Di bagian pertama seri ini, saya memperkenalkan terminologi dasar seputar logging, jadi saya sarankan Anda membacanya sebelum melanjutkan dengan posting ini. Semua hal lain yang akan saya bahas dalam seri ini membutuhkan pengetahuan tentang beberapa arsitektur log transaksi, jadi itulah yang akan saya bahas kali ini. Meskipun Anda tidak akan mengikuti seri ini, beberapa konsep yang akan saya jelaskan di bawah ini patut diketahui untuk tugas sehari-hari yang ditangani DBA dalam produksi.
Hirarki Struktural
Log transaksi diatur secara internal menggunakan hierarki tiga tingkat seperti yang ditunjukkan pada gambar 1 di bawah.
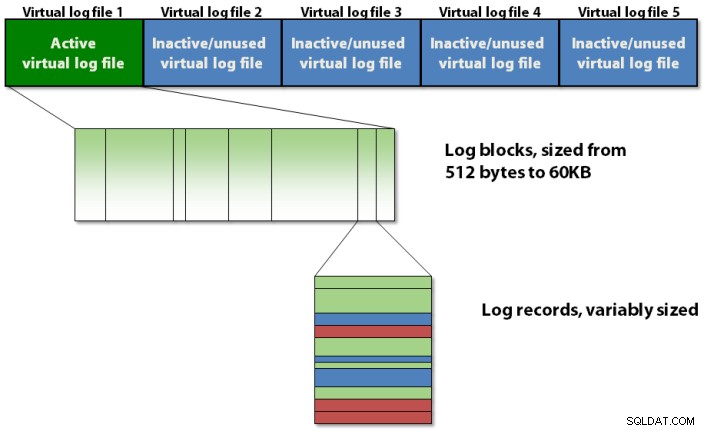 Gambar 1:Hirarki struktural tiga tingkat dari log transaksi
Gambar 1:Hirarki struktural tiga tingkat dari log transaksi
Log transaksi berisi file log virtual, yang berisi blok log, yang menyimpan catatan log yang sebenarnya.
File Log Virtual
Log transaksi dibagi menjadi beberapa bagian yang disebut file log virtual , biasa disebut VLFs . Ini dilakukan untuk membuat operasi pengelolaan di log transaksi lebih mudah bagi manajer log di SQL Server. Anda tidak dapat menentukan berapa banyak VLF yang dibuat oleh SQL Server saat database pertama kali dibuat atau file log bertambah secara otomatis, tetapi Anda dapat memengaruhinya. Algoritma untuk berapa banyak VLF yang dibuat adalah sebagai berikut:
- Ukuran file log kurang dari 64MB:buat 4 VLF, masing-masing berukuran sekitar 16 MB
- Ukuran file log dari 64MB hingga 1GB :buat 8 VLF, masing-masing kira-kira 1/8 dari ukuran total
- Ukuran file log lebih besar dari 1 GB:buat 16 VLF, masing-masing kira-kira 1/16 dari ukuran total
Sebelum SQL Server 2014, ketika file log tumbuh secara otomatis, jumlah VLF baru yang ditambahkan ke akhir file log ditentukan oleh algoritme di atas, berdasarkan ukuran pertumbuhan otomatis. Namun, dengan menggunakan algoritme ini, jika ukuran pertumbuhan otomatis kecil, dan file log mengalami banyak pertumbuhan otomatis, ini dapat menyebabkan sejumlah besar VLF kecil (disebut fragmentasi VLF ) yang dapat menjadi masalah kinerja yang besar untuk beberapa operasi (lihat di sini).
Karena masalah ini, di SQL Server 2014 algoritme berubah untuk pertumbuhan otomatis file log. Jika ukuran pertumbuhan otomatis kurang dari 1/8 dari total ukuran file log, hanya satu VLF baru yang dibuat, jika tidak, algoritme lama akan digunakan. Ini secara drastis mengurangi jumlah VLF untuk file log yang telah mengalami pertumbuhan otomatis dalam jumlah besar. Saya menjelaskan contoh perbedaannya di postingan blog ini.
Setiap VLF memiliki nomor urut yang secara unik mengidentifikasinya dan digunakan di berbagai tempat, yang akan saya jelaskan di bawah dan di posting mendatang. Anda akan mengira nomor urut akan dimulai dari 1 untuk database baru, tetapi bukan itu masalahnya.
Pada contoh SQL Server 2019, saya membuat database baru, tanpa menentukan ukuran file apa pun, lalu memeriksa VLF menggunakan kode di bawah ini:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Perhatikan sys.dm_db_log_info DMV telah ditambahkan di SQL Server 2016 SP2. Sebelum itu (dan hari ini, karena masih ada), Anda dapat menggunakan DBCC LOGINFO yang tidak berdokumen perintah, tetapi Anda tidak dapat memberikannya daftar pilih—cukup lakukan DBCC LOGINFO(N'NewDB'); dan nomor urut VLF ada di FSeqNo kolom kumpulan hasil.
