Pada artikel ini, kita akan membahas kesalahan umum yang mungkin dihadapi oleh pengembang pemula saat merancang kode T-SQL. Selain itu, kita akan melihat praktik terbaik dan beberapa tips berguna yang dapat membantu Anda saat bekerja dengan SQL Server, serta solusi untuk meningkatkan kinerja.
Isi:
1. Tipe Data
2. *
3. Alias
4. Urutan kolom
5. TIDAK DI vs NULL
6. Format tanggal
7. Filter tanggal
8. perhitungan
9. Konversi implisit
10. SEPERTI &Indeks yang ditekan
11. Unicode vs ANSI
12. MENGUMPULKAN
13. KOLATASI BINER
14. Gaya kode
15. [var]char
16. Panjang data
17. ISNULL vs COALESCE
18. Matematika
19. UNION vs UNION SEMUA
20. Baca ulang
21. SubKueri
22. KASUS KAPAN
23. Fungsi skalar
24. TAMPILAN
25. KURSOR
26. STRING_CONCAT
27. Injeksi SQL
Jenis Data
Masalah utama yang kami hadapi saat bekerja dengan SQL Server adalah pilihan tipe data yang salah.
Asumsikan kita memiliki dua tabel yang identik:
DECLARE @Employees1 TABLE ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) , BirthDate VARCHAR(20))INSERT INTO @Employees1VALUES (123, 'YES', '2012-09-01')DECLARE @Employees2 TABLE ( EmployeeIDES2 TABLE ( INT PRIMARY KEY , IsMale BIT , BirthDate DATE)INSERT INTO @Employees2VALUES (123, 1, '2012-09-01')
Mari kita jalankan kueri untuk memeriksa apa perbedaannya:
DECLARE @BirthDate DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE BirthDate =@BirthDateSELECT * FROM @Employees2 WHERE BirthDate =@BirthDate
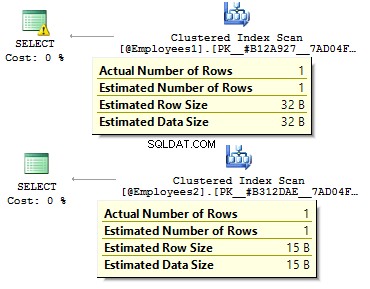
Dalam kasus pertama, tipe data lebih berlebihan daripada yang seharusnya. Mengapa kita harus menyimpan nilai bit sebagai YA/TIDAK baris? Mengapa kita harus menyimpan tanggal sebagai satu baris? Mengapa kita harus menggunakan BIGINT untuk karyawan di tabel, bukan INT ?
Ini mengarah pada kelemahan berikut:
- Tabel mungkin memakan banyak ruang di disk;
- Kita perlu membaca lebih banyak halaman dan memasukkan lebih banyak data di BufferPool untuk menangani data.
- Kinerja buruk.
*
Saya telah menghadapi situasi ketika pengembang mengambil semua data dari tabel, dan kemudian di sisi klien, gunakan DataReader untuk memilih bidang yang diperlukan saja. Saya tidak menyarankan menggunakan pendekatan ini:
GUNAKAN AdventureWorks2014GOSET STATISTICS TIME, IO ONSELECT *FROM Person.PersonSELECT BusinessEntityID , FirstName , MiddleName , LastNameFROM Person.PersonSET STATISTICS TIME, IO OFF
Akan ada perbedaan yang signifikan dalam waktu eksekusi query. Selain itu, indeks penutup dapat mengurangi sejumlah pembacaan logis.
Tabel 'Orang'. Hitungan pemindaian 1, pembacaan logis 3819, pembacaan fisik 3, ... Waktu Eksekusi SQL Server:Waktu CPU =31 md, waktu yang telah berlalu =1235 md. Tabel 'Orang'. Hitungan pemindaian 1, pembacaan logis 109, pembacaan fisik 1, ... Waktu Eksekusi SQL Server:Waktu CPU =0 md, waktu yang berlalu =227 md.
Alias
Mari kita buat tabel:
GUNAKAN AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') BUKAN NULL DROP TABLE Penjualan.UserCurrencyGOCREATE TABLE Penjualan.UserCurrency ( CurrencyCode NCHAR(3) PRIMARY KEY)MASUKKAN KE Penjualan.UserCurrencyVALUES ('USD') Asumsikan kita memiliki kueri yang mengembalikan jumlah baris identik di kedua tabel:
SELECT COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN ( SELECT CurrencyCode FROM Sales.UserCurrency )
Semuanya akan berfungsi seperti yang diharapkan, sampai seseorang mengganti nama kolom di Sales.UserCurrency tabel:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
Selanjutnya, kita akan menjalankan kueri dan melihat bahwa kita mendapatkan semua baris di Sales.Currency tabel, bukan 1 baris. Saat membangun rencana eksekusi, pada tahap pengikatan, SQL Server akan memeriksa kolom Sales.UserCurrency, itu tidak akan menemukan CurrencyCode di sana dan memutuskan bahwa kolom ini milik Sales.Currency meja. Setelah itu, pengoptimal akan menghapus CurrencyCode =CurrencyCode kondisi.
