Awal minggu ini, saya memposting tindak lanjut dari postingan terbaru saya tentang STRING_SPLIT() di SQL Server 2016, menangani beberapa komentar yang tersisa di pos dan/atau dikirim ke saya secara langsung:
STRING_SPLIT()di SQL Server 2016 :Tindak Lanjut #1
Setelah postingan itu kebanyakan ditulis, ada pertanyaan terakhir dari Doug Ellner:
Bagaimana fungsi-fungsi ini dibandingkan dengan parameter bernilai tabel?
Sekarang, pengujian TVP sudah ada dalam daftar proyek masa depan saya, setelah pertukaran twitter baru-baru ini dengan @Nick_Craver di Stack Overflow. Dia mengatakan bahwa mereka senang karena STRING_SPLIT() berkinerja baik, karena mereka tidak puas dengan kinerja pengiriman ~7.000 nilai melalui parameter bernilai tabel.
Ujian Saya
Untuk pengujian ini, saya menggunakan SQL Server 2016 RC3 (13.0.1400.361) pada VM Windows 10 8-core, dengan penyimpanan PCIe dan RAM 32 GB.
Saya membuat tabel sederhana yang meniru apa yang mereka lakukan (memilih sekitar 10.000 nilai dari tabel posting baris 3+ juta), tetapi untuk pengujian saya, kolom itu jauh lebih sedikit dan indeksnya lebih sedikit:
CREATE TABLE dbo.Posts_Regular( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS GABUNG sys.all_objects AS s2;
Saya juga membuat versi In-Memory, karena saya ingin tahu apakah ada pendekatan yang akan bekerja secara berbeda di sana:
BUAT TABEL dbo.Posts_InMemory( PostID int PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT =4000000), HitCount int NOT NULL DEFAULT 0) WITH (MEMORY_OPTIMIZED =ON);
Sekarang, saya ingin membuat aplikasi C# yang akan meneruskan 10.000 nilai unik, baik sebagai string yang dipisahkan koma (dibangun menggunakan StringBuilder) atau sebagai TVP (diteruskan dari DataTable). Intinya adalah untuk mengambil atau memperbarui pilihan baris berdasarkan kecocokan, baik ke elemen yang dihasilkan dengan memisahkan daftar, atau nilai eksplisit dalam TVP. Jadi kode ditulis untuk menambahkan setiap nilai ke-300 ke string atau DataTable (kode C# ada di lampiran di bawah). Saya mengambil fungsi yang saya buat di posting asli, mengubahnya untuk menangani varchar(max) , lalu menambahkan dua fungsi yang menerima TVP – salah satunya dengan memori yang dioptimalkan. Berikut adalah jenis tabelnya (fungsinya ada di lampiran di bawah ini):
BUAT TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY);GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE( PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT =1000000)) WITH (MEMORYDIMIZED) /pra>Saya juga harus membuat tabel Numbers lebih besar untuk menangani string> 8K dan dengan elemen> 8K (saya membuatnya menjadi 1 MM baris). Kemudian saya membuat tujuh prosedur tersimpan:lima di antaranya menggunakan
varchar(max)dan bergabung dengan output fungsi untuk memperbarui tabel dasar, dan kemudian dua untuk menerima TVP dan bergabung secara langsung melawannya. Kode C# memanggil masing-masing dari tujuh prosedur ini, dengan daftar 10.000 posting untuk dipilih atau diperbarui, 1.000 kali. Prosedur-prosedur ini juga ada dalam lampiran di bawah ini. Jadi untuk meringkas, metode yang diuji adalah:
- Asli (
STRING_SPLIT()) - XML
- CLR
- Tabel angka
- JSON (dengan
inteksplisit> keluaran) - Parameter bernilai tabel
- Parameter nilai tabel yang dioptimalkan memori
Kami akan menguji pengambilan 10.000 nilai, 1.000 kali, menggunakan DataReader – tetapi tidak mengulangi DataReader, karena itu hanya akan membuat pengujian memakan waktu lebih lama, dan akan menjadi jumlah pekerjaan yang sama untuk aplikasi C# terlepas dari bagaimana database menghasilkan himpunan. Kami juga akan menguji pembaruan 10.000 baris, masing-masing 1.000 kali, menggunakan ExecuteNonQuery() . Dan kami akan menguji terhadap tabel Posts versi reguler dan memori yang dioptimalkan, yang dapat kami alihkan dengan sangat mudah tanpa harus mengubah fungsi atau prosedur apa pun, menggunakan sinonim:
BUAT SINONIM dbo.Postingan UNTUK dbo.Posts_Regular; -- untuk menguji versi memori yang dioptimalkan:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- untuk menguji versi berbasis disk lagi:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Saya memulai aplikasi, menjalankannya beberapa kali untuk setiap kombinasi untuk memastikan kompilasi, caching, dan faktor lain tidak adil untuk batch yang dieksekusi terlebih dahulu, dan kemudian menganalisis hasil dari tabel logging (Saya juga memeriksa sys. dm_exec_procedure_stats untuk memastikan tidak ada pendekatan yang memiliki overhead berbasis aplikasi yang signifikan, padahal tidak).
