SQL Server 2008 memperkenalkan kolom sparse sebagai metode untuk mengurangi penyimpanan nilai nol dan menyediakan skema yang lebih dapat diperluas. Trade-off adalah bahwa ada overhead tambahan saat Anda menyimpan dan mengambil nilai non-NULL. Saya tertarik untuk memahami biaya untuk menyimpan nilai non-NULL, setelah berbicara dengan pelanggan yang menggunakan tipe data ini dalam lingkungan staging. Mereka ingin mengoptimalkan kinerja penulisan, dan saya bertanya-tanya apakah penggunaan kolom sparse berpengaruh, karena metode mereka mengharuskan memasukkan baris ke dalam tabel, lalu memperbaruinya. Saya membuat contoh yang dibuat-buat untuk demo ini, dijelaskan di bawah, untuk menentukan apakah ini adalah metodologi yang baik untuk mereka gunakan.
Ulasan Internal
Sebagai tinjauan singkat, ingatlah bahwa ketika Anda membuat kolom untuk tabel yang memungkinkan nilai NULL, jika kolom tersebut adalah kolom dengan panjang tetap (misalnya INT), kolom tersebut akan selalu menggunakan seluruh lebar kolom pada halaman meskipun kolom tersebut BATAL. Jika itu adalah kolom dengan panjang variabel (misalnya VARCHAR), itu akan mengkonsumsi setidaknya dua byte dalam larik offset kolom ketika NULL, kecuali kolom tersebut setelah kolom yang terakhir diisi (lihat posting blog Kimberly Urutan kolom tidak masalah ... umumnya , tapi – TERGANTUNG). Kolom jarang tidak memerlukan ruang apa pun di halaman untuk nilai NULL, apakah itu kolom dengan panjang tetap atau panjang variabel, dan terlepas dari kolom lain apa yang diisi dalam tabel. Keuntungannya adalah ketika kolom sparse diisi, dibutuhkan penyimpanan empat (4) byte lebih banyak daripada kolom non-sparse. Misalnya:
| Jenis kolom | Persyaratan penyimpanan |
|---|---|
| kolom BESAR, tidak jarang, dengan tidak nilai | 8 byte |
| kolom BESAR, tidak jarang, dengan sebuah nilai | 8 byte |
| kolom BESAR, jarang, dengan tidak nilai | 0 byte |
| kolom BESAR, jarang, dengan sebuah nilai | 12 byte |
Oleh karena itu, penting untuk mengonfirmasi bahwa manfaat penyimpanan lebih besar daripada potensi kinerja pengambilan – yang mungkin dapat diabaikan berdasarkan keseimbangan baca dan tulis terhadap data. Perkiraan penghematan ruang untuk tipe data yang berbeda didokumentasikan dalam tautan Buku Online yang disediakan di atas.
Skenario Pengujian
Saya menyiapkan empat skenario berbeda untuk pengujian, yang dijelaskan di bawah, dan setiap tabel memiliki kolom ID (INT), kolom Name (VARCHAR(100)), dan kolom Type (INT), dan kemudian 997 kolom NULLABLE.
| ID Tes | Deskripsi Tabel | Operasi DML |
|---|---|---|
| 1 | 997 kolom tipe data INT, NULLABLE, tidak jarang | Menyisipkan satu baris pada satu waktu, mengisi ID, Nama, Jenis, dan sepuluh (10) kolom NULLABLE acak |
| 2 | 997 kolom tipe data INT, NULLABLE, sparse | Menyisipkan satu baris pada satu waktu, mengisi ID, Nama, Jenis, dan sepuluh (10) kolom NULLABLE acak |
| 3 | 997 kolom tipe data INT, NULLABLE, tidak jarang | Sisipkan satu baris pada satu waktu, isi ID, Nama, Ketik saja, lalu perbarui baris, tambahkan nilai untuk sepuluh (10) kolom NULLABLE acak |
