Dalam posting terakhir saya, saya memulai serangkaian untuk mencakup pemeriksaan kesehatan proaktif yang penting untuk SQL Server Anda. Kami mulai dengan ruang disk, dan dalam posting ini kami akan membahas tugas pemeliharaan. Salah satu tanggung jawab mendasar DBA adalah memastikan bahwa tugas pemeliharaan berikut berjalan secara teratur:
- Cadangan
- Pemeriksaan integritas
- Pemeliharaan indeks
- Pembaruan statistik
Taruhan saya adalah Anda sudah memiliki pekerjaan untuk mengelola tugas-tugas ini. Dan saya juga berani bertaruh bahwa Anda memiliki pemberitahuan yang dikonfigurasi untuk mengirim email kepada Anda dan tim Anda jika pekerjaan gagal. Jika keduanya benar, maka Anda sudah proaktif tentang pemeliharaan. Dan jika Anda tidak melakukan keduanya, itu adalah sesuatu yang harus diperbaiki sekarang – seperti, berhenti membaca ini, unduh skrip Ola Hallengren, jadwalkan, dan pastikan Anda mengatur notifikasi. (Alternatif lain khusus untuk pemeliharaan indeks, yang juga kami rekomendasikan kepada pelanggan, adalah SQL Sentry Fragmentation Manager.)
Jika Anda tidak tahu apakah pekerjaan Anda disetel ke email Anda jika gagal, gunakan kueri ini:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Namun, bersikap proaktif tentang pemeliharaan melangkah lebih jauh. Selain memastikan pekerjaan Anda berjalan, Anda perlu tahu berapa lama waktu yang dibutuhkan. Anda dapat menggunakan tabel sistem di msdb untuk memantau ini:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Atau, jika Anda menggunakan skrip dan informasi logging Ola, Anda dapat menanyakan tabel CommandLog-nya:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Skrip di atas mencantumkan durasi pencadangan untuk setiap pencadangan penuh untuk database AdventureWorks2014. Anda dapat mengharapkan bahwa durasi tugas pemeliharaan perlahan-lahan akan meningkat seiring waktu, karena database tumbuh lebih besar. Dengan demikian, Anda mencari peningkatan besar, atau penurunan tak terduga, dalam durasi. Misalnya, saya memiliki klien dengan durasi pencadangan rata-rata kurang dari 30 menit. Tiba-tiba, pencadangan mulai memakan waktu lebih dari satu jam. Basis data tidak berubah secara signifikan dalam ukuran, tidak ada pengaturan yang berubah untuk instans atau basis data, tidak ada yang berubah dengan konfigurasi perangkat keras atau disk. Beberapa minggu kemudian, durasi pencadangan turun kembali menjadi kurang dari setengah jam. Sebulan setelah itu, mereka naik lagi. Kami akhirnya menghubungkan perubahan durasi pencadangan dengan failover antara node cluster. Pada satu node, pencadangan memakan waktu kurang dari setengah jam. Di sisi lain, mereka membutuhkan waktu lebih dari satu jam. Sedikit penyelidikan tentang konfigurasi NIC dan fabric SAN dan kami dapat menemukan masalahnya.
Memahami waktu rata-rata eksekusi untuk operasi CHECKDB juga penting. Ini adalah sesuatu yang dibicarakan oleh Paul dalam Acara Perendaman Ketersediaan Tinggi dan Pemulihan Bencana kami:Anda harus tahu berapa lama CHECKDB biasanya berjalan, sehingga jika Anda menemukan korupsi dan Anda menjalankan pemeriksaan di seluruh basis data, Anda tahu berapa lama seharusnya ambil untuk CHECKDB untuk menyelesaikan. Ketika bos Anda bertanya, “Berapa lama lagi sampai kita tahu sejauh mana masalahnya?” Anda akan dapat memberikan jawaban kuantitatif tentang jumlah waktu minimum yang Anda perlukan untuk menunggu. Jika CHECKDB membutuhkan waktu lebih lama dari biasanya, berarti Anda mengetahui bahwa ia menemukan sesuatu (yang mungkin belum tentu rusak; Anda harus selalu membiarkan pemeriksaan selesai).