Jadi, saya sarankan menggunakan alias:
SELECT COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN ( SELECT u.CurrencyCode FROM Sales.UserCurrency u )
Urutan kolom
Asumsikan kita memiliki tabel:
JIKA OBJECT_ID('dbo.DatePeriod') BUKAN NULL DROP TABLE dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod ( StartDate DATE , EndDate DATE) Kami selalu memasukkan data di sana berdasarkan informasi tentang urutan kolom.
MASUKKAN KE dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Asumsikan seseorang mengubah urutan kolom:
BUAT TABEL dbo.DatePeriod ( Tanggal Akhir TANGGAL , Tanggal Mulai TANGGAL)
Data akan dimasukkan dalam urutan yang berbeda. Dalam hal ini, adalah ide yang baik untuk secara eksplisit menentukan kolom dalam pernyataan INSERT:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)SELECT '2015-01-01', '2015-01-31'
Ini contoh lain:
SELECT TOP(1) *FROM dbo.DatePeriodORDER OLEH 2 DESC
Pada kolom apa kita akan memesan data? Itu akan tergantung pada urutan kolom dalam sebuah tabel. Jika seseorang mengubah urutannya, kami mendapatkan hasil yang salah.
TIDAK DI vs NULL
Mari kita bicara tentang TIDAK DI pernyataan.
Misalnya, Anda perlu menulis beberapa pertanyaan:kembalikan catatan dari tabel pertama, yang tidak ada di tabel kedua dan ayat visa. Biasanya, pengembang junior menggunakan IN dan TIDAK DI :
DECLARE @t1 TABEL (t1 INT, UNIK CLUSTERED(t1))MASUKKAN KE @t1 NILAI (1), (2)DECLARE @t2 TABEL (t2 INT, UNIK CLUSTERED(t2))MASUKKAN KE @t2 NILAI (1 )PILIH *FROM @t1WHERE t1 NOT IN (PILIH t2 FROM @t2)PILIH *FROM @t1WHERE t1 IN (PILIH t2 FROM @t2)
Kueri pertama menghasilkan 2, yang kedua – 1. Selanjutnya, kami akan menambahkan nilai lain di tabel kedua – NULL :
MASUKKAN KE @t2 NILAI (1), (NULL)
Saat menjalankan kueri dengan NOT IN , kita tidak akan mendapatkan hasil apapun. Mengapa IN berfungsi dan NOT In tidak? Alasannya adalah SQL Server menggunakan TRUE , SALAH , dan TIDAK DIKETAHUI logika saat membandingkan data.
Saat menjalankan kueri, SQL Server menginterpretasikan kondisi IN dengan cara berikut:
a IN (1, NULL) ==a=1 OR a=NULL
TIDAK DI :
a NOT IN (1, NULL) ==a<>1 AND a<>NULL
Saat membandingkan nilai apa pun dengan NULL, SQL Server mengembalikan TIDAK DIKETAHUI. Entah 1=NULL atau NULL=NULL – keduanya menghasilkan TIDAK DIKETAHUI. Sejauh yang kita miliki DAN dalam ekspresi, kedua belah pihak mengembalikan UNKNOWN.
Saya ingin menunjukkan bahwa kasus ini tidak jarang terjadi. Misalnya, Anda menandai kolom sebagai NOT NULL. Setelah beberapa saat, pengembang lain memutuskan untuk mengizinkan NULL untuk kolom itu. Hal ini dapat menyebabkan situasi, ketika laporan klien berhenti bekerja setelah nilai NULL dimasukkan ke dalam tabel.
Dalam hal ini, saya akan merekomendasikan untuk mengecualikan nilai NULL:
PILIH *FROM @t1WHERE t1 NOT IN ( PILIH t2 FROM @t2 WHERE t2 NOT NULL )
Selain itu, dimungkinkan untuk menggunakan KECUALI :
PILIH * FROM @t1EXCEPTSELECT * FROM @t2
Atau, Anda dapat menggunakan TIDAK ADA :
PILIH *FROM @t1WHERE NOT EXISTS( PILIH 1 FROM @t2 WHERE t1 =t2 )
Opsi mana yang lebih disukai? Opsi terakhir dengan TIDAK ADA tampaknya menjadi yang paling produktif karena menghasilkan predikat pushdown . yang lebih optimal operator untuk mengakses data dari tabel kedua.
Sebenarnya, nilai NULL dapat mengembalikan hasil yang tidak diharapkan.
Pertimbangkan pada contoh khusus ini:
GUNAKAN AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color ='Grey'SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color <> 'Abu-abu'
Seperti yang Anda lihat, Anda tidak mendapatkan hasil yang diharapkan karena nilai NULL memiliki operator perbandingan terpisah:
SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NULLSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NOT NULL
Berikut adalah contoh lain dengan CHECK kendala:
JIKA OBJECT_ID('tempdb.dbo.#temp') BUKAN NULL DROP TABLE #tempGOCREATE TABLE #temp ( Color VARCHAR(15) --NULL , CONSTRAINT CK CHECK (Warna DI ('Hitam', 'Putih') )) Kami membuat tabel dengan izin untuk menyisipkan hanya warna putih dan hitam:
INSERT INTO #temp VALUES ('Hitam')(1 baris terpengaruh) Semuanya bekerja seperti yang diharapkan.
