Pengantar
Pada artikel ini, kita akan membahas bagaimana berbagai jenis indeks dalam tabel yang dioptimalkan memori SQL Server memengaruhi kinerja. Kami akan memeriksa contoh bagaimana jenis indeks yang berbeda dapat memengaruhi kinerja tabel yang dioptimalkan memori.
Untuk mempermudah diskusi topik, kita akan menggunakan contoh yang agak besar. Untuk tujuan kesederhanaan, contoh ini akan menampilkan replika yang berbeda dari satu tabel, yang dengannya kita akan menjalankan kueri yang berbeda. Replika ini akan menggunakan indeks yang berbeda, atau tanpa indeks sama sekali (kecuali, tentu saja, kunci utama – PK).
Perhatikan, bahwa tujuan sebenarnya dari artikel ini bukanlah untuk membandingkan kinerja antara tabel berbasis disk dan tabel yang dioptimalkan memori di SQL Server per se. Tujuannya adalah untuk memeriksa bagaimana indeks memengaruhi kinerja dalam tabel yang dioptimalkan memori. Namun, untuk mendapatkan gambaran lengkap tentang eksperimen, pengaturan waktu juga disediakan untuk kueri tabel berbasis disk yang sesuai dan percepatan dihitung menggunakan konfigurasi tabel berbasis disk yang paling optimal sebagai baseline.
Skenario
Data sampel untuk skenario kami didasarkan pada satu tabel yang didefinisikan sebagai berikut:
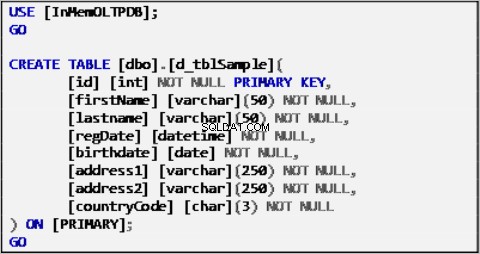
Daftar 1:Contoh Tabel Sumber Data.
Tabel di atas diisi dengan data sampel dan akan bertindak sebagai sumber data untuk tabel lainnya.
Jadi, berdasarkan tabel di atas, kami membuat 9 variasi tabel berikut dan mengisinya dengan data sampel yang sama:
- 3 tabel berbasis disk:
- d_tblSample1
- Indeks berkerumun pada kolom “id” – kunci utama (PK)
- d_tblSample2
- Indeks berkerumun pada kolom “id” (PK)
- Indeks non-cluster pada kolom “kode negara”
- d_tblSample3
- Indeks berkerumun pada kolom “id” (PK)
- Indeks non-cluster pada kolom “regDate”
- Indeks yang tidak berkerumun di kolom “Kode negara”
- d_tblSample1
- 3 tabel dengan memori yang dioptimalkan (set 1:Indeks hash):
- m1_tblSample1
- Indeks hash non-cluster pada kolom “id” – kunci utama (PK)
- m1_tblSample2
- Indeks hash non-cluster pada kolom “id” (PK)
- Indeks hash pada kolom “Kode negara”
- m1_tblSample3
- Indeks hash non-cluster pada kolom “id” (PK)
- Indeks hash pada kolom “regDate”
- Indeks hash pada kolom “Kode negara”
- 3 tabel dengan memori yang dioptimalkan (set 2:Indeks Non-Clustered):
- m2_tblSample1
- Indeks non-cluster pada kolom “id” – kunci utama (PK)
- m2_tblSample2
- Indeks non-cluster pada kolom “id” (PK)
- Indeks non-cluster pada kolom “kode negara”
- m2_tblSample3
- Indeks non-cluster pada kolom “id” (PK)
- Indeks non-cluster pada kolom “regDate”
- Indeks non-cluster pada kolom “kode negara”
- m2_tblSample1
- m1_tblSample1
Dalam daftar di bawah ini, Anda dapat menemukan definisi untuk tabel di atas.
Logika skenarionya adalah kita melakukan operasi basis data yang berbeda terhadap variasi tabel yang sama (tetapi dengan indeks yang berbeda), dan mengamati bagaimana kinerja dipengaruhi dalam setiap kasus.
