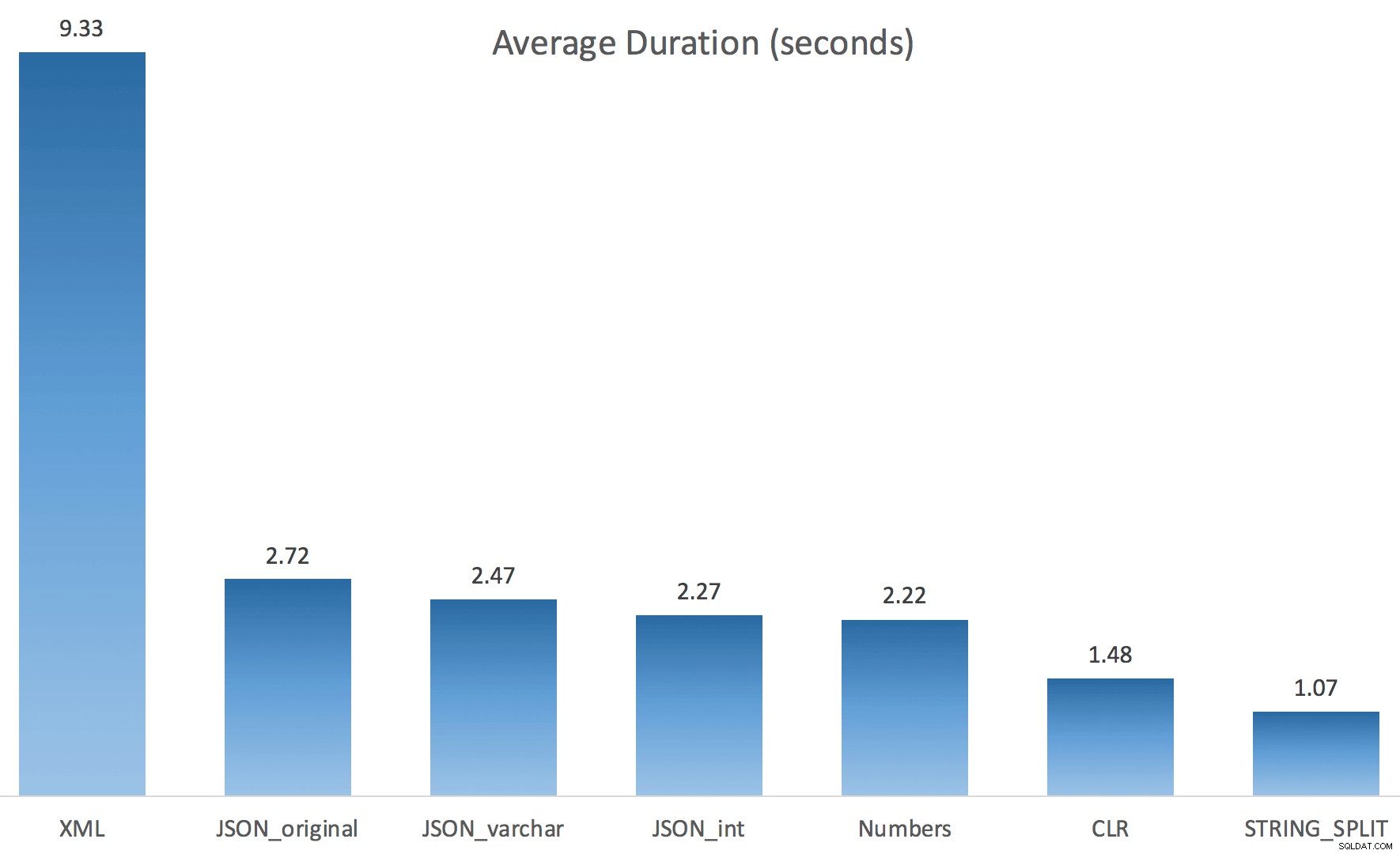
(Perhatikan bahwa, selain paket XML, sebagian besar lainnya tidak berubah sama sekali, dengan atau tanpa tanda jejak.)