INSERT INTO #temp VALUES ('Merah')Pernyataan INSERT bertentangan dengan batasan CHECK...Pernyataan telah dihentikan. Sekarang, mari tambahkan NULL:
INSERT INTO #temp VALUES (NULL)(1 baris terpengaruh)
Mengapa batasan CHECK melewati nilai NULL? Nah, alasannya adalah cukup TIDAK SALAH syarat untuk membuat rekor. Solusinya adalah mendefinisikan kolom secara eksplisit sebagai NOT NULL atau gunakan NULL dalam batasan.
Format tanggal
Sangat sering, Anda mungkin mengalami kesulitan dengan tipe data.
Misalnya, Anda perlu mendapatkan tanggal saat ini. Untuk melakukan ini, Anda dapat menggunakan fungsi GETDATE:
PILIH GETDATE()
Kemudian cukup salin hasil yang dikembalikan dalam kueri yang diperlukan, dan hapus waktunya:
SELECT *FROM sys.objectsWHERE create_date <'2016-11-14'
Apakah itu benar?
Tanggal ditentukan oleh konstanta string:
SET LANGUAGE EnglishSET DATEFORMAT DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -dec-2016'SELECT @d1, @d2, @d3, @d4
Semua nilai memiliki interpretasi satu nilai:
----------- ----------- ----------- -----------2016-12 -05-05-12-2016-05-12-2016-12-05
Ini tidak akan menyebabkan masalah apa pun hingga kueri dengan logika bisnis ini dijalankan di server lain yang pengaturannya mungkin berbeda:
SET DATEFORMAT MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-des -2016'SELECT @d1, @d2, @d3, @d4
Meskipun demikian, opsi ini dapat menyebabkan interpretasi tanggal yang salah:
----------- ----------- ----------- -----------2016-05 -12-12-2016-2016-12-05-2016-12-05
Selain itu, kode ini dapat menyebabkan bug yang terlihat dan laten.
Perhatikan contoh berikut. Kita perlu memasukkan data ke tabel pengujian. Di server uji, semuanya bekerja dengan sempurna:
DECLARE @t TABLE (a DATETIME)INSERT INTO @t VALUES ('05/13/2016') Namun, di sisi klien, kueri ini akan mengalami masalah karena pengaturan server kami berbeda:
DECLARE @t TABLE (a DATETIME)SET DATEFORMAT DMYINSERT INTO @t NILAI ('05/13/2016') Msg 242, Level 16, State 3, Line 28Konversi tipe data varchar ke tipe data datetime menghasilkan nilai di luar rentang.
Jadi, format apa yang harus kita gunakan untuk mendeklarasikan konstanta tanggal? Untuk menjawab pertanyaan ini, jalankan kueri ini:
SET DATEFORMAT YMDSET LANGUAGE IndonesianDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112 'PILIH @d1, @d2, @d3, @d4GOSET LANGUAGE DeutschDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112'SELECT @d1, @d2, @d3, @d4
Interpretasi konstanta mungkin berbeda tergantung pada bahasa yang diinstal:
----------- ----------- ----------- -----------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ----------- ----------- ----------- -----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Jadi, lebih baik menggunakan dua opsi terakhir. Juga, saya ingin menambahkan bahwa untuk secara eksplisit menentukan tanggal bukanlah ide yang baik:
SET LANGUAGE FrenchDECLARE @d DATETIME ='12-jan-2016'Msg 241, Level 16, State 1, Line 29Échec de la konversi de la tanggal et/ou de l'heure partir d'une chaîne de caractères.
Oleh karena itu, jika Anda ingin konstanta dengan tanggal ditafsirkan dengan benar, maka Anda perlu menentukannya dalam format berikut YYYYMMDD.
Selain itu, saya ingin menarik perhatian Anda pada perilaku beberapa tipe data:
SET LANGUAGE EnglishSET DATEFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-01- 12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2
Tidak seperti DATETIME, DATE type diinterpretasikan dengan benar dengan berbagai pengaturan di server:
---------- ----------2016-01-12 2016-01-12---------- ------- ---2016-01-12 2016-12-01
Filter tanggal
Untuk melanjutkan, kami akan mempertimbangkan cara memfilter data secara efektif. Mari kita mulai dari mereka DATETIME/DATE:
GUNAKAN AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Sekarang, kami akan mencoba mencari tahu berapa banyak baris yang dikembalikan kueri untuk hari tertentu:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime ='20140716'
Kueri akan mengembalikan 0. Saat membuat rencana eksekusi, server SQL mencoba untuk memberikan string konstan ke tipe data kolom yang perlu kita filter:
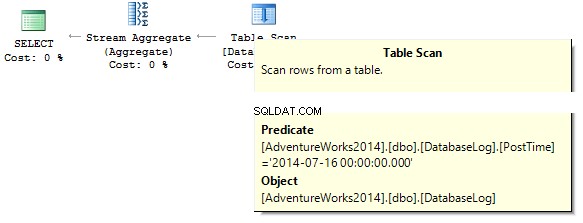
Buat indeks:
BUAT INDEKS IX_PostTime TIDAK TERMASUK DI dbo.DatabaseLog (PostTime)
Ada opsi yang benar dan salah untuk menghasilkan data. Misalnya, Anda perlu menghapus kolom waktu:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='20140716'
Atau kita perlu menentukan rentang:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime ANTARA '20140716' DAN '20140716 23:59:59.997'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140716' AND PostTime <'20140717'
Dengan mempertimbangkan pengoptimalan akun, saya dapat mengatakan bahwa kedua kueri ini adalah yang paling benar. Intinya adalah bahwa semua konversi dan perhitungan kolom indeks yang difilter dapat menurunkan kinerja secara drastis dan meningkatkan waktu pembacaan logika:
Tabel 'DatabaseLog'. Hitungan pindai 1, pembacaan logis 7, ...Tabel 'DatabaseLog'. Pindai hitungan 1, pembacaan logis 2, ...