Sekarang, jika Anda mengelola ratusan database, Anda tidak ingin menjalankan kueri di atas untuk setiap database, atau setiap pekerjaan. Sebagai gantinya, Anda mungkin hanya ingin mencari pekerjaan yang berada di luar durasi rata-rata dengan persentase tertentu, yang bisa Anda dapatkan menggunakan kueri ini:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Kueri ini mencantumkan pekerjaan yang memakan waktu 25% lebih lama dari rata-rata. Kueri akan memerlukan beberapa penyesuaian untuk memberikan informasi spesifik yang Anda inginkan – beberapa pekerjaan dengan durasi kecil (misalnya kurang dari 5 menit) akan muncul jika hanya memerlukan beberapa menit tambahan – yang mungkin tidak menjadi masalah. Namun demikian, kueri ini adalah awal yang baik, dan menyadari bahwa ada banyak cara untuk menemukan penyimpangan – Anda juga dapat membandingkan setiap eksekusi dengan eksekusi sebelumnya dan mencari pekerjaan yang membutuhkan persentase tertentu lebih lama dari sebelumnya.
Jelas, durasi pekerjaan adalah pengidentifikasi paling logis untuk digunakan untuk potensi masalah – apakah itu pekerjaan cadangan, pemeriksaan integritas, atau pekerjaan yang menghapus statistik fragmentasi dan pembaruan. Saya telah menemukan bahwa variasi terbesar dalam durasi biasanya dalam tugas untuk menghapus fragmentasi dan memperbarui statistik. Bergantung pada ambang batas Anda untuk reorg versus membangun kembali, dan volatilitas data Anda, Anda mungkin pergi berhari-hari dengan sebagian besar reorg, lalu tiba-tiba memiliki beberapa indeks membangun kembali menendang untuk tabel besar, di mana pembangunan kembali itu sepenuhnya mengubah durasi rata-rata. Anda mungkin ingin mengubah ambang batas untuk beberapa indeks, atau menyesuaikan faktor pengisian, sehingga pembangunan kembali terjadi lebih sering, atau lebih jarang – tergantung pada indeks dan tingkat fragmentasi. Untuk melakukan penyesuaian ini, Anda perlu melihat seberapa sering setiap indeks dibangun kembali atau diatur ulang, yang hanya dapat Anda lakukan jika Anda menggunakan skrip Ola dan masuk ke tabel CommandLog, atau jika Anda telah menggulirkan solusi Anda sendiri dan sedang masuk setiap reorg atau membangun kembali. Untuk melihat ini menggunakan tabel CommandLog, Anda dapat mulai dengan memeriksa untuk melihat indeks mana yang paling sering diubah:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
Dari output ini, Anda dapat mulai melihat tabel mana (dan karenanya indeks) yang memiliki volatilitas paling tinggi, lalu menentukan apakah ambang batas untuk reorg versus rekondisi perlu disesuaikan, atau faktor pengisian diubah.