Membandingkan perkiraan jumlah baris
Dan Holmes mengajukan pertanyaan berikut:
Bagaimana cara memperkirakan ukuran data saat digabungkan ke fungsi split lain (atau beberapa)? Tautan di bawah ini adalah penulisan implementasi split Berbasis CLR. Apakah 2016 melakukan pekerjaan yang 'lebih baik' dengan perkiraan data? (sayangnya saya belum memiliki kemampuan untuk menginstal RC).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Jadi, saya menggesek kode dari pos Dan, mengubahnya untuk menggunakan fungsi saya, dan menjalankannya melalui Plan Explorer:
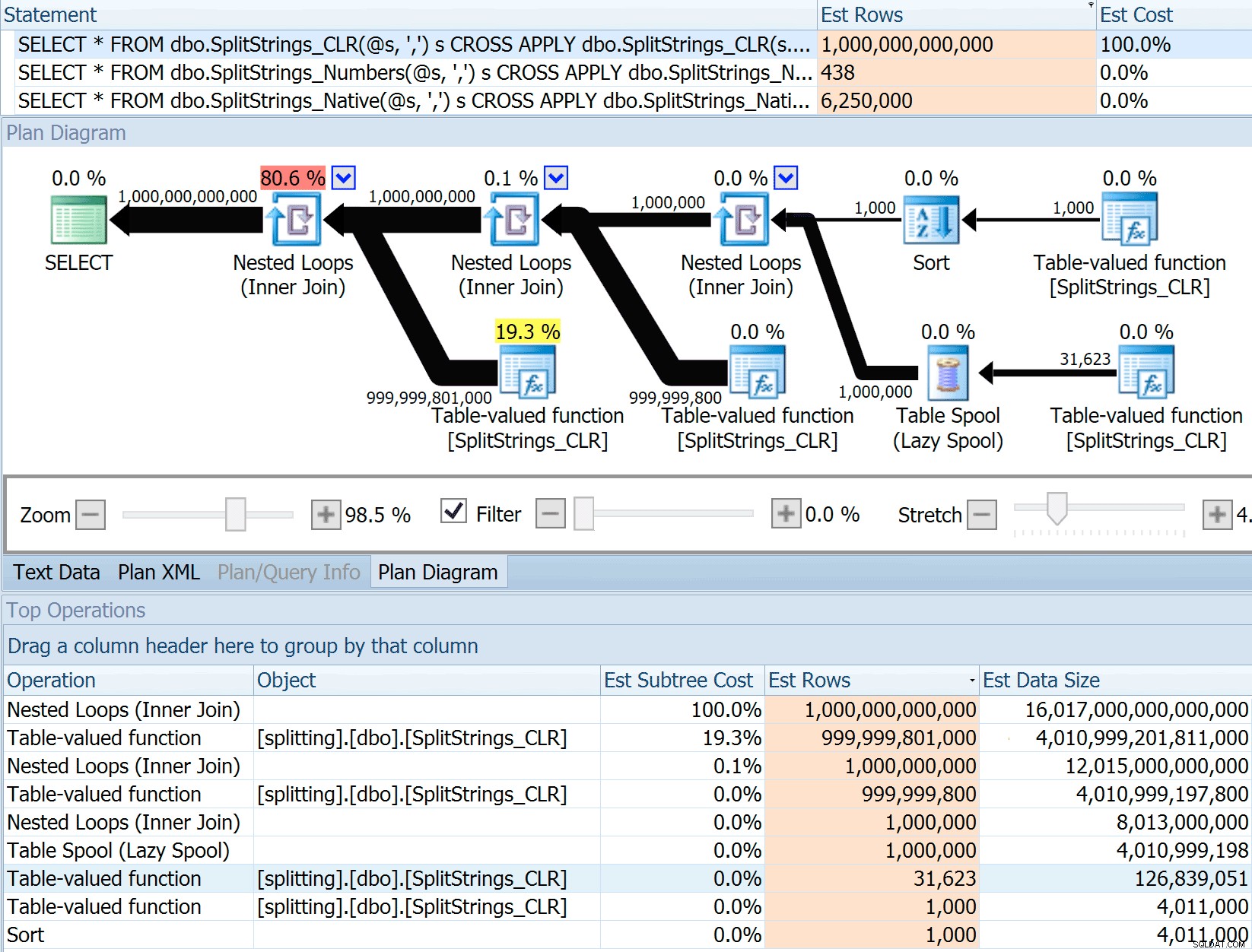
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
SPLIT_STRING pendekatan pasti muncul dengan perkiraan * lebih baik * daripada CLR, tetapi masih terlalu berlebihan (dalam hal ini, ketika string kosong; ini mungkin tidak selalu terjadi). Fungsi ini memiliki bawaan bawaan