Definisi
Tabel Berbasis Disk
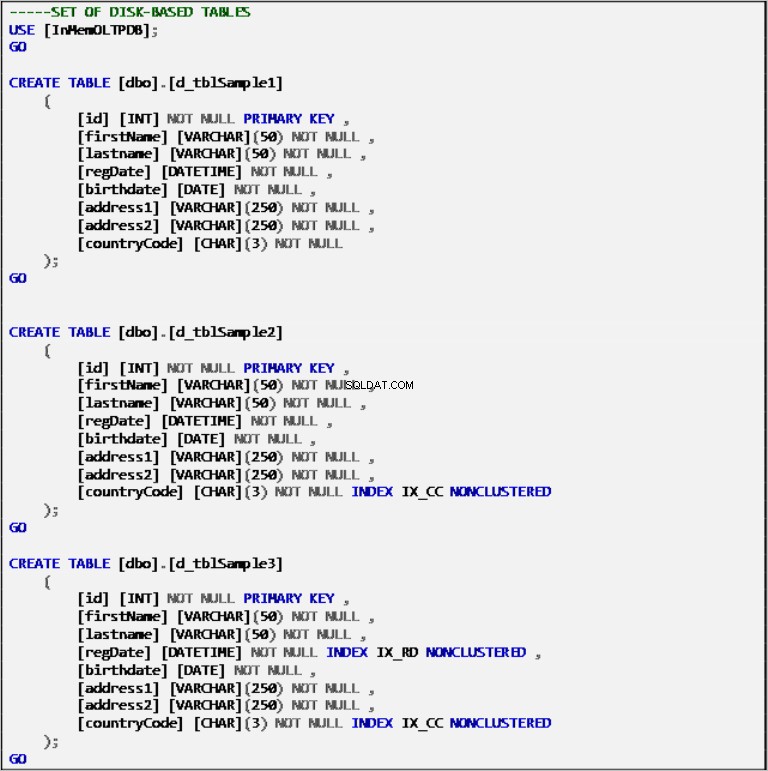
Daftar 2:Definisi Tabel Berbasis Disk.
Tabel dengan Memori yang Dioptimalkan (Set 1:Indeks Hash)

Daftar 3:Tabel dengan Memori yang Dioptimalkan – Set 1 (Indeks Hash).
Tabel dengan Memori yang Dioptimalkan (Set 2:Indeks Non-Clustered)

Daftar 4:Tabel dengan Memori yang Dioptimalkan – Set 2 (Indeks Non-Clustered).
Kemudian, kami mengisi semua tabel di atas dengan sampel data yang sama, yaitu total 5 juta record di setiap tabel.
Berikut adalah output dari perintah count untuk setiap set tabel:
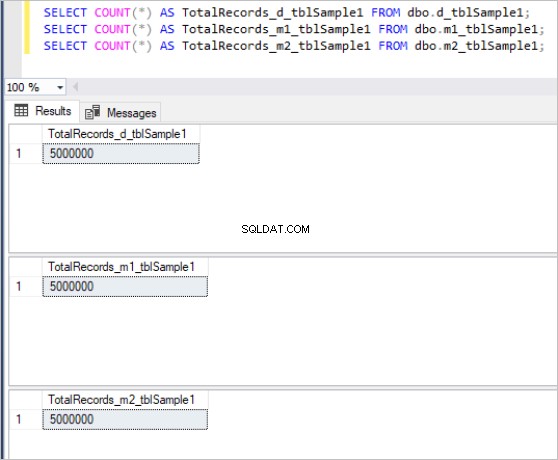
Gambar 1:Jumlah Total Catatan untuk Kumpulan Tabel Pertama.
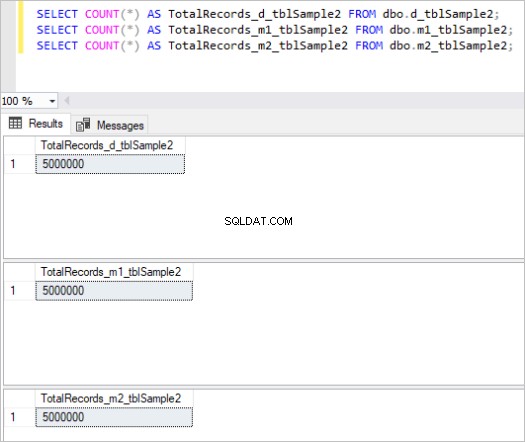
Gambar 2:Jumlah Total Catatan untuk Kumpulan Tabel Kedua.
Gambar 3:Jumlah Total Catatan untuk Kumpulan Tabel Ketiga.
Kueri dan Eksekusi Skenario
Sekarang, kita akan menjalankan serangkaian kueri terhadap tabel di atas dan melihat bagaimana kinerja setiap tabel.
Kueri ini melakukan operasi berikut:
- Kueri 1:Agregasi (GROUP BY)
- Kueri 2:Pencarian indeks pada predikat kesetaraan
- Kueri 3:Pencarian indeks tentang predikat kesetaraan dan ketidaksetaraan
Rencananya adalah menjalankan kueri seperti di bawah ini:
Query 1 – Eksekusi terhadap tabel berikut:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (tidak ada indeks pada kolom target)
- m2_tblSample1 (tidak ada indeks pada kolom target)
Query 2 – Eksekusi terhadap tabel berikut:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (tidak ada indeks pada kolom target)
- m2_tblSample1 (tidak ada indeks pada kolom target)
Query 3 – Eksekusi terhadap tabel berikut:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (tidak ada indeks pada kolom target)
- m2_tblSample1 (tidak ada indeks pada kolom target)
Catatan :Meskipun definisi untuk d_tblSample1 tabel berbasis disk termasuk dalam definisi tabel di atas, tidak digunakan dalam kueri yang disediakan dalam artikel ini. Alasannya adalah, dalam setiap skenario, konfigurasi yang paling optimal untuk tabel berbasis disk digunakan, karena kami ingin baseline kami secepat mungkin saat membandingkannya dengan kinerja tabel yang dioptimalkan memori. Untuk tujuan ini, d_tblSample1 tabel hanya disajikan untuk tujuan informasi.
