Saya bisa memberi Anda satu jawaban dan satu tebakan:
Pertama saya menggunakan variabel tabel yang dideklarasikan untuk mengejek skenario Anda:
DECLARE @tbl TABLE(s NVARCHAR(MAX));
INSERT INTO @tbl VALUES
(N'<root>
<SomeElement>This is first text of element1
<InnerElement>This is text of inner element1</InnerElement>
This is second text of element1
</SomeElement>
<SomeElement>This is first text of element2
<InnerElement>This is text of inner element2</InnerElement>
This is second text of element2
</SomeElement>
</root>')
,(N'<root>
<SomeElement>This is first text of elementA
<InnerElement>This is text of inner elementA</InnerElement>
This is second text of elementA
</SomeElement>
<SomeElement>This is first text of elementB
<InnerElement>This is text of inner elementB</InnerElement>
This is second text of elementB
</SomeElement>
</root>');
--Kueri ini akan membaca XML dengan membuang sub-pilihan . Anda dapat menggunakan CTE sebagai gantinya, tapi ini seharusnya hanya gula sintaksis...
SELECT se.value(N'(.)[1]','nvarchar(max)') SomeElementsContent
,se.value(N'(InnerElement)[1]','nvarchar(max)') InnerElementsContent
,se.value(N'(./text())[1]','nvarchar(max)') ElementsFirstText
,se.value(N'(./text())[2]','nvarchar(max)') ElementsSecondText
FROM (SELECT CAST(s AS XML) FROM @tbl) AS tbl(TheXml)
CROSS APPLY TheXml.nodes(N'/root/SomeElement') AS A(se);
--Bagian kedua menggunakan tabel untuk menulis dalam XML yang diketik dan membaca dari sana:
DECLARE @tbl2 TABLE(x XML)
INSERT INTO @tbl2
SELECT CAST(s AS XML) FROM @tbl;
SELECT se.value(N'(.)[1]','nvarchar(max)') SomeElementsContent
,se.value(N'(InnerElement)[1]','nvarchar(max)') InnerElementsContent
,se.value(N'(./text())[1]','nvarchar(max)') ElementsFirstText
,se.value(N'(./text())[2]','nvarchar(max)') ElementsSecondText
FROM @tbl2 t2
CROSS APPLY t2.x.nodes(N'/root/SomeElement') AS A(se);
Mengapa /text() lebih cepat daripada tanpa /text() ?
Jika Anda melihat contoh saya, konten elemen adalah semuanya dari tag pembuka hingga tag penutup . text() dari suatu elemen adalah teks mengambang antara tag ini. Anda dapat melihat ini pada hasil pilih di atas. text() adalah salah satu bagian yang disimpan secara terpisah dalam struktur pohon sebenarnya (baca bagian selanjutnya). Untuk mengambilnya, adalah tindakan satu langkah . Jika tidak, struktur kompleks harus dianalisis untuk menemukan segala sesuatu antara tag pembuka dan tag penutup yang sesuai - bahkan jika tidak ada yang lain selain text() .
Mengapa saya harus menyimpan XML dalam jenis yang sesuai?
XML bukan hanya teks dengan beberapa karakter tambahan yang konyol! Ini adalah dokumen dengan struktur yang kompleks. XML tidak disimpan sebagai teks yang Anda lihat . XML disimpan dalam struktur pohon. Setiap kali Anda melemparkan string, yang mewakili XML, menjadi XML nyata, pekerjaan yang sangat mahal ini harus dilakukan. Ketika XML disajikan kepada Anda (atau keluaran lainnya) string yang mewakili (kembali) dibangun dari awal.
Mengapa pendekatan pra-cetak lebih cepat
Ini adalah tebakan...
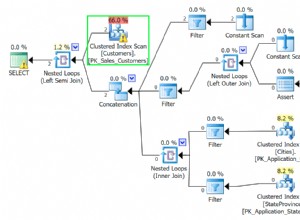
Dalam contoh saya, kedua pendekatan cukup sama dan mengarah ke (hampir) rencana eksekusi yang sama.
SQL Server tidak akan bekerja seperti yang Anda harapkan. Ini bukan sistem prosedural di mana Anda menyatakan melakukan ini, daripada melakukan ini dan setelah melakukan ini! . Anda memberi tahu mesin apa yang Anda inginkan, dan mesin memutuskan bagaimana melakukan yang terbaik. Dan mesinnya cukup bagus dengan ini!
Sebelum eksekusi dimulai, mesin mencoba memperkirakan biaya pendekatan. CONVERT (atau CAST ) adalah operasi yang agak murah. Bisa jadi, mesin memutuskan untuk mengerjakan daftar panggilan Anda dan melakukan pemeran untuk setiap kebutuhan berulang-ulang, karena menurutnya, ini lebih murah daripada pembuatan tabel turunan yang mahal...