Membuat Hidup Lebih Mudah
Sekarang, ada solusi yang lebih mudah daripada menulis kueri Anda sendiri, selama Anda menggunakan SQL Sentry Event Manager (EM). Alat ini memantau semua pekerjaan Agen yang disiapkan pada instans, dan menggunakan tampilan kalender, Anda dapat dengan cepat melihat pekerjaan mana yang gagal, dibatalkan, atau berjalan lebih lama dari biasanya:
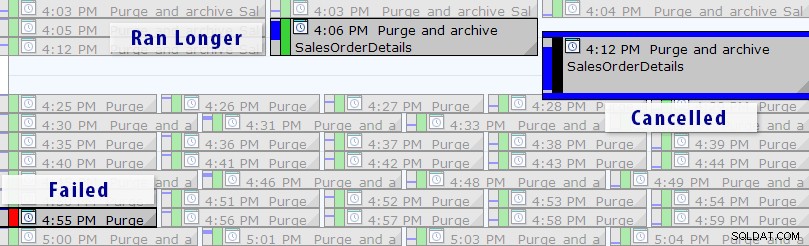 tampilan kalender SQL Sentry Event Manager (dengan label ditambahkan di Photoshop)
tampilan kalender SQL Sentry Event Manager (dengan label ditambahkan di Photoshop)
Anda juga dapat menelusuri eksekusi individu untuk melihat berapa lama waktu yang dibutuhkan untuk menjalankan pekerjaan, dan ada juga grafik runtime yang berguna yang memungkinkan Anda untuk dengan cepat memvisualisasikan pola apa pun dalam anomali durasi atau kondisi kegagalan. Dalam hal ini, saya dapat melihat bahwa setiap 15 menit, durasi runtime untuk pekerjaan khusus ini melonjak hampir 400%:
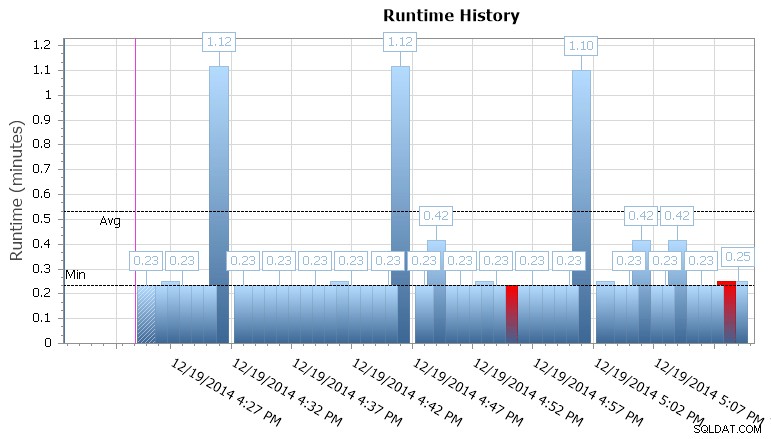 Grafik runtime SQL Sentry Event Manager
Grafik runtime SQL Sentry Event Manager
Ini memberi saya petunjuk bahwa saya harus melihat pekerjaan terjadwal lainnya yang mungkin menyebabkan beberapa masalah konkurensi di sini. Saya dapat memperkecil lagi kalender untuk melihat pekerjaan lain yang berjalan pada waktu yang sama, atau saya bahkan mungkin tidak perlu melihat untuk mengetahui bahwa ini adalah beberapa pekerjaan pelaporan atau pencadangan yang berjalan di database ini.
Ringkasan
Saya berani bertaruh bahwa sebagian besar dari Anda sudah memiliki pekerjaan pemeliharaan yang diperlukan, dan Anda juga telah menyiapkan pemberitahuan untuk kegagalan pekerjaan. Jika Anda tidak terbiasa dengan durasi rata-rata untuk pekerjaan Anda, maka itulah langkah Anda selanjutnya untuk menjadi proaktif. Catatan:Anda mungkin juga perlu memeriksa untuk melihat berapa lama Anda menyimpan riwayat pekerjaan. Saat mencari penyimpangan dalam durasi pekerjaan, saya lebih suka melihat data beberapa bulan, daripada beberapa minggu. Anda tidak perlu mengingat waktu berjalan tersebut, tetapi setelah Anda memverifikasi bahwa Anda menyimpan cukup data untuk memiliki riwayat yang digunakan untuk penelitian, maka mulailah mencari variasi secara teratur. Dalam skenario yang ideal, peningkatan waktu proses dapat memperingatkan Anda tentang potensi masalah, memungkinkan Anda untuk mengatasinya sebelum masalah terjadi di lingkungan produksi Anda.