Di bawah ini Anda dapat menemukan skrip T-SQL untuk tiga kueri beserta mekanisme pengukuran waktu eksekusi.

Daftar 5:Kueri 1 – Agregasi (dengan indeks).
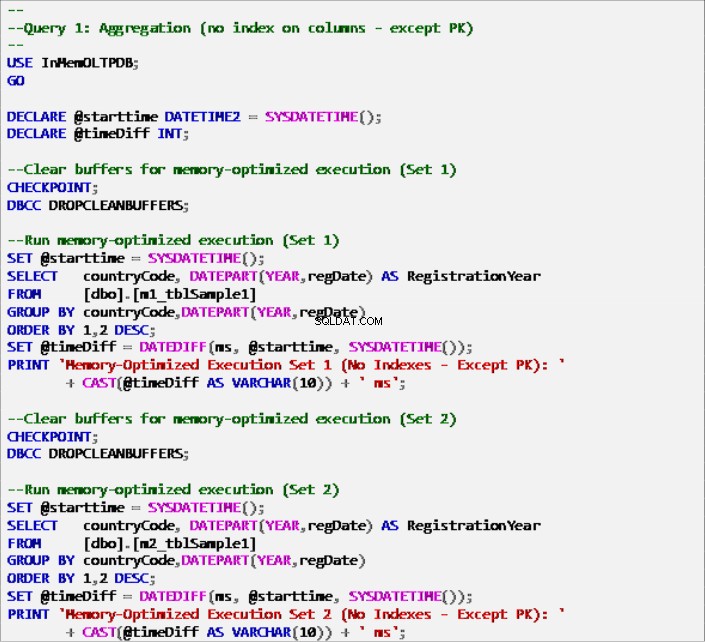
Daftar 6:Kueri 1 – Agregasi (tanpa indeks – Kecuali Kunci Utama).
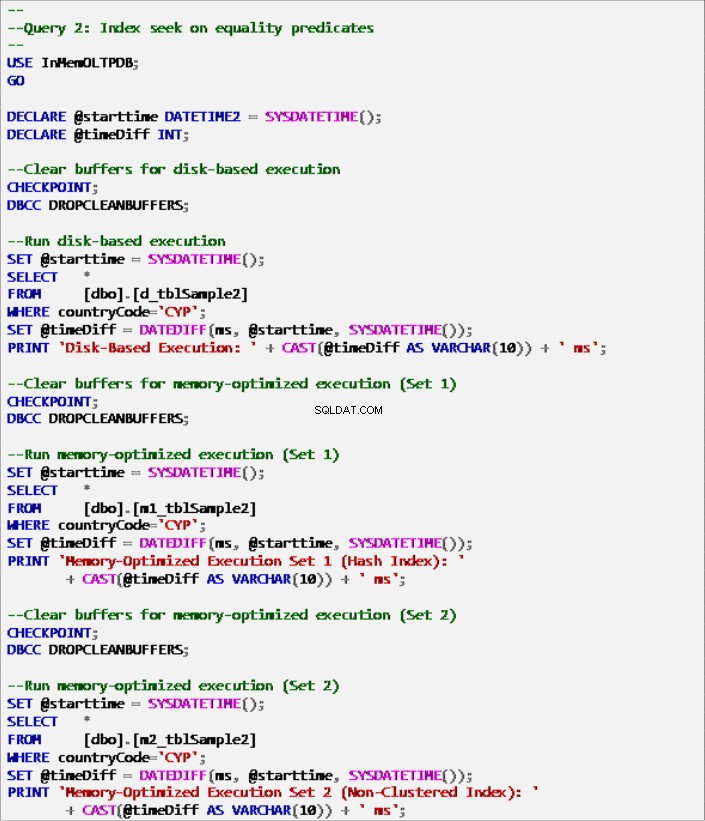
Daftar 7:Kueri 2 – Pencarian Indeks pada Predikat Kesetaraan (dengan indeks).

Daftar 8:Kueri 2 – Pencarian Indeks pada Predikat Kesetaraan (tanpa indeks – kecuali Kunci Utama).
