Ini adalah artikel pertama dari rangkaian artikel tentang In-Memory OLTP. Ini membantu Anda memahami cara kerja mesin Hekaton baru secara internal. Kami akan fokus pada detail tabel dan indeks yang dioptimalkan dalam memori. Ini adalah artikel tingkat pemula, yang berarti Anda tidak perlu menjadi ahli SQL Server, namun, Anda perlu memiliki pengetahuan dasar tentang mesin SQL Server tradisional.
Pengantar
Mesin OLTP Dalam Memori SQL Server 2014 (proyek Hekaton) dibuat dari nol untuk memanfaatkan terabyte memori yang tersedia dan sejumlah besar inti pemrosesan. OLTP Dalam Memori memungkinkan pengguna untuk bekerja dengan tabel dan indeks yang dioptimalkan memori, dan prosedur tersimpan yang dikompilasi secara asli. Anda dapat menggunakannya bersama dengan tabel dan indeks berbasis disk, dan prosedur tersimpan T-SQL, yang selalu disediakan SQL Server.
Internal dan kemampuan engine OLTP dalam Memori sangat berbeda dari engine relasional standar. Anda perlu merevisi hampir semua yang Anda ketahui tentang cara menangani beberapa proses bersamaan.
Mesin SQL Server dioptimalkan untuk penyimpanan berbasis disk. Ini membaca halaman data 8KB ke dalam memori untuk diproses dan menulis halaman data 8KB kembali ke disk setelah modifikasi. Tentu saja, SQL Server terutama memperbaiki perubahan pada disk di log transaksi. Membaca halaman data 8 KB dari disk dan menulisnya kembali, dapat menghasilkan banyak I/O dan menyebabkan biaya latensi yang lebih tinggi. Bahkan ketika data dalam cache buffer, SQL server dirancang untuk mengasumsikan bahwa itu tidak, yang mengarah pada penggunaan CPU yang tidak efisien.
Mempertimbangkan keterbatasan struktur penyimpanan berbasis disk tradisional, tim SQL Server mulai membangun mesin database yang dioptimalkan untuk memori utama yang besar dan CPU multi-inti. Tim menetapkan tujuan berikut:
- Dioptimalkan untuk data yang disimpan sepenuhnya di memori tetapi juga tahan lama saat SQL Server dimulai ulang
- Sepenuhnya terintegrasi ke dalam mesin SQL Server yang ada
- Kinerja sangat tinggi untuk operasi OLTP
- Dirancang untuk CPU modern
SQL Server In-Memory OLTP memenuhi semua tujuan ini.
Tentang OLTP Dalam Memori
SQL Server 2014 In-Memory OLTP menyediakan sejumlah teknologi untuk bekerja dengan tabel yang dioptimalkan memori, bersama dengan tabel berbasis disk. Misalnya, ini memungkinkan Anda untuk mengakses data dalam memori menggunakan antarmuka standar seperti T-SQL dan SSMS. Ilustrasi berikut menunjukkan tabel dan indeks yang dioptimalkan memori, sebagai bagian dari In-Memory OLTP (di sebelah kiri) dan tabel berbasis disk (di sebelah kiri) yang memerlukan untuk membaca dan menulis halaman data 8KB. OLTP Dalam Memori juga mendukung prosedur tersimpan yang dikompilasi secara asli dan menyediakan kompiler OLTP dalam memori yang baru.