yang memperkirakan string yang masuk akan memiliki 50 elemen, jadi saat Anda menyarangkannya, Anda mendapatkan 50 x 50 (2.500); jika Anda membuat sarang lagi, 50 x 2.500 (125.000); dan akhirnya, 50 x 125.000 (6.250.000):
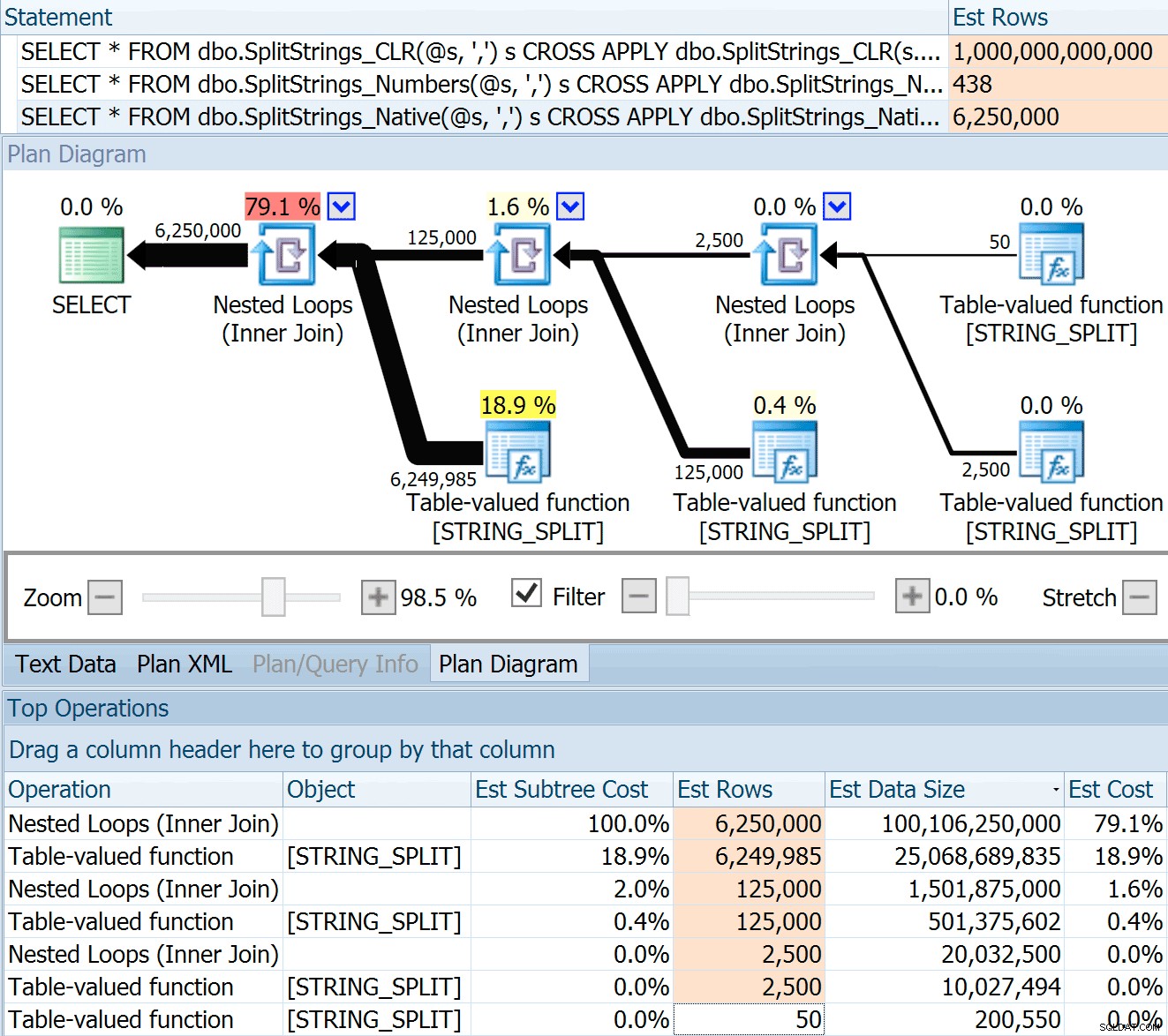
Catatan:OPENJSON() berperilaku dengan cara yang sama persis seperti STRING_SPLIT – itu juga, mengasumsikan 50 baris akan keluar dari setiap operasi pemisahan yang diberikan. Saya berpikir bahwa mungkin berguna untuk memiliki cara untuk mengisyaratkan kardinalitas untuk fungsi seperti ini, selain melacak flag seperti 4137 (pra-2014), 9471 &9472 (2014+), dan tentu saja 9481…
Perkiraan 6,25 juta baris ini tidak bagus, tetapi jauh lebih baik daripada pendekatan CLR yang dibicarakan Dan, yang memperkirakan TRILIUN BARIS , dan saya kehilangan hitungan koma untuk menentukan ukuran data – 16 petabyte? exabyte?