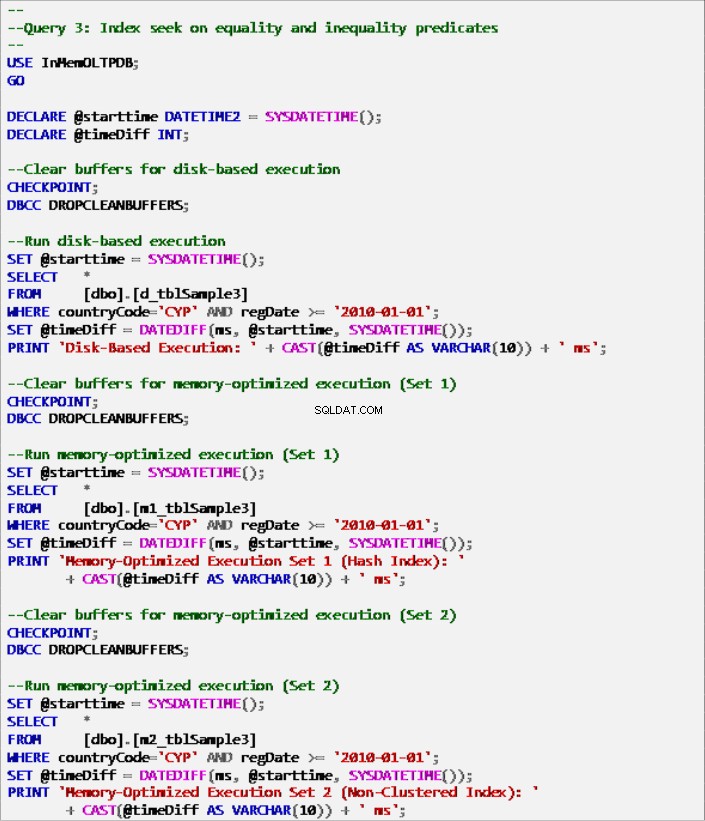
Daftar 9:Kueri 3 – Pencarian Indeks tentang Predikat Kesetaraan dan Ketimpangan (dengan indeks).

Daftar 10:Kueri 3 – Pencarian Indeks pada Predikat Kesetaraan dan Ketimpangan (tanpa indeks – Kecuali Kunci Utama).
Tangkapan layar di bawah ini menunjukkan output dari setiap eksekusi kueri:
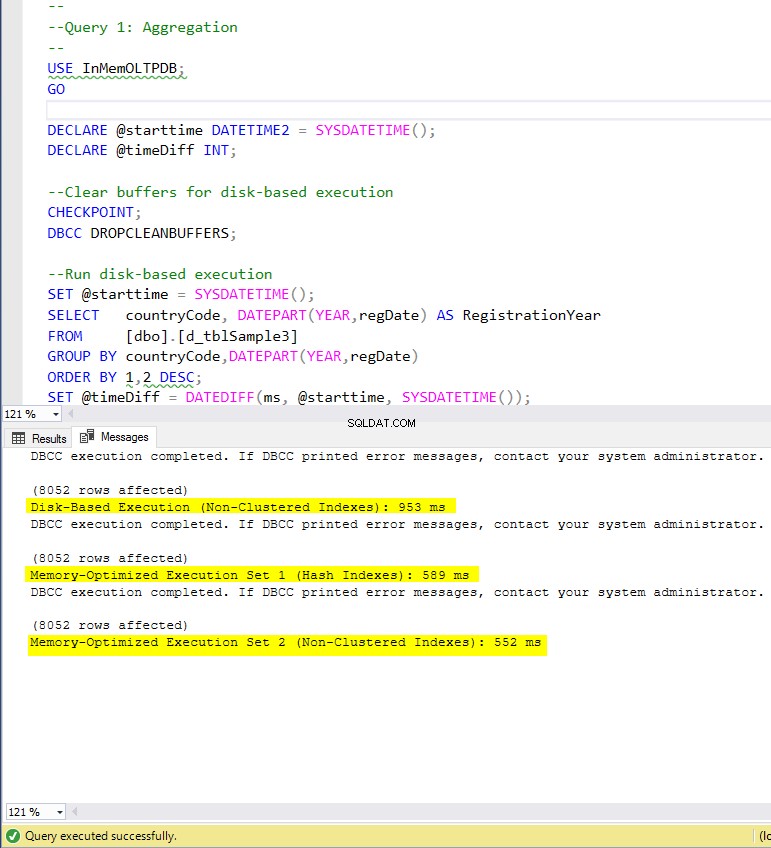
Gambar 4:Waktu Eksekusi Kueri 1 (dengan indeks).
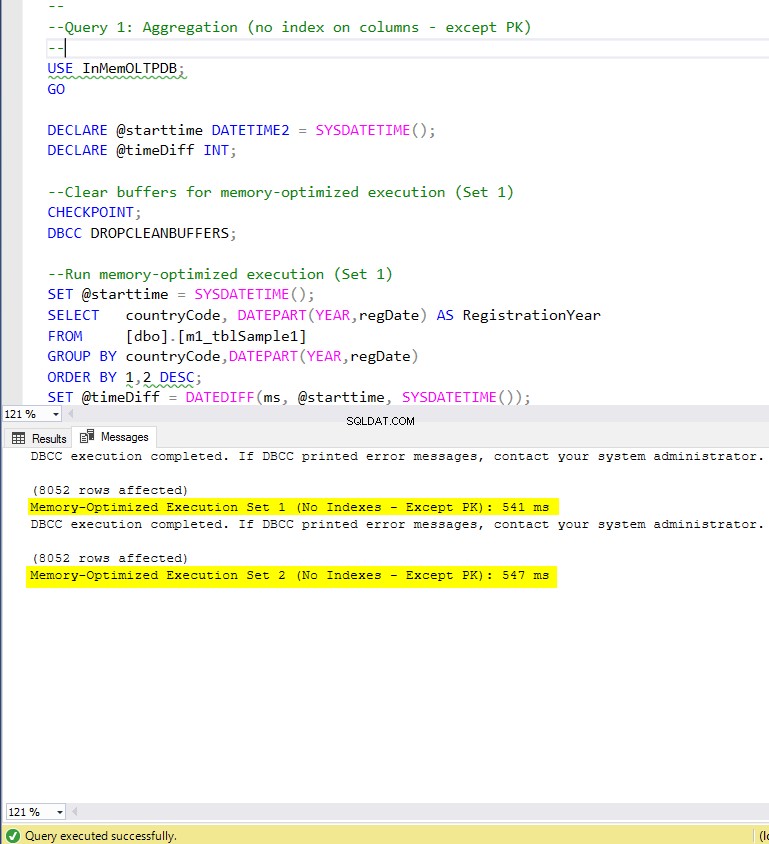
Gambar 5:Waktu Eksekusi Kueri 1 (tanpa indeks – kecuali PK).