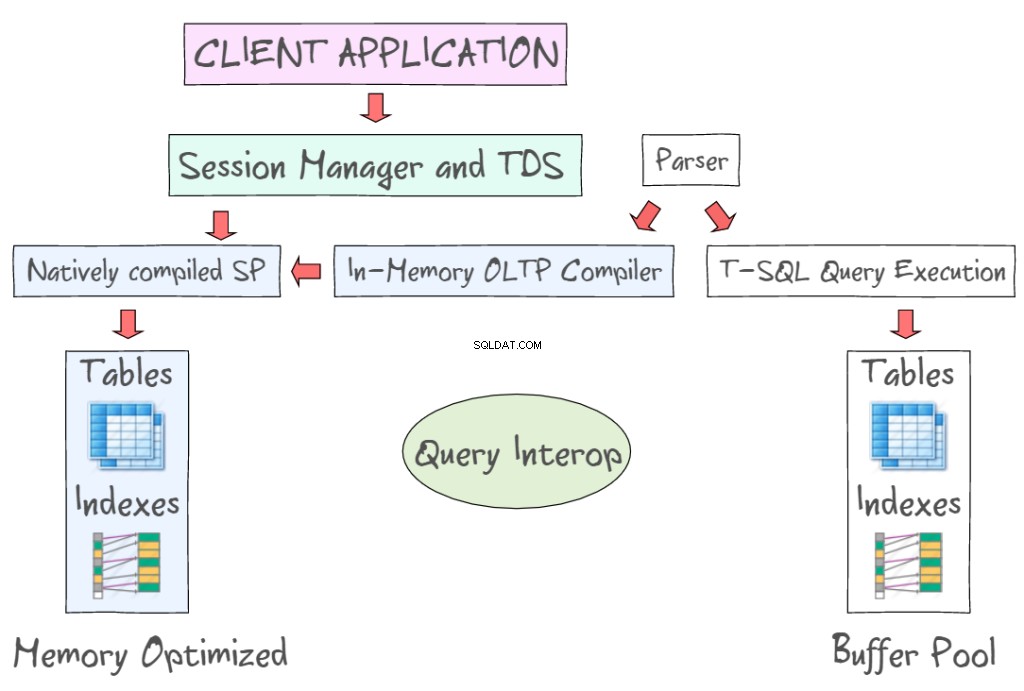
Query Interop memungkinkan interpretasi T-SQL untuk merujuk tabel yang dioptimalkan memori. Jika sebuah transaksi mereferensikan tabel yang dioptimalkan memori dan berbasis disk, itu dapat disebut sebagai transaksi lintas kontainer s. Aplikasi klien menggunakan Tabular Data Stream – protokol lapisan aplikasi yang digunakan untuk mentransfer data antara server database dan klien. Ini awalnya dirancang dan dikembangkan oleh Sybase Inc. untuk mesin database relasional Sybase SQL Server mereka pada tahun 1984, dan kemudian oleh Microsoft di Microsoft SQL Server.
Tabel dengan memori yang dioptimalkan
Saat mengakses tabel berbasis disk, data yang diperlukan mungkin sudah ada di memori meskipun mungkin tidak. Jika data tidak ada dalam memori, SQL Server perlu membacanya dari disk. Perbedaan paling mendasar saat menggunakan tabel dengan memori yang dioptimalkan adalah seluruh tabel dan indeksnya disimpan dalam memori sepanjang waktu . Operasi data serentak tidak memerlukan penguncian atau penguncian.
Sementara pengguna memodifikasi data dalam memori, SQL Server melakukan beberapa I/O disk untuk tabel apa pun yang perlu tahan lama, jika tidak, di mana kita memerlukan tabel untuk menyimpan data dalam memori pada saat server crash atau restart.
Struktur penyimpanan berbasis baris
Perbedaan signifikan lainnya adalah struktur penyimpanan yang mendasarinya. Tabel berbasis disk dioptimalkan untuk block-addressable penyimpanan disk, sedangkan tabel yang dioptimalkan dalam memori dioptimalkan untuk byte-addressable penyimpanan memori.
SQL Server menyimpan baris data di halaman data 8K, dengan alokasi ruang dari luasan untuk tabel berbasis disk. Halaman data adalah unit dasar penyimpanan disk dan memori. Saat membaca dan menulis data dari disk, SQL Server hanya membaca dan menulis halaman data yang relevan. Halaman data hanya akan berisi data dari satu tabel atau indeks. Proses aplikasi memodifikasi baris pada halaman data yang berbeda sesuai kebutuhan. Kemudian, selama operasi CHECKPOINT, SQL Server pertama-tama memperbaiki catatan log ke disk dan kemudian menulis semua halaman kotor ke disk. Operasi ini sering menyebabkan banyak I/O fisik acak.