Beberapa pendekatan lain jelas lebih baik dalam hal perkiraan. Tabel Numbers, misalnya, memperkirakan 438 baris yang jauh lebih masuk akal (di SQL Server 2016 RC2). Dari mana nomor ini berasal? Nah, ada 8.000 baris dalam tabel, dan jika Anda ingat, fungsi tersebut memiliki predikat persamaan dan pertidaksamaan:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Jadi, SQL Server mengalikan jumlah baris dalam tabel sebesar 10% (sebagai tebakan) untuk filter kesetaraan, lalu akar kuadrat 30% (sekali lagi, tebakan) untuk filter ketidaksetaraan. Akar kuadrat disebabkan oleh backoff eksponensial, yang dijelaskan oleh Paul White di sini. Ini memberi kita:
8000 * 0,1 * SQRT (0,3) =438,178Variasi XML diperkirakan sedikit lebih dari satu miliar baris (karena spool tabel diperkirakan dieksekusi 5,8 juta kali), tetapi rencananya terlalu rumit untuk digambarkan di sini. Bagaimanapun, ingatlah bahwa perkiraan jelas tidak menceritakan keseluruhan cerita – hanya karena kueri memiliki perkiraan yang lebih akurat tidak berarti kueri akan berkinerja lebih baik.
Ada beberapa cara lain untuk sedikit mengubah perkiraan:yaitu, memaksa model estimasi kardinalitas lama (yang memengaruhi variasi tabel XML dan Numbers), dan menggunakan TFs 9471 dan 9472 (yang hanya memengaruhi variasi tabel Numbers, karena keduanya mengontrol kardinalitas di sekitar beberapa predikat). Inilah cara saya dapat mengubah perkiraan sedikit saja (atau BANYAK , dalam kasus kembali ke model CE lama):

Model CE lama menurunkan perkiraan XML berdasarkan urutan besarnya, tetapi untuk tabel Numbers, benar-benar mengacaukannya. Bendera predikat mengubah perkiraan untuk tabel Angka, tetapi perubahan itu kurang menarik.
Tak satu pun dari tanda pelacakan ini berpengaruh pada perkiraan untuk CLR, JSON, atau STRING_SPLIT variasi.
Kesimpulan
Jadi apa yang saya pelajari di sini? Banyak, sebenarnya:
- Paralelisme dapat membantu dalam beberapa kasus, tetapi jika tidak membantu, itu benar-benar tidak membantu. Metode JSON ~5x lebih cepat tanpa paralelisme, dan
STRING_SPLIThampir 10x lebih cepat. - Spool sebenarnya membantu pendekatan CLR berkinerja lebih baik dalam kasus ini, tetapi TF 8690 mungkin berguna untuk bereksperimen dalam kasus lain di mana Anda melihat spool dan mencoba meningkatkan kinerja. Saya yakin ada situasi di mana menghilangkan gulungan akan menjadi lebih baik secara keseluruhan.
- Menghilangkan spool benar-benar merugikan pendekatan XML (tetapi hanya drastis jika dipaksa menjadi single-threaded).
- Banyak hal funky dapat terjadi dengan perkiraan bergantung pada pendekatannya, bersama dengan statistik, distribusi, dan tanda jejak yang biasa. Yah, saya kira saya sudah tahu itu, tapi pasti ada beberapa contoh nyata yang bagus di sini.
Terima kasih kepada orang-orang yang mengajukan pertanyaan atau mendorong saya untuk memasukkan informasi lebih lanjut. Dan seperti yang mungkin sudah Anda tebak dari judulnya, saya menjawab pertanyaan lain dalam tindak lanjut kedua, yang ini tentang TVP:
- STRING_SPLIT() di SQL Server 2016 :Tindak Lanjut #2