Hasil – Tabel Berbasis Disk
Terkadang saya kesulitan dengan visualisasi data – saya benar-benar mencoba menemukan cara untuk mewakili metrik ini pada satu bagan, tetapi saya pikir ada terlalu banyak titik data untuk membuat yang menonjol menonjol.
Anda dapat mengklik untuk memperbesar salah satu dari ini di tab/jendela baru, tetapi meskipun Anda memiliki jendela kecil, saya mencoba untuk memperjelas pemenang melalui penggunaan warna (dan pemenangnya sama dalam setiap kasus). Dan untuk lebih jelasnya, dengan "Durasi Rata-rata" yang saya maksud adalah jumlah waktu rata-rata yang dibutuhkan aplikasi untuk menyelesaikan satu putaran 1.000 operasi.
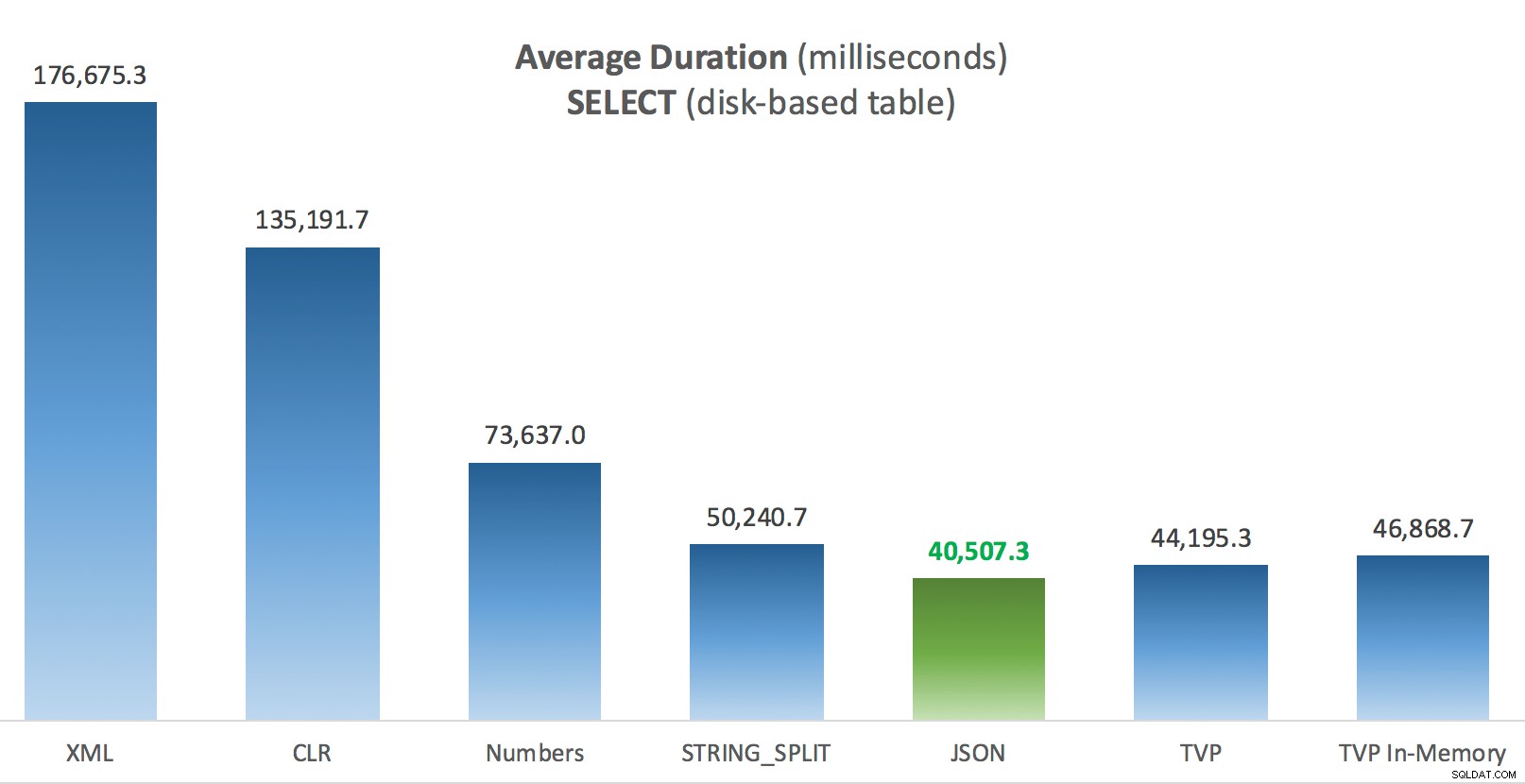 Durasi Rata-rata (milidetik) untuk SELECT terhadap tabel Postingan berbasis disk
Durasi Rata-rata (milidetik) untuk SELECT terhadap tabel Postingan berbasis disk
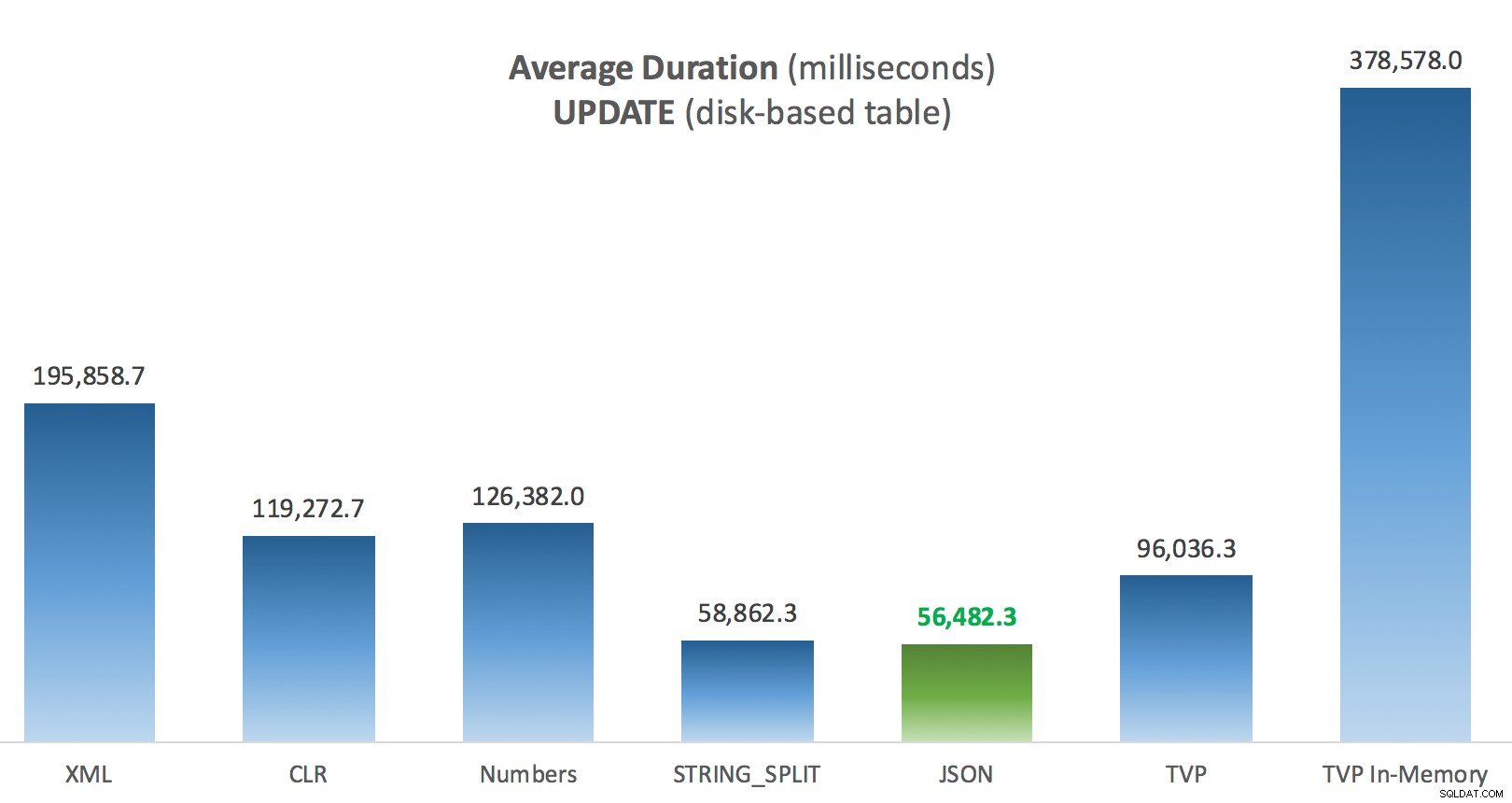 Durasi Rata-rata (milidetik) untuk PEMBARUAN terhadap tabel Postingan berbasis disk
Durasi Rata-rata (milidetik) untuk PEMBARUAN terhadap tabel Postingan berbasis disk
Hal yang paling menarik di sini, bagi saya, adalah seberapa buruk kinerja TVP yang dioptimalkan memori ketika membantu dengan UPDATE . Ternyata pemindaian paralel saat ini diblokir terlalu agresif ketika DML terlibat; Microsoft telah mengenali ini sebagai celah fitur, dan mereka berharap untuk segera mengatasinya. Perhatikan bahwa pemindaian paralel saat ini dimungkinkan dengan SELECT tapi sekarang diblokir untuk DML. (Ini tidak akan diselesaikan di SQL Server 2014, karena operasi pemindaian paralel khusus ini tidak tersedia di sana untuk operasi apa pun.) Ketika itu diperbaiki, atau ketika TVP Anda lebih kecil dan/atau paralelisme tidak menguntungkan, Anda akan melihat bahwa TVP yang dioptimalkan memori akan berkinerja lebih baik (polanya tidak bekerja dengan baik untuk kasus penggunaan khusus dari TVP yang relatif besar ini).