Bagaimanapun, hasil dari query sys.dm_db_log_info adalah:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Perhatikan VLF pertama dimulai pada offset 8.192 byte ke dalam file log. Ini karena semua file database, termasuk log transaksi, memiliki halaman header file yang menggunakan 8 KB pertama dan menyimpan berbagai metadata tentang file tersebut.
Jadi mengapa SQL Server memilih 37 dan bukan 1 untuk nomor urut VLF pertama? Ia menemukan nomor urut VLF tertinggi dalam model database dan kemudian, untuk database baru, VLF log transaksi pertama menggunakan angka itu ditambah 1 untuk nomor urutnya. Saya tidak tahu mengapa algoritme ini dipilih kembali dalam kabut waktu, tetapi sudah seperti itu sejak setidaknya SQL Server 7.0.
Untuk membuktikannya, saya menjalankan kode ini:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); Dan hasilnya adalah:
Max_VLF_SeqNo -------------------- 36
Jadi begitulah.
Masih banyak lagi yang bisa dibahas tentang VLF dan cara penggunaannya, tetapi untuk saat ini cukup mengetahui bahwa setiap VLF memiliki nomor urut, yang bertambah satu untuk setiap VLF.
Log Blok
Setiap VLF berisi header metadata kecil, dan sisa ruang diisi dengan blok log. Setiap blok log dimulai pada 512 byte dan akan bertambah dalam peningkatan 512-byte hingga ukuran maksimum 60KB, yang pada saat itu harus ditulis ke disk. Blok log mungkin ditulis ke disk sebelum mencapai ukuran maksimumnya jika salah satu dari hal berikut terjadi:
- Transaksi dilakukan, dan daya tahan tertunda tidak digunakan untuk transaksi ini, jadi blok log harus ditulis ke disk agar transaksi tahan lama
- Daya tahan tertunda sedang digunakan, dan tugas pengatur waktu 1 mdtk aktif di latar belakang "flush the current log block to disk"
- Halaman file data sedang ditulis ke disk oleh pos pemeriksaan atau penulis yang malas, dan ada satu atau lebih catatan log di blok log saat ini yang memengaruhi halaman yang akan ditulis (ingat logging write-ahead harus dijamin)
Anda dapat mempertimbangkan blok log sebagai sesuatu seperti halaman berukuran variabel yang menyimpan catatan log dalam urutan yang dibuat oleh transaksi yang mengubah database. Tidak ada blok log untuk setiap transaksi; catatan log untuk beberapa transaksi bersamaan dapat bercampur dalam blok log. Anda mungkin berpikir ini akan menimbulkan kesulitan untuk operasi yang perlu menemukan semua catatan log untuk satu transaksi, tetapi ternyata tidak, seperti yang akan saya jelaskan ketika saya membahas cara kerja rollback transaksi di posting selanjutnya.
Selain itu, ketika blok log ditulis ke disk, sangat mungkin blok tersebut berisi catatan log dari transaksi yang tidak dikomit. Ini juga bukan masalah karena cara kerja pemulihan kerusakan—yang merupakan beberapa postingan bagus di seri mendatang.
Log Nomor Urutan
Blok log memiliki ID dalam VLF, mulai dari 1 dan meningkat 1 untuk setiap blok log baru di VLF. Catatan log juga memiliki ID dalam blok log, mulai dari 1 dan meningkat 1 untuk setiap catatan log baru di blok log. Jadi, ketiga elemen dalam hierarki struktural log transaksi memiliki ID, dan mereka digabungkan menjadi pengenal tripartit yang disebut nomor urut log , lebih sering disebut sebagai LSN .
LSN didefinisikan sebagai <VLF sequence number>:<log block ID>:<log record ID> (4 byte:4 byte:2 byte) dan secara unik mengidentifikasi satu catatan log. Ini adalah pengidentifikasi yang terus meningkat, karena nomor urut VLF meningkat selamanya.
Pekerjaan Dasar Selesai!
Meskipun VLF penting untuk diketahui, menurut saya LSN adalah konsep yang paling penting untuk dipahami seputar implementasi logging SQL Server karena LSN adalah landasan di mana transaksi rollback dan pemulihan crash dibangun, dan LSN akan muncul lagi dan lagi sebagai Saya maju melalui seri. Di postingan berikutnya, saya akan membahas pemotongan log dan sifat melingkar dari log transaksi, yang semuanya berkaitan dengan VLF dan bagaimana mereka digunakan kembali.