Waktu Pasca bidang belum pernah dimasukkan dalam indeks sebelumnya, dan kami tidak dapat melihat efisiensi apa pun dalam menggunakan pendekatan yang benar ini dalam pemfilteran. Hal lain adalah ketika kita perlu mengeluarkan data selama sebulan:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE DATEPART(YEAR, PostTime) =2014 AND DATEPART(MONTH, Waktu Pasca) =7PILIH JUMLAH_BIG(*)FROM dbo.DatabaseLogWHERE YEAR(PostTime) =2014 DAN BULAN(PostTime) =7PILIH COUNT_BIG(*)FROM dbo.DatabaseLogWHERE EOMONTH(PostTime) ='20140731'SELECT COUNT_BIG(*)DatabaseLogWHE.REFROM PostTime>='20140701' DAN PostTime <'20140801'
Sekali lagi, opsi terakhir lebih disukai:
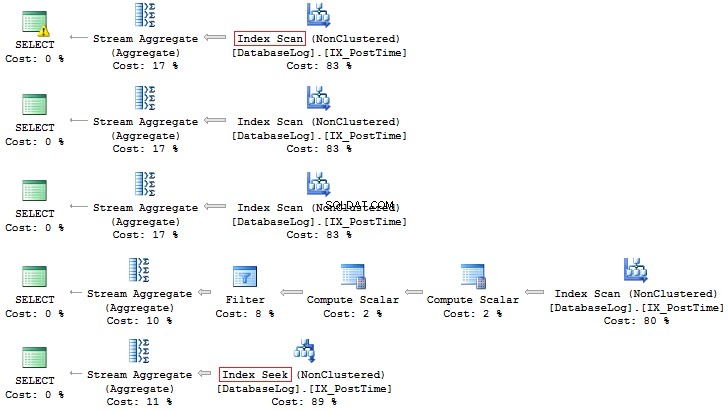
Selain itu, Anda selalu dapat membuat indeks berdasarkan bidang terhitung:
JIKA COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') BUKAN NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog TAMBAHKAN MonthLastDay SEBAGAI EOMONTH(PostDay) -PERSISTEDGOCRE_ Dibandingkan dengan kueri sebelumnya, perbedaan dalam pembacaan logis mungkin signifikan (jika tabel besar dipertanyakan):
SET STATISTICS IO ONSELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE MonthLastDay ='20140731'SET STATISTICS' IO OFLoFT Hitungan pindai 1, pembacaan logis 7, ...Tabel 'DatabaseLog'. Pindai hitungan 1, pembacaan logis 3, ...
Perhitungan
Seperti yang telah dibahas, setiap perhitungan pada kolom indeks menurunkan kinerja dan meningkatkan waktu logika berbunyi:
GUNAKAN AdventureWorks2014GOSET STATISTICS IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =5000Table 'Person'. Hitungan pindai 1, pembacaan logis 67, ...Tabel 'Orang'. Hitung pindai 0, pembacaan logis 3, ...
Jika kita melihat rencana eksekusi, maka yang pertama, SQL Server mengeksekusi IndexScan :
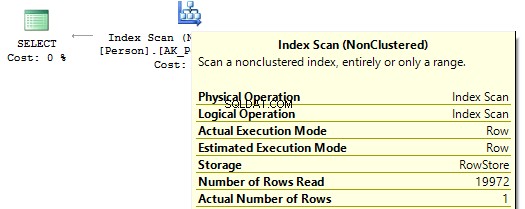
Kemudian, ketika tidak ada perhitungan pada kolom indeks, kita akan melihat IndexSeek :

Konversi implisit
Mari kita lihat dua kueri ini yang memfilter menurut nilai yang sama:
GUNAKAN AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'
Rencana eksekusi memberikan informasi berikut:
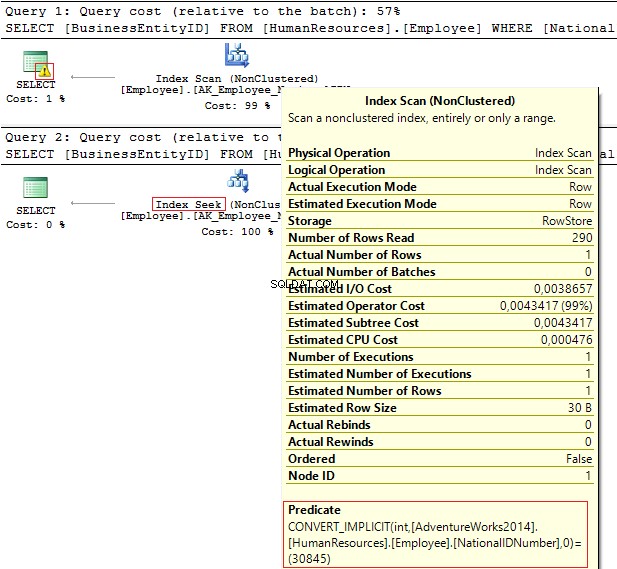
- Peringatan dan IndexScan pada rencana pertama
- IndexSeek – yang kedua.