| 4 | 997 kolom tipe data INT, NULLABLE, sparse | Sisipkan satu baris pada satu waktu, isi ID, Nama, Ketik saja, lalu perbarui baris, tambahkan nilai untuk sepuluh (10) kolom NULLABLE acak |
| 5 | 997 kolom tipe data VARCHAR, NULLABLE, tidak jarang | Menyisipkan satu baris pada satu waktu, mengisi ID, Nama, Jenis, dan sepuluh (10) kolom NULLABLE acak |
| 6 | 997 kolom tipe data VARCHAR, NULLABLE, sparse | Menyisipkan satu baris pada satu waktu, mengisi ID, Nama, Jenis, dan sepuluh (10) kolom NULLABLE acak |
| 7 | 997 kolom tipe data VARCHAR, NULLABLE, tidak jarang | Sisipkan satu baris pada satu waktu, isi ID, Nama, Ketik saja, lalu perbarui baris, tambahkan nilai untuk sepuluh (10) kolom NULLABLE acak |
| 8 | 997 kolom tipe data VARCHAR, NULLABLE, sparse | Sisipkan satu baris pada satu waktu, isi ID, Nama, Ketik saja, lalu perbarui baris, tambahkan nilai untuk sepuluh (10) kolom NULLABLE acak |
Setiap pengujian dijalankan dua kali dengan kumpulan data 10 juta baris. Skrip terlampir dapat digunakan untuk mereplikasi pengujian, dan langkah-langkahnya adalah sebagai berikut untuk setiap pengujian:
- Buat database baru dengan data dan file log ukuran sebelumnya
- Buat tabel yang sesuai
- Statistik tunggu snapshot dan statistik file
- Catat waktu mulainya
- Jalankan DML (satu sisipan, atau satu sisipan dan satu pembaruan) untuk 10 juta baris
- Perhatikan waktu berhenti
- Statistik tunggu snapshot dan statistik file dan tulis ke tabel logging di database terpisah di penyimpanan terpisah
- Snapshot dm_db_index_physical_stats
- Lepaskan database
Pengujian dilakukan pada Dell PowerEdge R720 dengan memori 64 GB dan 12 GB yang dialokasikan untuk instans SQL Server 2014 SP1 CU4. SSD Fusion-IO digunakan untuk penyimpanan data untuk file database.
Hasil
Hasil pengujian disajikan di bawah ini untuk setiap skenario pengujian.
Durasi
Dalam semua kasus, dibutuhkan lebih sedikit waktu (rata-rata 11,6 menit) untuk mengisi tabel saat kolom jarang digunakan, bahkan saat baris pertama kali dimasukkan, lalu diperbarui. Saat baris pertama kali dimasukkan, lalu diperbarui, pengujian membutuhkan waktu hampir dua kali lebih lama untuk dijalankan dibandingkan saat baris dimasukkan, karena modifikasi data yang dilakukan dua kali lebih banyak.
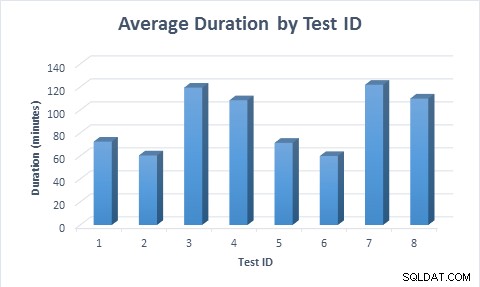 Durasi rata-rata untuk setiap skenario pengujian
Durasi rata-rata untuk setiap skenario pengujian
Statistik Tunggu
| ID Tes | Persentase Rata-rata | Rata-rata Tunggu (detik) |
|---|---|---|
| 1 | 16,47 | 0,0001 |
| 2 | 14.00 | 0,0001 |
| 3 | 16,65 | 0,0001 |
| 4 | 15.07 | 0,0001 |
| 5 | 12,80 | 0,0001 |
| 6 | 13,99 | 0,0001 |
| 7 | 14,85 | 0,0001 |
| 8 | 15.02 | 0,0001 |
Statistik menunggu konsisten untuk semua pengujian dan tidak ada kesimpulan yang dapat dibuat berdasarkan data ini. Perangkat kerasnya cukup memenuhi permintaan sumber daya di semua kasus pengujian.
Statistik File
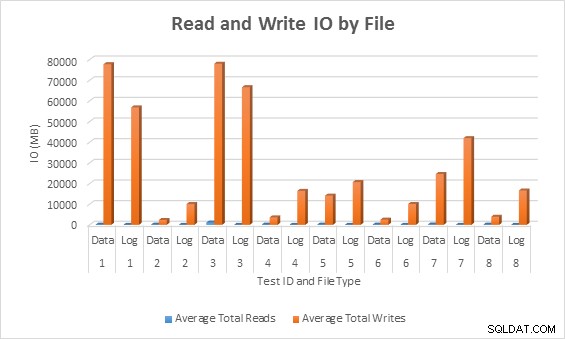 Rata-rata IO (baca dan tulis) per file database
Rata-rata IO (baca dan tulis) per file database
Dalam semua kasus, pengujian dengan kolom jarang menghasilkan lebih sedikit IO (terutama penulisan) dibandingkan dengan kolom tidak jarang.
