Dari atas kepala saya, saya punya solusi 50% untuk Anda.
Masalahnya
SSIS sangat peduli tentang meta data sehingga variasi di dalamnya cenderung menghasilkan pengecualian. DTS jauh lebih pemaaf dalam hal ini. Kebutuhan yang kuat untuk meta data yang konsisten membuat penggunaan Flat File Source menjadi merepotkan.
Solusi berbasis kueri
Jika masalahnya adalah komponennya, mari kita tidak menggunakannya. Yang saya sukai dari pendekatan ini adalah bahwa secara konseptual, ini sama dengan menanyakan tabel-urutan kolom tidak menjadi masalah dan keberadaan kolom tambahan tidak penting.
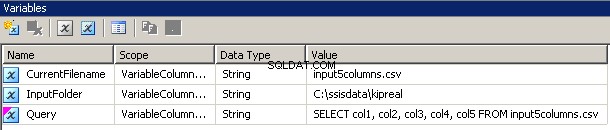
Variabel
Saya membuat 3 variabel, semua tipe string:CurrentFileName, InputFolder dan Query.
- InputFolder disambungkan ke folder sumber. Dalam contoh saya, ini adalah
C:\ssisdata\Kipreal - CurrentFileName adalah nama file. Selama waktu desain, itu adalah
input5columns.csvtapi itu akan berubah saat run time. - Kueri adalah ekspresi
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Manajer koneksi
Siapkan koneksi ke file input menggunakan driver JET OLEDB. Setelah membuatnya seperti yang dijelaskan dalam artikel tertaut, saya mengganti namanya menjadi FileOLEDB dan mengatur ekspresi pada ConnectionManager dari "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Alur Kontrol
Alur Kontrol saya terlihat seperti tugas aliran Data yang disarangkan di enumerator file Foreach
Foreach File Enumerator
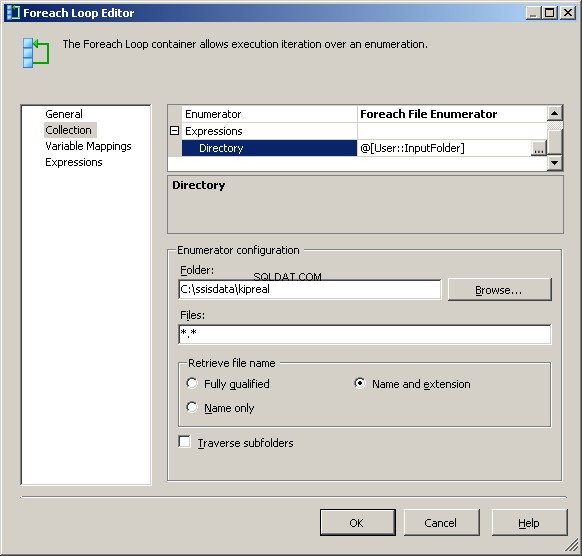
Enumerator File Foreach saya dikonfigurasi untuk beroperasi pada file. Saya meletakkan ekspresi pada Direktori untuk @[User::InputFolder] Perhatikan bahwa pada titik ini, jika nilai folder itu perlu diubah, itu akan diperbarui dengan benar di Manajer Koneksi dan enumerator file. Di "Ambil nama file", alih-alih default "Sepenuhnya Memenuhi Syarat", pilih "Nama dan Ekstensi"
Di tab Pemetaan Variabel, tetapkan nilai ke @[User::CurrentFileName] kami variabel
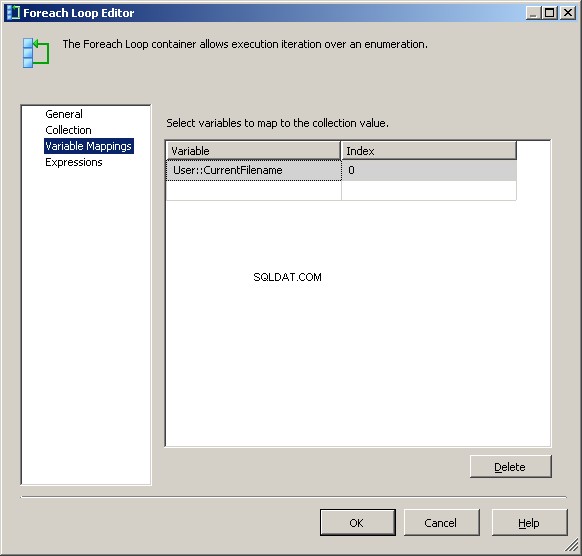
Pada titik ini, setiap iterasi dari loop akan mengubah nilai @[User::Query untuk mencerminkan nama file saat ini.
Alur Data
Ini sebenarnya bagian yang paling mudah. Gunakan sumber OLE DB dan kirimkan seperti yang ditunjukkan.
Gunakan manajer koneksi FileOLEDB dan ubah mode Akses Data ke "Perintah SQL dari variabel." Gunakan @[User::Query] variabel di sana, klik OK dan Anda siap bekerja. 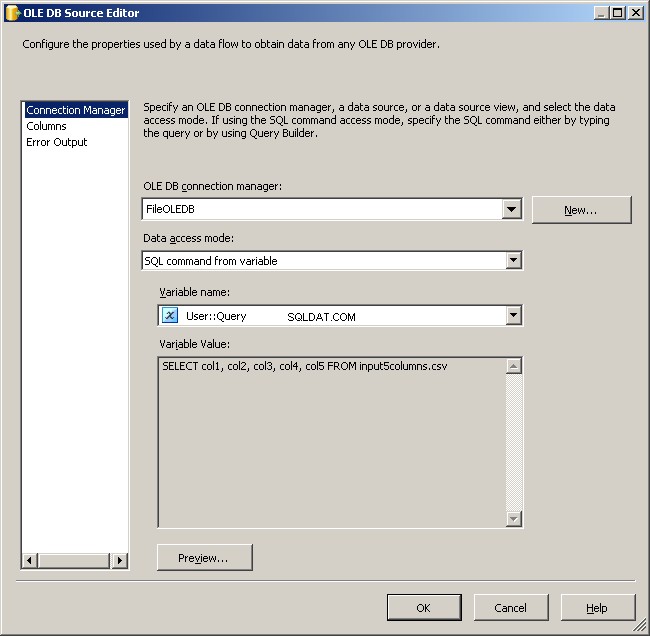
Contoh data
Saya membuat dua contoh file input5columns.csv dan input7columns.csv Semua kolom dari 5 ada di 7 tetapi 7 memilikinya dalam urutan yang berbeda (col2 adalah posisi ordinal 2 dan 6). Saya meniadakan semua nilai di 7 agar mudah terlihat file mana yang sedang dioperasikan.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
dan
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
Menjalankan paket menghasilkan dua tangkapan layar ini
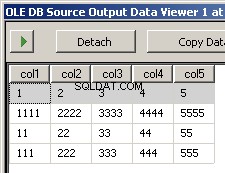
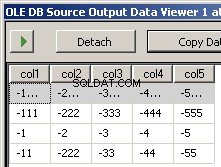
Apa yang hilang
Saya tidak tahu cara untuk memberi tahu pendekatan berbasis kueri bahwa tidak apa-apa jika kolom tidak ada. Jika ada kunci unik, saya kira Anda dapat menentukan kueri Anda agar hanya memiliki kolom yang harus berada di sana dan kemudian melakukan pencarian terhadap file untuk mencoba dan mendapatkan kolom yang seharusnya untuk berada di sana dan tidak gagal dalam pencarian jika kolom tidak ada. Cukup kikuk sekalipun.