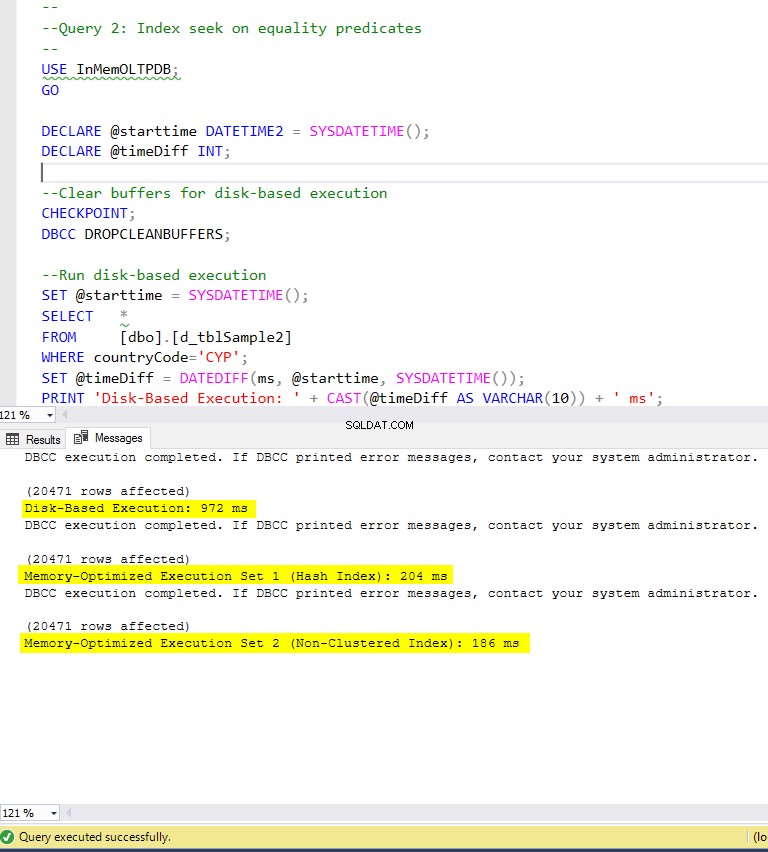
Gambar 6:Waktu Eksekusi Kueri 2 (dengan indeks).
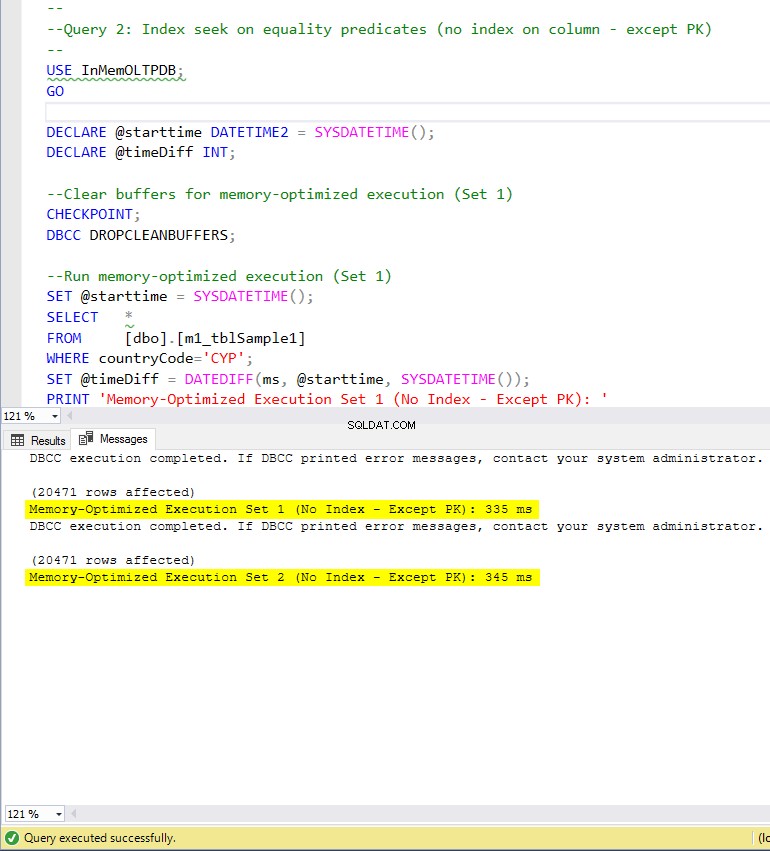
Gambar 7:Waktu Eksekusi Kueri 2 (tanpa indeks – kecuali PK).