Untuk kasus khusus ini, berikut adalah paket untuk SELECT (yang bisa saya paksa untuk paralel) dan UPDATE (yang saya tidak bisa):
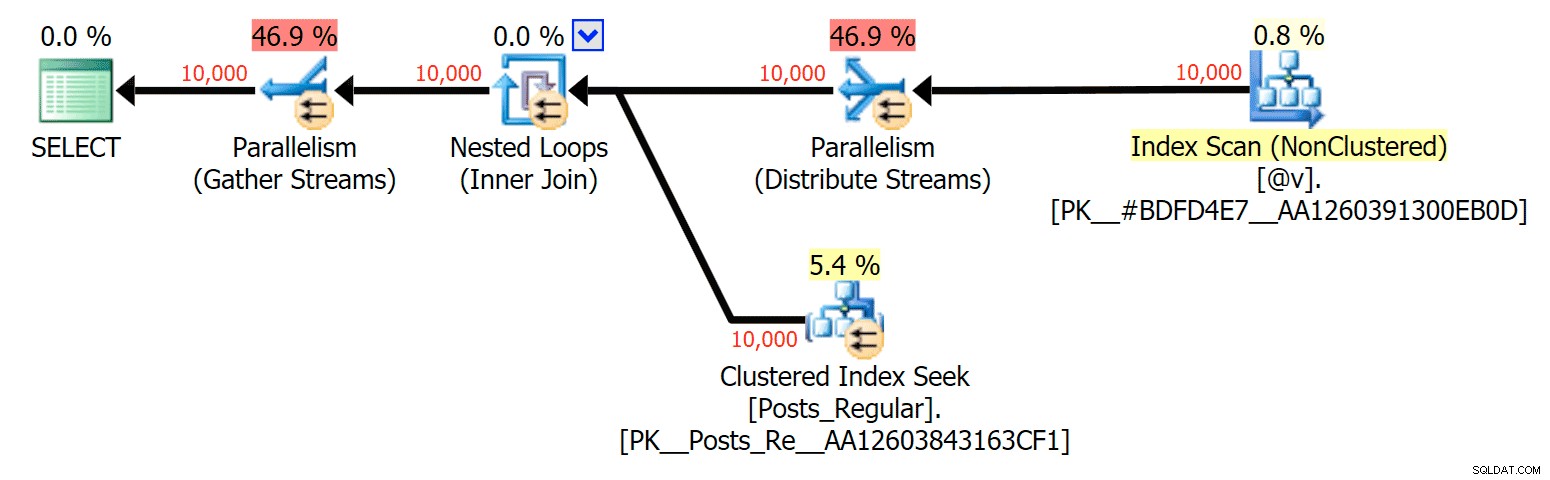 Paralelisme dalam paket SELECT menggabungkan tabel berbasis disk ke TVP dalam memori
Paralelisme dalam paket SELECT menggabungkan tabel berbasis disk ke TVP dalam memori
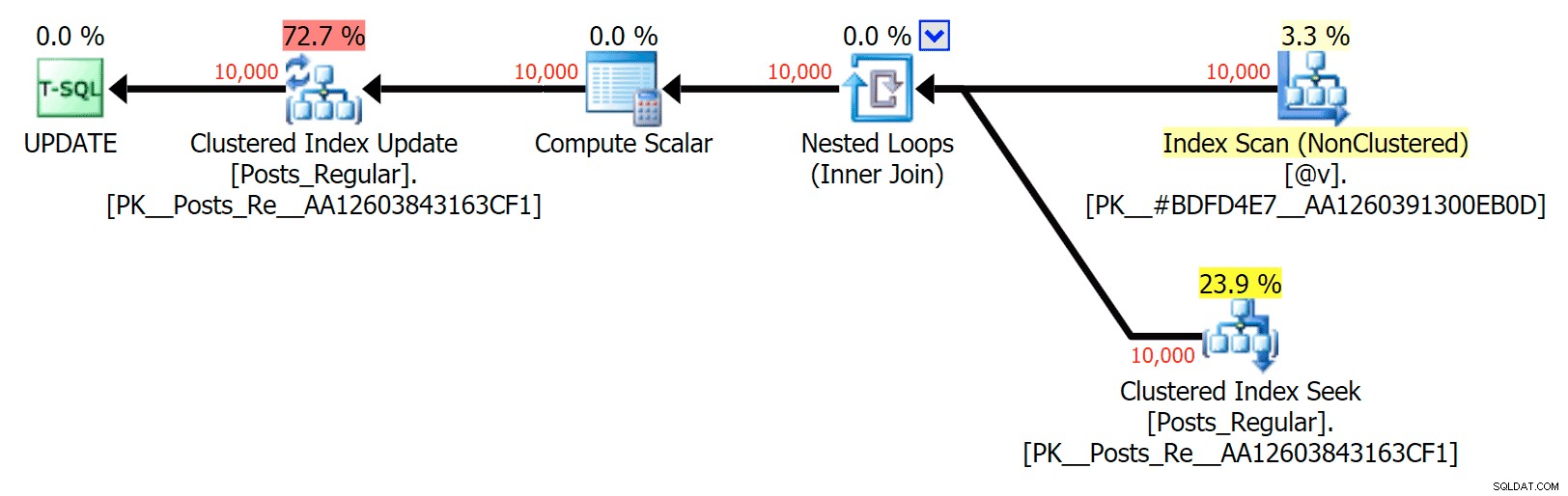 Tidak ada paralelisme dalam rencana UPDATE yang menggabungkan tabel berbasis disk ke dalam memori TVP
Tidak ada paralelisme dalam rencana UPDATE yang menggabungkan tabel berbasis disk ke dalam memori TVP
Hasil – Tabel dengan Memori yang Dioptimalkan
Sedikit lebih konsisten di sini – empat metode di sebelah kanan relatif sama, sedangkan tiga di sebelah kiri tampaknya sangat tidak diinginkan. Juga berikan perhatian khusus pada skala absolut dibandingkan dengan tabel berbasis disk – sebagian besar, menggunakan metode yang sama, dan bahkan tanpa