Tabel 'Karyawan'. Hitungan pindai 1, pembacaan logis 4, ...Tabel 'Karyawan'. Hitung pindai 0, pembacaan logis 2, ...
NationalIDNumber kolom memiliki NVARCHAR(15) tipe data. Konstanta yang kami gunakan untuk memfilter data ditetapkan sebagai INT yang membawa kita ke konversi tipe data implisit. Pada gilirannya, itu dapat menurunkan kinerja. Anda dapat memantaunya ketika seseorang mengubah tipe data di kolom, namun kueri tidak diubah.
Penting untuk dipahami bahwa konversi tipe data implisit dapat menyebabkan kesalahan saat runtime. Misalnya, sebelum kolom Kodepos adalah numerik, ternyata kode pos dapat berisi huruf. Dengan demikian, tipe data telah diperbarui. Namun, jika kita memasukkan kode pos abjad, maka kueri lama tidak akan berfungsi lagi:
SELECT AddressIDFROM Person.[Address]WHERE PostalCode =92700SELECT AddressIDFROM Person.[Address]WHERE PostalCode ='92700'Msg 245, Level 16, State 1, Line 16Konversi gagal saat mengonversi nilai nvarchar 'K4B 1S2' ke tipe data int.
Contoh lain adalah ketika Anda perlu menggunakan EntityFramework pada proyek, yang secara default menafsirkan semua bidang baris sebagai Unicode:
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Penjualan.CustomerWHERE AccountNumber ='AW00000009'
Oleh karena itu, kueri yang salah dihasilkan:

Untuk mengatasi masalah ini, pastikan tipe data cocok.
SUKA &Indeks yang disembunyikan
Faktanya, memiliki indeks penutup tidak berarti Anda akan menggunakannya secara efektif.
Mari kita periksa pada contoh khusus ini. Asumsikan kita perlu menampilkan semua baris yang dimulai dengan…
GUNAKAN AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person.[Address]WHERE SUBSTRING(AddressLine1, 1, 3) ='100'SELECT AddressLine1FROM Person.[Address]WHERE LEFT(AddressLine1, 3) ='100'SELECT AddressLine1FROM Person.[ Address]WHERE CAST(AddressLine1 AS CHAR(3)) ='100'SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '100%'
Kami akan mendapatkan pembacaan logika dan rencana eksekusi berikut:
Tabel 'Alamat'. Hitungan pindai 1, pembacaan logis 216, ...Tabel 'Alamat'. Hitungan pindai 1, pembacaan logis 216, ...Tabel 'Alamat'. Hitungan pindai 1, pembacaan logis 216, ...Tabel 'Alamat'. Pindai hitungan 1, pembacaan logis 4, ...
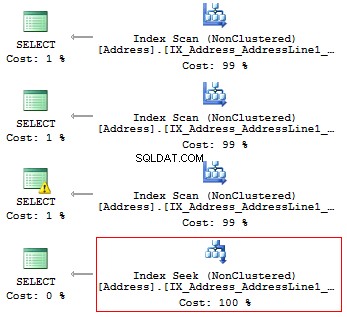
Jadi, jika ada indeks, tidak boleh mengandung perhitungan atau konversi jenis, fungsi, dll.
Tapi apa yang Anda lakukan jika Anda perlu menemukan kemunculan substring dalam sebuah string?
SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'v
Kami akan kembali ke pertanyaan ini nanti.
Unicode vs ANSI
Penting untuk diingat bahwa ada UNICODE dan ANSI string. Jenis UNICODE termasuk NVARCHAR/NCHAR (2 byte untuk satu simbol). Untuk menyimpan ANSI string, dimungkinkan untuk menggunakan VARCHAR/CHAR (1 byte ke 1 simbol). Ada juga TEXT/NTEXT , tetapi saya tidak menyarankan menggunakannya karena dapat menurunkan kinerja.
Jika Anda menentukan konstanta Unicode dalam kueri, maka itu perlu didahului dengan simbol N. Untuk memeriksanya, jalankan kueri berikut:
PILIH '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI UNICODE
Jika N tidak mendahului konstanta, maka SQL Server akan mencoba menemukan simbol yang sesuai dalam pengkodean ANSI. Jika gagal menemukan, maka akan muncul tanda tanya.
COLATE
Sangat sering, ketika diwawancarai untuk posisi Middle/Senior DB Developer, pewawancara sering menanyakan pertanyaan berikut:Apakah query ini akan mengembalikan data?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'SELECT @a, @bWHERE @a =@b
Tergantung. Pertama, simbol N tidak mendahului konstanta string, sehingga akan diinterpretasikan sebagai ANSI. Kedua, banyak yang bergantung pada nilai COLLATE saat ini, yang merupakan seperangkat aturan, saat memilih dan membandingkan data string.
GUNAKAN [master]GOIF DB_ID('test') BUKAN NULL BEGIN ALTER DATABASE test SET TUNGGAL_USER DENGAN ROLLBACK SEGERA DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CI_ASGOUSE testGODECLARE @a NCHAR(1) =' ) ='Ф'PILIH @a, @bWHERE @a =@b Pernyataan COLLATE ini akan mengembalikan tanda tanya karena simbolnya sama:
-------? ?