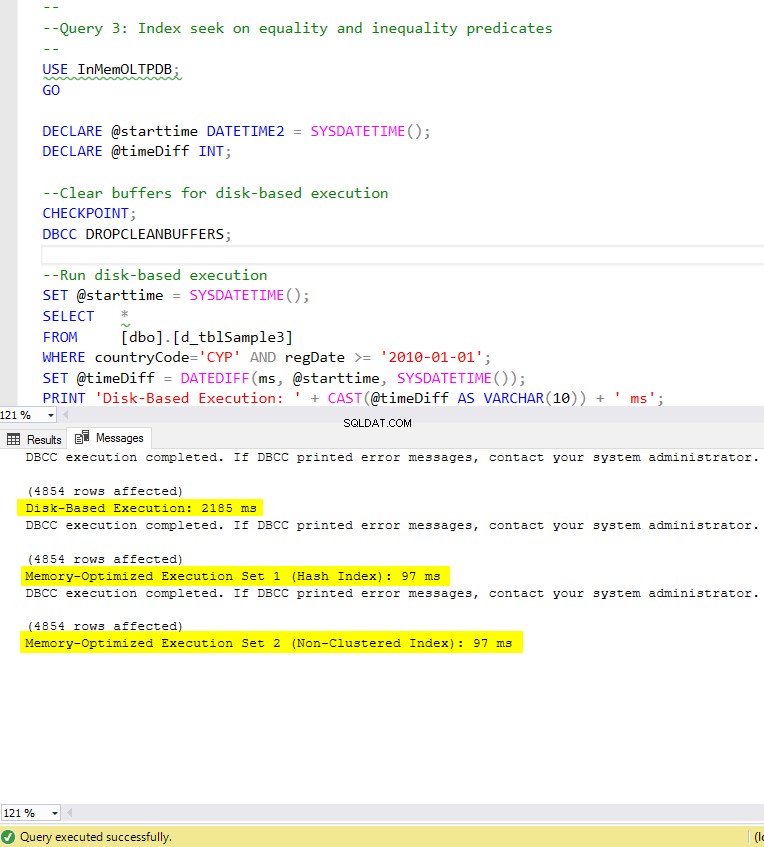
Gambar 8:Waktu Eksekusi Kueri 3 (dengan indeks).
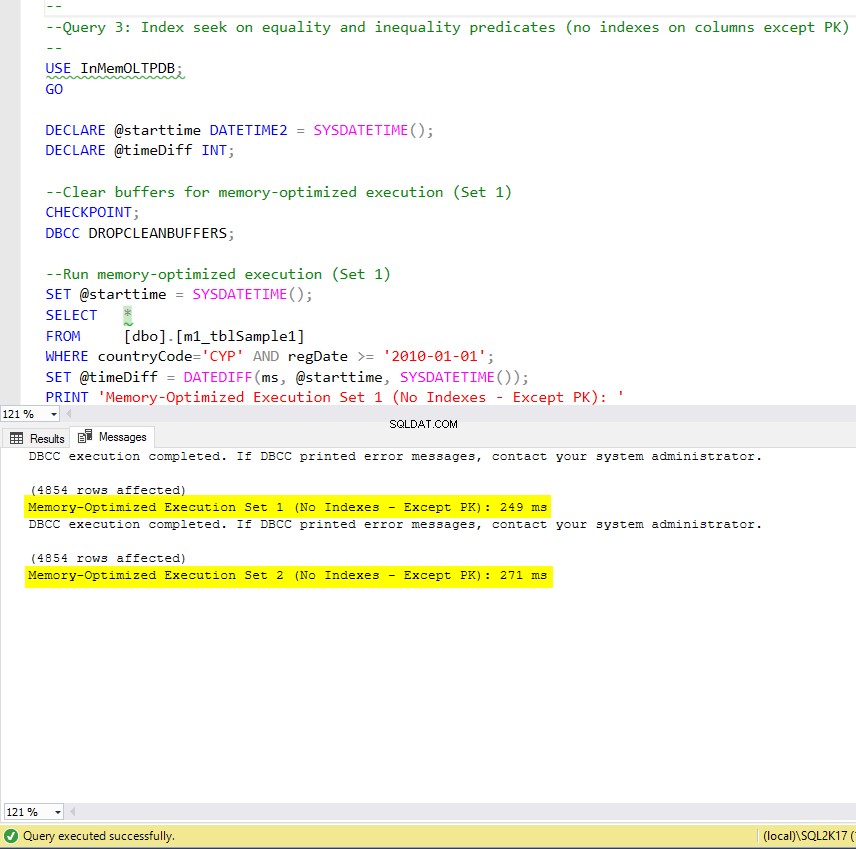
Gambar 9:Waktu Eksekusi Kueri 3 (tanpa indeks – kecuali PK).