paralelisme, Anda berakhir dengan operasi yang jauh lebih cepat terhadap tabel yang dioptimalkan memori, yang mengarah pada penggunaan CPU keseluruhan yang lebih rendah.
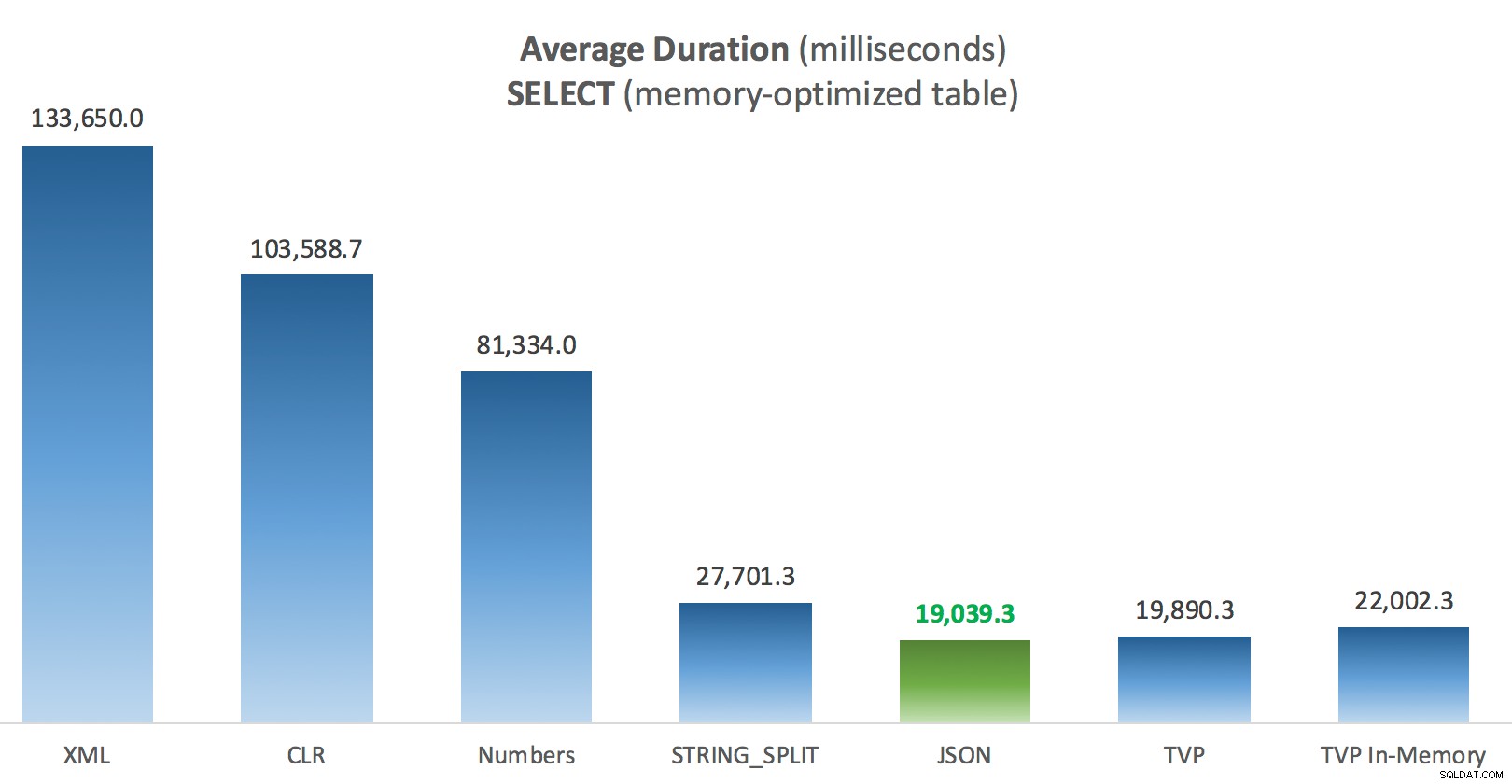 Durasi Rata-rata (milidetik) untuk SELECT terhadap tabel Postingan yang dioptimalkan memori
Durasi Rata-rata (milidetik) untuk SELECT terhadap tabel Postingan yang dioptimalkan memori
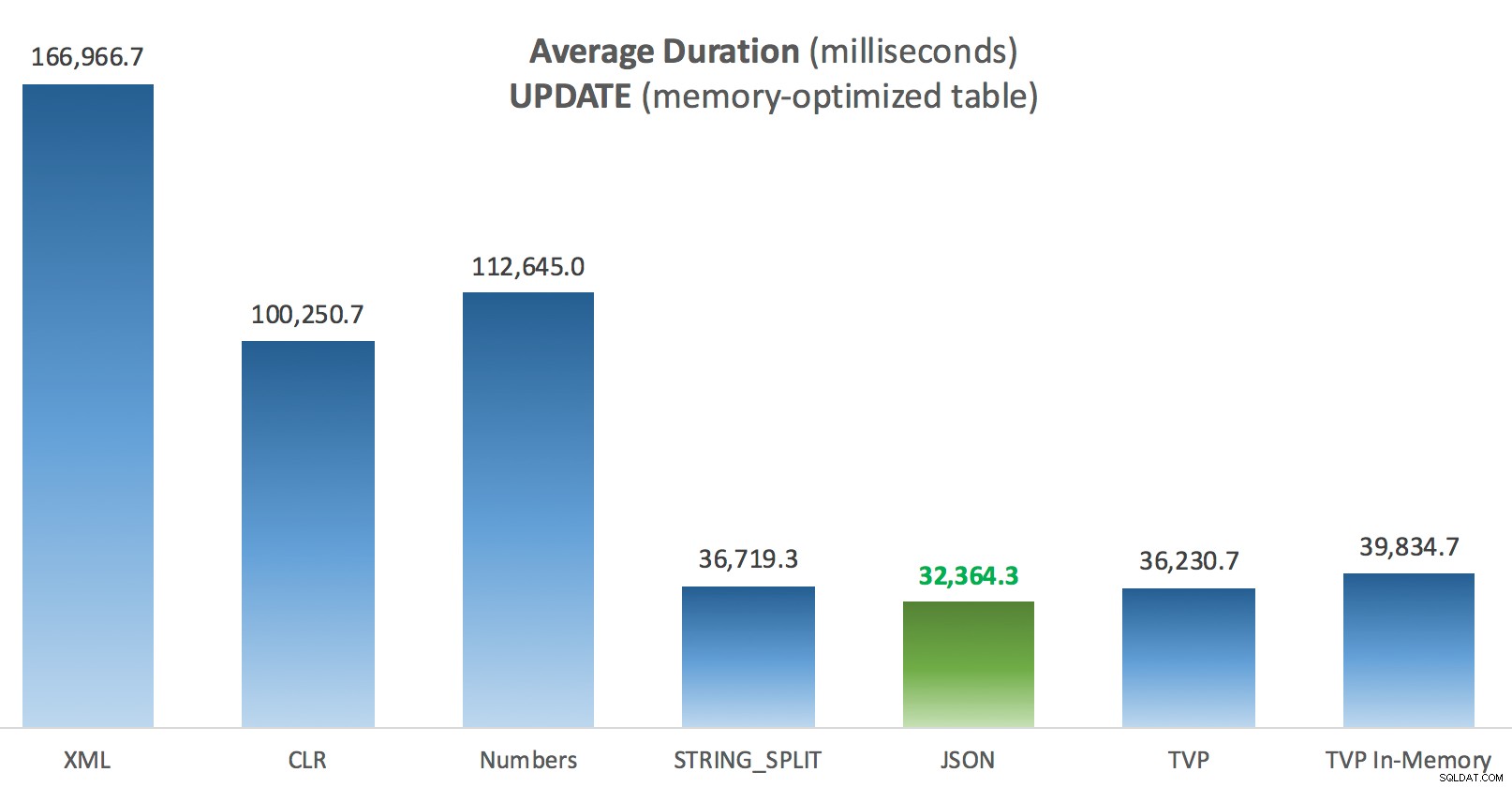 Durasi Rata-Rata (milidetik) untuk PEMBARUAN terhadap tabel Postingan yang dioptimalkan memori
Durasi Rata-Rata (milidetik) untuk PEMBARUAN terhadap tabel Postingan yang dioptimalkan memori
Kesimpulan
Untuk pengujian khusus ini, dengan ukuran data, distribusi, dan jumlah parameter tertentu, dan pada perangkat keras khusus saya, JSON adalah pemenang yang konsisten (walaupun sedikit). Namun, untuk beberapa tes lain di posting sebelumnya, pendekatan lain bernasib lebih baik. Hanya sebuah contoh tentang bagaimana apa yang Anda lakukan dan di mana Anda melakukannya dapat memiliki dampak dramatis pada efisiensi relatif dari berbagai teknik, berikut adalah hal-hal yang telah saya uji dalam seri singkat ini, dengan ringkasan saya tentang teknik mana yang harus dilakukan. gunakan dalam kasus itu, dan yang akan digunakan sebagai pilihan ke-2 atau ke-3 (misalnya, jika Anda tidak dapat menerapkan CLR karena kebijakan perusahaan atau karena Anda menggunakan Azure SQL Database, atau Anda tidak dapat menggunakan JSON atau STRING_SPLIT() karena Anda belum menggunakan SQL Server 2016). Perhatikan bahwa saya tidak kembali dan menguji ulang penugasan variabel dan SELECT INTO skrip menggunakan TVP – tes ini disiapkan dengan asumsi Anda sudah memiliki data dalam format CSV yang bagaimanapun juga harus dipecah terlebih dahulu. Umumnya, jika Anda dapat menghindarinya, jangan smoosh set Anda menjadi string yang dipisahkan koma sejak awal, IMHO.