Jika kita mengubah pernyataan COLLATE untuk pernyataan lain:
UBAH tes DATABASE COLLATE Cyrillic_General_100_CI_AS
Dalam hal ini, kueri tidak akan menghasilkan apa-apa, karena karakter Sirilik akan ditafsirkan dengan benar.
Oleh karena itu, jika sebuah konstanta string mengambil UNICODE, maka perlu untuk mengatur N sebelum sebuah konstanta string. Namun, saya tidak akan merekomendasikan pengaturannya di mana-mana karena alasan yang telah kita diskusikan di atas.
Pertanyaan lain yang diajukan pada wawancara mengacu pada perbandingan baris.
Perhatikan contoh berikut:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a =@b, 'TRUE', 'FALSE')
Apakah baris ini sama? Untuk memeriksa ini, kita perlu secara eksplisit menentukan COLLATE:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Karena ada COLLATE case-sensitive (CS) dan case-insensitive (CI) saat membandingkan dan memilih baris, kami tidak dapat mengatakan dengan pasti apakah keduanya sama. Selain itu, ada berbagai COLLATE baik di server uji maupun di sisi klien.
Ada kasus ketika COLLATEs dari basis target dan tempdb tidak cocok.
Buat database dengan COLLATE:
GUNAKAN [master]GOIF DB_ID('test') BUKAN NULL BEGIN ALTER DATABASE test SET TUNGGAL_USER DENGAN ROLLBACK SEGERA DROP DATABASE testENDGOCREATE DATABASE test COLLATE Albania_100_CS_ASGOUSE testGOCREATE TABLE t (c CHARS INTO(1)) ')GOIF OBJECT_ID('tempdb.dbo.#t1') BUKAN NULL DROP TABLE #t1IF OBJECT_ID('tempdb.dbo.#t2') BUKAN NULL DROP TABLE #t2IF OBJECT_ID('tempdb.dbo.#t3') BUKAN NULL DROP TABLE #t3GOCREATE TABLE #t1 (c CHAR(1))INSERT INTO #t1 VALUES ('a')CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)INSERT INTO #t2 VALUES ('a') SELECT c =CAST('a' AS CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation ')UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') DARI # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') DARI @t Saat membuat tabel, itu mewarisi COLLATE dari database. Satu-satunya perbedaan untuk tabel sementara pertama, di mana kita menentukan struktur secara eksplisit tanpa COLLATE, adalah bahwa ia mewarisi COLLATE dari tempdb basis data.
------ --------------------------tempdb Cyrillic_General_CI_AStest Albanian_100_CS_ASt Albanian_100_CS_AS#t1 Cyrillic_General_CI_AS#t2 Albanian_100_CS_AS#t3 Albanian_100_CS_AS@t Albania_100_CS_AS
Saya akan menjelaskan kasus ketika COLLATEs tidak cocok pada contoh tertentu dengan #t1.
Misalnya, data tidak difilter dengan benar, karena COLLATE mungkin tidak memperhitungkan kasus:
PILIH *FROM #t1WHERE c ='A'
Atau, kami mungkin mengalami konflik untuk menghubungkan tabel dengan COLLATE yang berbeda:
PILIH *FROM #t1JOIN t ON [#t1].c =t.c
Semuanya tampak berfungsi sempurna di server uji, sedangkan di server klien kami mendapatkan kesalahan:
Msg 468, Level 16, State 9, Line 93Tidak dapat menyelesaikan konflik pemeriksaan antara "Albanian_100_CS_AS" dan "Cyrillic_General_CI_AS" dalam operasi yang sama.
Untuk mengatasinya, kita harus mengatur peretasan di mana-mana:
PILIH *FROM #t1JOIN t ON [#t1].c =t.c COLLATE database_default
BINARY COLLATE
Sekarang, kita akan mengetahui cara menggunakan COLLATE untuk keuntungan Anda.
Perhatikan contoh dengan kemunculan substring dalam string:
SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'
Dimungkinkan untuk mengoptimalkan kueri ini dan mengurangi waktu eksekusinya.
Pada awalnya, kita perlu membuat tabel besar:
GUNAKAN [master]GOIF DB_ID('test') BUKAN NULL BEGIN ALTER DATABASE test SET TUNGGAL_USER DENGAN ROLLBACK SEGERA DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CS_ASGOALTER uji DATABASE MODIFY 'test FILE' (NAMA =NAMA SALTER) DATABASE test MODIFY FILE (NAME =N'test_log', SIZE =64MB)GOUSE testGOCREATE TABLE t ( ansi VARCHAR(100) NOT NULL , unicod NVARCHAR(100) NOT NULL)GO;DENGAN E1(N) AS ( SELECT * FROM ( NILAI (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N ) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b)INSERT INTO tSELECT v, vFROM ( SELECT TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8) t Buat kolom terhitung dengan COLLATEs biner dan indeks:
ALTER TABLE t TAMBAHKAN ansi_bin SEBAGAI UPPER(ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t TAMBAHkan unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2CREATE NONCLUSTERED INDEX ON t (ansi)CREATE NONCLUSTER ansi_bin)BUAT INDEKS NONCLUSTERED unicod_bin ON t (unicod_bin)
Jalankan proses penyaringan:
SET STATISTIK WAKTU, IO ONSELECT COUNT_BIG(*)FROM tWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE unicod LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SET STATISTICS TIME, IO OFF
Seperti yang Anda lihat, kueri ini mengembalikan hasil berikut:
Waktu Eksekusi SQL Server:Waktu CPU =350 md, waktu berlalu =354 md. Waktu Eksekusi SQL Server:Waktu CPU =335 md, waktu berlalu =355 md. Waktu Eksekusi SQL Server:Waktu CPU =16 md, waktu berlalu =18 ms.Waktu Eksekusi Server SQL:Waktu CPU =17 md, waktu yang berlalu =18 md.