Sekarang, mari kita rangkum hasil yang diperoleh di atas. Tabel berikut menampilkan waktu eksekusi terukur untuk semua kueri dan kombinasi tabel/indeks di atas.
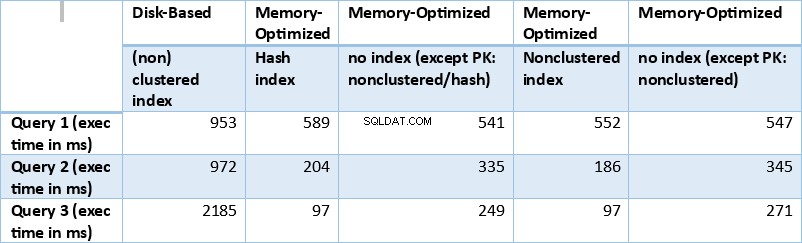
Tabel 1:Ringkasan Waktu Eksekusi (md) untuk semua Kueri.
Diskusi
Jika kita memeriksa hasil eksekusi yang dirangkum dalam tabel di atas, kita dapat mencapai kesimpulan tertentu. Mari kita plot setiap hasil kueri ke dalam grafik. Grafik di bawah mengilustrasikan waktu eksekusi, serta kecepatan tabel yang dioptimalkan memori di atas tabel berbasis disk.
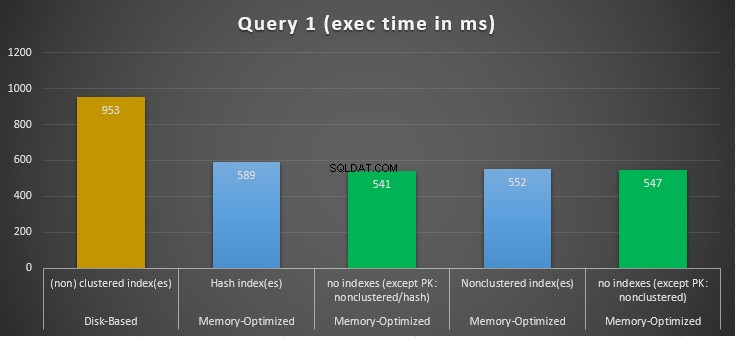
Gambar 10:Perbandingan Waktu Eksekusi Kueri 1.
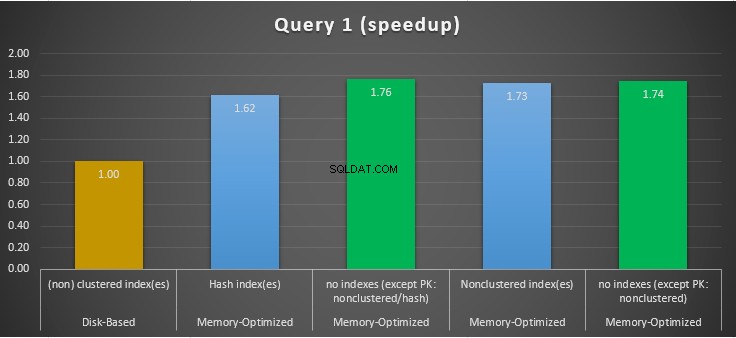
Gambar 11:Perbandingan Kecepatan Kueri 1.
Mengenai Kueri 1, yang merupakan agregasi GROUP BY, kita dapat melihat bahwa kedua versi (indeks vs tanpa indeks) tabel yang dioptimalkan memori, melakukan hampir sama dengan mempercepat tabel berbasis disk (diaktifkan dengan indeks) antara 1,62 dan 1,76 kali lebih cepat.
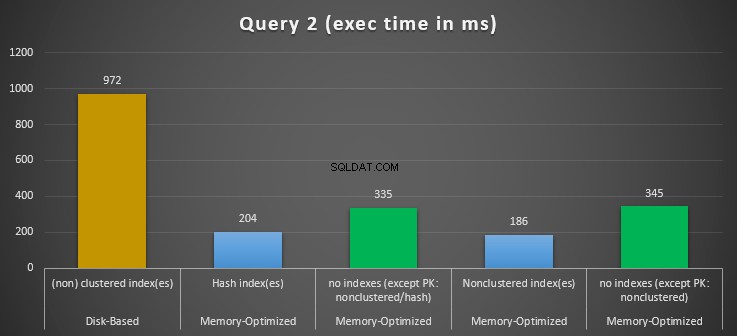
Gambar 12:Perbandingan Waktu Eksekusi Kueri 2.
Gambar 13:Perbandingan Kecepatan Kueri 2.
Mengenai Query 2, yang melibatkan pencarian indeks pada predikat kesetaraan, kita dapat melihat bahwa tabel yang dioptimalkan memori dengan indeks berkinerja jauh lebih baik daripada tabel yang dioptimalkan memori tanpa indeks. Selain itu, kami mengamati bahwa tabel yang dioptimalkan memori dengan indeks non-clustered di kolom yang digunakan sebagai predikat berkinerja lebih baik daripada tabel dengan indeks hash.