| Sasaran | Pilihan pertama | Pilihan ke-2 (dan ke-3, jika sesuai) |
|---|---|---|
| Penetapan variabel sederhana | STRING_SPLIT() | CLR jika <2016 XML jika tidak ada CLR dan <2016 |
| PILIH KE | CLR | XML jika tidak ada CLR |
| PILIH KE (tanpa gulungan) | CLR | Tabel angka jika tidak ada CLR |
| PILIH KE (tanpa gulungan + MAXDOP 1) | STRING_SPLIT() | CLR jika <2016 Tabel angka jika tidak ada CLR dan <2016 |
| PILIH bergabung dengan daftar besar (berbasis disk) | JSON (int) | TVP jika <2016 |
| PILIH bergabung dengan daftar besar (dioptimalkan memori) | JSON (int) | TVP jika <2016 |
| PERBARUI bergabung dengan daftar besar (berbasis disk) | JSON (int) | TVP jika <2016 |
| PERBARUI bergabung dengan daftar besar (dioptimalkan memori) | JSON (int) | TVP jika <2016 |
Untuk pertanyaan spesifik Doug:JSON, STRING_SPLIT() , dan TVP memiliki kinerja yang agak mirip di seluruh pengujian ini rata-rata – cukup dekat sehingga TVP adalah pilihan yang jelas jika Anda tidak menggunakan SQL Server 2016. Jika Anda memiliki kasus penggunaan yang berbeda, hasil ini mungkin berbeda. Sangat .
Yang membawa kita ke moral ini cerita:Saya dan orang lain dapat melakukan tes kinerja yang sangat spesifik, berputar di sekitar fitur atau pendekatan apa pun, dan sampai pada beberapa kesimpulan tentang pendekatan mana yang tercepat. Tetapi ada begitu banyak variabel, saya tidak akan pernah memiliki kepercayaan diri untuk mengatakan "pendekatan ini selalu tercepat." Dalam skenario ini, saya berusaha sangat keras untuk mengontrol sebagian besar faktor yang berkontribusi, dan sementara JSON menang dalam keempat kasus, Anda dapat melihat bagaimana faktor-faktor berbeda tersebut memengaruhi waktu eksekusi (dan secara drastis demikian untuk beberapa pendekatan). selalu layak untuk membuat tes Anda sendiri, dan saya harap saya telah membantu menggambarkan bagaimana saya melakukan hal semacam itu.
Lampiran A :Kode Aplikasi Konsol
Tolong, jangan pilih-pilih tentang kode ini; itu benar-benar disatukan sebagai cara yang sangat sederhana untuk menjalankan prosedur tersimpan ini 1.000 kali dengan daftar yang benar dan DataTables yang dirakit dalam C #, dan untuk mencatat waktu yang dibutuhkan setiap loop ke tabel (untuk memastikan untuk memasukkan overhead terkait aplikasi dengan penanganan baik string besar atau koleksi). Saya dapat menambahkan penanganan kesalahan, loop secara berbeda (misalnya membuat daftar di dalam loop alih-alih menggunakan kembali satu unit kerja), dan seterusnya.