Intinya adalah bahwa filter berdasarkan perbandingan biner membutuhkan waktu lebih sedikit. Jadi, jika Anda perlu memfilter kemunculan string dengan sering dan cepat, maka dimungkinkan untuk menyimpan data dengan COLLATE yang diakhiri dengan BIN. Padahal, perlu diperhatikan bahwa semua biner COLLATE peka huruf besar/kecil.
Gaya kode
Gaya pengkodean sangat individual. Namun, kode ini harus dikelola oleh pengembang lain dan sesuai dengan aturan tertentu.
Buat database dan tabel terpisah di dalamnya:
GUNAKAN [master]GOIF DB_ID('test') BUKAN NULL MULAI ALTER DATABASE test SET TUNGGAL_USER DENGAN ROLLBACK SEGERA DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_CI_ASGOUSE testGOCREATE TABLE KEY INTPloyee dboprem>pegawai (
Kemudian, tulis kuerinya: pilih id karyawan dari karyawan
Sekarang, ubah COLLATE menjadi yang peka huruf besar/kecil:
UBAH tes DATABASE COLLATE Latin1_General_CS_AI
Kemudian, coba jalankan kueri lagi:
Msg 208, Level 16, State 1, Line 19Nama objek 'karyawan' tidak valid.
Pengoptimal menggunakan aturan untuk COLLATE saat ini pada langkah pengikatan saat memeriksa tabel, kolom, dan objek lain serta membandingkan setiap objek pohon sintaks dengan objek nyata dari katalog sistem.
Jika Anda ingin membuat kueri secara manual, maka Anda harus selalu menggunakan huruf besar/kecil yang benar dalam nama objek.
Adapun variabel, COLLATEs diwarisi dari database master. Jadi, Anda juga perlu menggunakan kasus yang benar untuk menanganinya:
SELECT DATABASEPROPERTYEX('master', 'collation')DECLARE @EmpID INT =1SELECT @empid
Dalam hal ini, Anda tidak akan mendapatkan kesalahan:
-----------------------Cyrillic_General_CI_AS------------1
Namun, kesalahan kasus mungkin muncul di server lain:
--------------------------Latin1_General_CS_ASMsg 137, Level 15, State 2, Line 4Harus mendeklarasikan variabel skalar "@empid". [var]char
Seperti yang Anda ketahui, ada perbaikan (CHAR , NCHAR ) dan variabel (VARCHAR , NVARCHAR ) tipe data:
DECLARE @a CHAR(20) ='text' , @b VARCHAR(20) ='text'SELECT LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'SELECT [a =b] =IIF(@a =@b, 'TRUE', 'FALSE') , [b =a] =IIF(@b =@a, 'TRUE', 'FALSE') , [a LIKE b] =IIF(@a LIKE @b, 'TRUE', 'FALSE') , [b LIKE a] =IIF(@ b LIKE @a, 'TRUE', 'FALSE')