Jadi, untuk kueri 2, pemenangnya adalah tabel yang dioptimalkan memori dengan indeks non-cluster, yang memiliki kecepatan keseluruhan 5,23 kali lebih cepat daripada eksekusi berbasis disk.
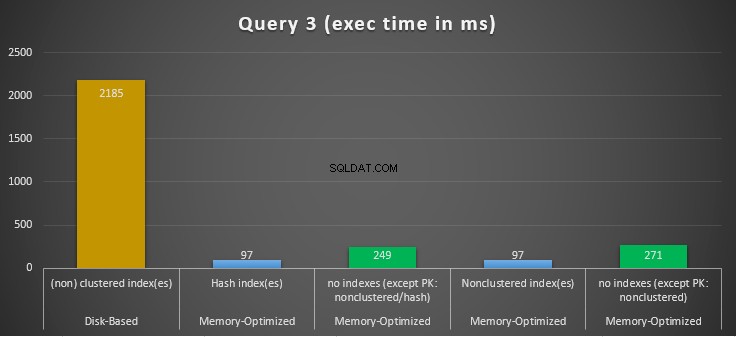
Gambar 14:Perbandingan Waktu Eksekusi Kueri 3.
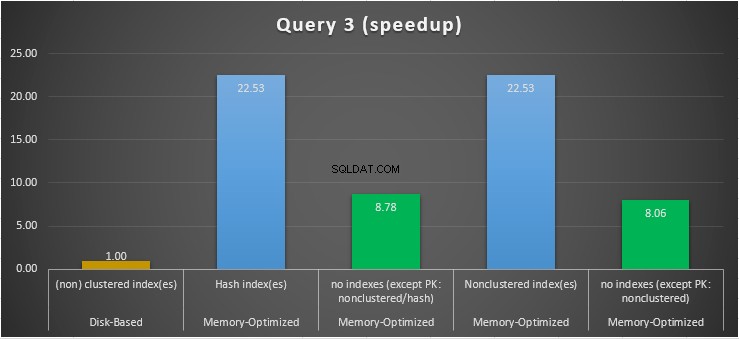
Gambar 15:Perbandingan Kecepatan Kueri 3.
Mengenai Kueri 3, yang melibatkan pencarian indeks pada predikat kesetaraan dan ketidaksetaraan yang digabungkan, kita dapat melihat bahwa tabel yang dioptimalkan memori dengan indeks, berkinerja jauh lebih baik daripada tabel yang dioptimalkan memori tanpa indeks. Selain itu, kami mengamati bahwa tabel yang dioptimalkan memori dengan indeks non-clustered di kolom yang digunakan sebagai predikat memiliki kinerja yang sama dengan tabel dengan indeks hash.
Untuk tujuan ini, kita dapat melihat bahwa kedua tabel yang dioptimalkan memori yang menggunakan indeks di kolom yang digunakan sebagai predikat, tampil lebih cepat daripada tabel tanpa indeks dan mencapai kecepatan 22,53 kali lebih cepat melalui eksekusi berbasis disk.
Kesimpulan
Pada artikel ini, kami memeriksa penggunaan indeks dalam tabel yang dioptimalkan memori di SQL Server. Kami menggunakan sebagai dasar untuk setiap kueri, konfigurasi tabel berbasis disk terbaik, dan kemudian kami membandingkan kinerja tiga kueri dengan tabel berbasis disk, dan 4 variasi tabel yang dioptimalkan memori. Dua dari empat tabel yang dioptimalkan memori menggunakan indeks (hash/non-clustered) dan dua lainnya tidak menggunakan indeks, kecuali yang digunakan untuk kunci utama.
Kesimpulan keseluruhannya adalah Anda selalu perlu memeriksa bagaimana indeks memengaruhi kinerja, tidak hanya untuk tabel yang dioptimalkan memori, tetapi juga untuk tabel berbasis disk, dan kapan pun Anda mengidentifikasi bahwa indeks tersebut meningkatkan kinerja, gunakanlah. Temuan contoh artikel ini, menunjukkan bahwa jika Anda menggunakan indeks yang tepat dalam tabel yang dioptimalkan memori, Anda bisa mencapai kinerja yang jauh lebih baik untuk kueri yang serupa dengan yang digunakan dalam artikel ini jika dibandingkan dengan hanya menggunakan tabel yang dioptimalkan memori tanpa indeks .
Referensi dan Bacaan Lebih Lanjut:
- Microsoft Docs:Tabel dengan Memori yang Dioptimalkan
- Microsoft Docs:Pedoman untuk Menggunakan Indeks pada Tabel dengan Memori yang Dioptimalkan
- Microsoft Docs:Indeks pada Tabel dengan Memori yang Dioptimalkan
Alat yang berguna:
dbForge Index Manager – add-in SSMS yang berguna untuk menganalisis status indeks SQL dan memperbaiki masalah dengan fragmentasi indeks.