Indeks Statistik Fisik
| Kasus uji | Jumlah baris | Total jumlah halaman (indeks berkerumun) | Total ruang (GB) | Ruang Rata-rata Digunakan untuk halaman daun dalam CI (%) | Ukuran Rekam Rata-rata (byte) |
|---|---|---|---|---|---|
| 1 | 10.000.000 | 10.037.312 | 76 | 51,70 | 4.184,49 |
| 2 | 10.000.000 | 301.429 | 2 | 98,51 | 237,50 |
| 3 | 10.000.000 | 10.037.312 | 76 | 51,70 | 4.184,50 |
| 4 | 10.000.000 | 460,960 | 3 | 64,41 | 237,50 |
| 5 | 10.000.000 | 1.823.083 | 13 | 90,31 | 1.326.08 |
| 6 | 10.000.000 | 324.162 | 2 | 98,40 | 255.28 |
| 7 | 10.000.000 | 3.161.224 | 24 | 52.09 | 1.326,39 |
| 8 | 10.000.000 | 503.592 | 3 | 63,33 | 255.28 |
Terdapat perbedaan yang signifikan dalam penggunaan ruang antara tabel non-jarang dan jarang. Ini paling menonjol ketika melihat kasus uji 1 dan 3, di mana tipe data panjang tetap digunakan (INT), dibandingkan dengan kasus uji 5 dan 7, di mana tipe data panjang variabel digunakan (VARCHAR(255)). Kolom integer mengkonsumsi ruang disk bahkan ketika NULL. Kolom panjang variabel menggunakan lebih sedikit ruang disk, karena hanya dua byte yang digunakan dalam larik offset untuk kolom NULL, dan tidak ada byte untuk kolom NULL yang berada setelah kolom terakhir yang diisi dalam baris.
Selanjutnya, proses penyisipan baris dan kemudian memperbaruinya menyebabkan fragmentasi untuk variabel panjang kolom uji (kasus 7), dibandingkan dengan hanya menyisipkan baris (kasus 5). Ukuran tabel hampir dua kali lipat saat penyisipan diikuti oleh pembaruan, karena pemisahan halaman yang terjadi saat memperbarui baris, yang membuat halaman setengah penuh (dibandingkan 90% penuh).
Ringkasan
Kesimpulannya, kami melihat pengurangan yang signifikan dalam ruang disk dan IO ketika kolom jarang digunakan, dan kinerjanya sedikit lebih baik daripada kolom non-jarang dalam pengujian modifikasi data sederhana kami (perhatikan bahwa kinerja pengambilan juga harus dipertimbangkan; mungkin subjek lain pos).
Kolom jarang memiliki skenario penggunaan yang sangat spesifik dan penting untuk memeriksa jumlah ruang disk yang disimpan, berdasarkan tipe data untuk kolom dan jumlah kolom yang biasanya akan diisi dalam tabel. Dalam contoh kami, kami memiliki 997 kolom yang jarang, dan kami hanya mengisi 10 di antaranya. Paling-paling, dalam kasus di mana tipe data yang digunakan adalah bilangan bulat, baris pada tingkat daun indeks berkerumun akan mengkonsumsi 188 byte (4 byte untuk ID, 100 byte maks untuk Nama, 4 byte untuk tipe, dan kemudian 80 byte untuk 10 kolom). Ketika 997 kolom tidak jarang, maka 4 byte dialokasikan untuk setiap kolom, bahkan ketika NULL, jadi setiap baris setidaknya 4.000 byte pada tingkat daun. Dalam skenario kami, kolom jarang benar-benar dapat diterima. Tetapi jika kita mengisi 500 atau lebih kolom sparse dengan nilai untuk kolom INT, maka penghematan ruang akan hilang, dan kinerja modifikasi mungkin tidak lagi lebih baik.
Bergantung pada tipe data untuk kolom Anda, dan jumlah kolom yang diharapkan untuk diisi dari total, Anda mungkin ingin melakukan pengujian serupa untuk memastikan bahwa, saat menggunakan kolom jarang, kinerja penyisipan dan penyimpanan sebanding atau lebih baik daripada saat menggunakan non -kolom jarang. Untuk kasus ketika tidak semua kolom diisi, kolom jarang pasti layak dipertimbangkan.