Jika sebuah baris memiliki panjang yang tetap, katakanlah 20 simbol, tetapi Anda hanya menulis 4 simbol, maka SQL Server akan menambahkan 16 kosong di sebelah kanan secara default:
------------------------------------ ----------- -----------4 4 20 4 "teks" "teks"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Perhatikan contoh berikut:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333
Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
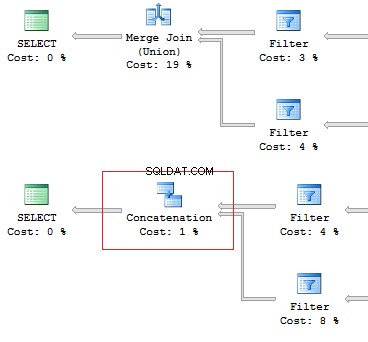
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLine
As we have OR in the statement, we will receive IndexScan:
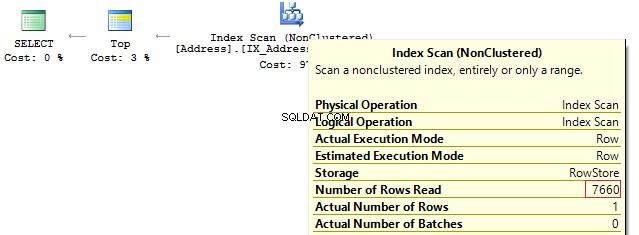
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
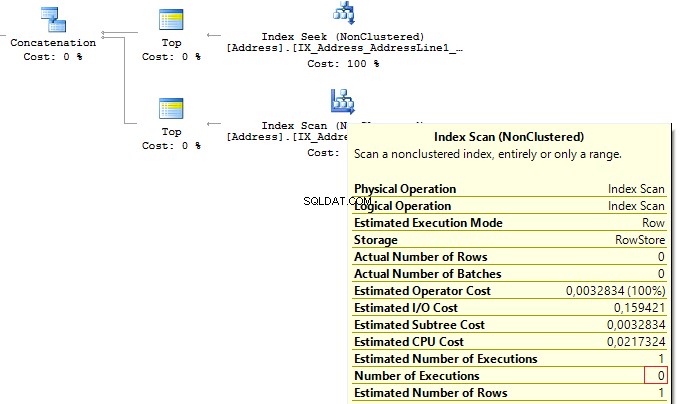
Tabel 'Meja Kerja'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
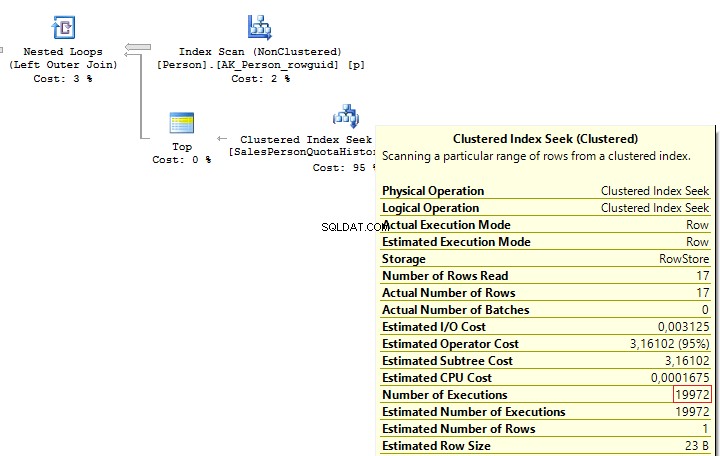
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1
Kami mendapatkan hasil berikut:
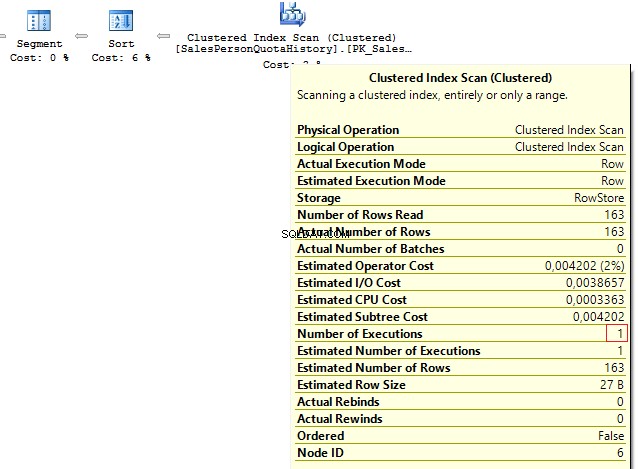
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))END
Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) END
Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Perhatikan contoh berikut:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDEND
The queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b----------- -----------0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tbl
We receive the same result:
a b----------- -----------0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tbl
Result:
a b c----------- ----------- -----------0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
Look at the execution plan in the case of using a view:
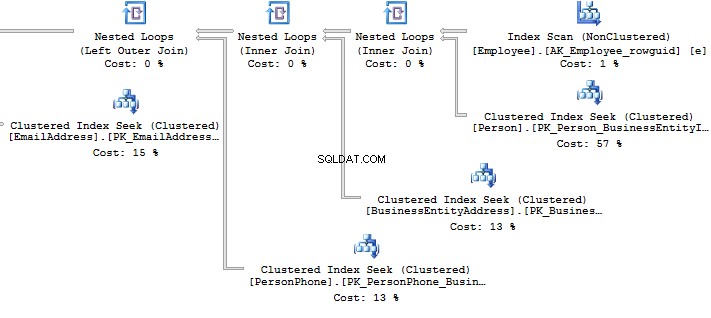
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
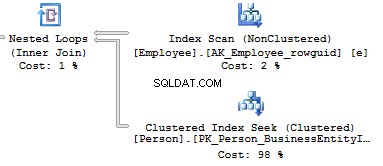
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTime
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
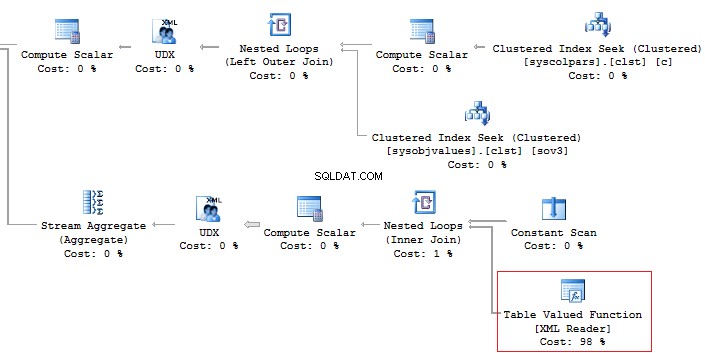
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
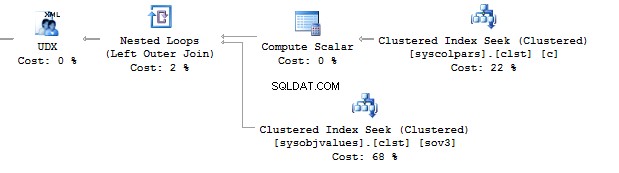
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1
If we add any additional value to the property,
SET @param ='1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...} Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.