menggunakan Sistem;menggunakan System.Text;menggunakan System.Configuration;menggunakan System.Data;menggunakan System.Data.SqlClient; namespace SplitTesting{ class Program { static void Main(string[] args) { string operation ="Update"; if (args[0].ToString() =="-Pilih") { operation ="Pilih"; } var csv =new StringBuilder(); Elemen DataTable =DataTable baru(); elemen.Kolom.Tambah("nilai", typeof(int)); for (int i =1; i <=10.000; i++) { csv.Append((i*300).ToString()); if (i <10000) { csv.Append(","); } elemen.Baris.Tambah(i*300); } string[] metode ={ "Native", "CLR", "XML", "Angka", "JSON", "TVP", "TVP_InMemory" }; menggunakan (SqlConnection con =new SqlConnection()) { con.ConnectionString =ConfigurationManager.ConnectionStrings["primary"].ToString(); con.Buka(); SqlParameter p; foreach (metode string dalam metode) { SqlCommand cmd =new SqlCommand("dbo." + operasi + "Post_" + metode, con); cmd.CommandType =CommandType.StoredProcedure; if (metode =="TVP" || metode =="TVP_InMemory") { cmd.Parameters.Add("@PostList", SqlDbType.Structured).Nilai =elemen; } else { cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Nilai =csv.ToString(); } var timer =System.Diagnostics.Stopwatch.StartNew(); for (int x =1; x <=1000; x++) { if (operasi =="Pembaruan") { cmd.ExecuteNonQuery(); } else { SqlDataReader rdr =cmd.ExecuteReader(); rdr.Tutup(); } } timer.Stop(); long this_time =timer.ElapsedMilliseconds; // log time - prosedur logging menambahkan waktu clock dan // merekam memori/berbasis disk (ditentukan melalui sinonim) SqlCommand log =new SqlCommand("dbo.LogBatchTime", con); log.CommandType =CommandType.StoredProcedure; log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Nilai =operasi; log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Nilai =metode; log.Parameters.Add("@Waktu", SqlDbType.Int).Nilai =waktu_ini; log.ExecuteNonQuery(); Console.WriteLine(metode + " :" + this_time.ToString()); } } } }} Contoh penggunaan:
SplitTesting.exe -PilihSplitTesting.exe -Perbarui
Lampiran B :Fungsi, Prosedur, dan Tabel Logging
Berikut adalah fungsi yang diedit untuk mendukung varchar(max) (fungsi CLR sudah menerima nvarchar(max) dan saya masih enggan untuk mencoba mengubahnya):
BUAT FUNGSI dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [value] FROM STRING_SPLIT(@List, @Delimiter));GO CREATE FUNCTION dbo.XMLStrings ( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [value] =y.i.value('(./text())[1]', 'varchar(max)') FROM (PILIH x =CONVERT(XML, '' + REPLACE(@List, @Delimiter, '') + '').query('.')) SEBAGAI CROSS APPLY x.nodes('i') AS y(i));GO CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (PILIH [nilai] =SUBSTRING (@List, Number, CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number) FROM dbo.Numbers WHERE Number <=CONVERT(INT, LEN(@List)) AND SUBSTRING(@Delimiter + @List, Number , LEN(@Delimiter)) =@Delimiter );GO CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))KEMBALIKAN TABEL DENGAN SCH EMABINDINGAS RETURN (PILIH [nilai] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (nilai int '$'));GO Dan prosedur tersimpan terlihat seperti ini:
BUAT PROSEDUR dbo.UpdatePosts_Native @PostList varchar(max)ASBEGIN UPDATE p SET HitCount +=1 FROM dbo.Posts SEBAGAI p INNER GABUNG dbo.SplitStrings_Native(@PostList, ',') AS ON p.PostID =s [nilai];ENDGOCREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max)ASBEGIN PILIH p.PostID, p.HitCount FROM dbo.Posts SEBAGAI p INNER GABUNG dbo.SplitStrings_Native(@PostList, ',') AS s ON p. s.[value];ENDGO-- ulangi untuk 4 metode berbasis varchar(max) lainnya CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- alihkan _Regular ke _InMemoryASBEGIN SET NOCOUNT ON; UPDATE p SET HitCount +=1 FROM dbo.Posts SEBAGAI p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGOCREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- alihkan _SETInRegular ASON _SETInRegular ASON; PILIH p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGO-- ulangi untuk dalam memori
Dan terakhir, tabel dan prosedur logging:
CREATE TABLE dbo.SplitLog( LogID int IDENTITY(1,1) PRIMARY KEY, ClockTime datetime NOT NULL DEFAULT GETDATE(), OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory atau Posts_Regular Operasi varchar(32) NOT NULL DEFAULT 'Update', -- atau pilih Metode varchar(32) NOT NULL DEFAULT 'Native', -- atau TVP, JSON, dll. Timing int NOT NULL DEFAULT 0);GO CREATE PROCEDURE dbo.LogBatchTime @Operation varchar(32), @Method varchar(32), @Timing intASBEGIN SET NOCOUNT ON; INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing) SELECT base_object_name, @Operation, @Method, @Timing FROM sys.synonyms WHERE name =N'Posts';ENDGO -- dan kueri untuk menghasilkan grafik:;DENGAN x AS( SELECT OperatingTable,Operation,Method,Timing, Recency =ROW_NUMBER() OVER (PARTITION BY OperatingTable,Operation,Method ORDER BY ClockTime DESC) FROM dbo.SplitLog)SELECT OperatingTable,Operation,Method,AverageDuration =AVG(1.0*Timing) FROM x WHERE Recency <=3GROUP BY OperatingTable,Operation,Method;