Untuk tabel yang dioptimalkan memori, tidak ada halaman data, serta tidak ada perluasan. Hanya ada baris data yang ditulis ke memori secara berurutan, sesuai urutan transaksi terjadi. Setiap baris berisi penunjuk indeks ke baris berikutnya. Semua I/O adalah pemindaian dalam memori dari struktur ini. Tidak ada gagasan tentang baris data yang ditulis ke lokasi tertentu yang dimiliki oleh objek tertentu. Meskipun, Anda tidak harus berpikir bahwa tabel yang dioptimalkan memori disimpan sebagai kumpulan baris data yang tidak terorganisir (mirip dengan tumpukan berbasis disk). Setiap pernyataan CREATE TABLE untuk tabel dengan memori yang dioptimalkan membuat setidaknya satu indeks yang digunakan SQL Server untuk menautkan semua baris data dalam tabel itu.
Setiap baris data tunggal terdiri dari header baris dan payload yang merupakan data kolom yang sebenarnya. Header menyimpan informasi tentang pernyataan yang membuat baris, pointer untuk setiap indeks pada tabel target, dan nilai timestamp. Timestamp menunjukkan waktu transaksi dimasukkan dan dihapus satu baris. Catatan SQL Server diperbarui dengan memasukkan versi baris baru dan menandai versi lama sebagai dihapus. Beberapa versi dari baris yang sama dapat ada pada waktu tertentu. Ini memungkinkan akses simultan ke baris yang sama selama modifikasi data. SQL Server menampilkan versi baris yang relevan untuk setiap transaksi sesuai dengan waktu transaksi dimulai relatif terhadap stempel waktu versi baris. Ini adalah inti dari kontrol konkurensi multi-versi yang baru mekanisme untuk tabel dalam memori.
Omong-omong, Oracle memiliki sistem kontrol multi-versi yang sangat baik. Pada dasarnya, ini berfungsi sebagai berikut:
- Pengguna A memulai transaksi dan memperbarui 1000 baris dengan beberapa nilai pada waktu T1.
- Pengguna B membaca 1000 baris yang sama pada waktu T2.
- Pengguna A memperbarui baris 565 dengan nilai Y (nilai aslinya adalah X).
- Pengguna B mencapai baris 565 dan menemukan bahwa transaksi sedang berjalan sejak Waktu T1.
- Basis data mengembalikan catatan yang tidak dimodifikasi dari log. Nilai yang dikembalikan adalah nilai yang dilakukan pada waktu kurang dari atau sama dengan T2.
- Jika record tidak dapat diambil dari redo log, berarti database tidak diatur dengan benar. Lebih banyak ruang perlu dialokasikan untuk log.
- Hasil yang dikembalikan selalu sama sehubungan dengan waktu mulai transaksi. Jadi dalam transaksi, konsistensi baca tercapai.
Tabel yang dikompilasi secara native
Perbedaan utama terakhir adalah bahwa tabel yang dioptimalkan dalam memori dikompilasi secara native . Saat pengguna membuat tabel atau indeks yang dioptimalkan memori, SQL Server menyimpan struktur setiap tabel (bersama dengan semua indeks) dalam metadata. Kemudian, SQL Server menggunakan metadata itu untuk dikompilasi ke dalam DDL satu set rutinitas bahasa asli untuk mengakses tabel. DDL tersebut diasosiasikan dengan database tetapi sebenarnya bukan bagian darinya.
Dengan kata lain, SQL Server menyimpan di memori tidak hanya tabel dan indeks tetapi juga DDL untuk mengakses dan memodifikasi struktur ini. Setelah tabel diubah, SQL Server perlu membuat ulang semua DDL untuk operasi tabel. Itulah mengapa Anda tidak dapat mengubah tabel setelah dibuat. Operasi ini tidak terlihat oleh pengguna.
Prosedur tersimpan yang dikompilasi secara native
Performa terbaik dicapai saat menggunakan prosedur tersimpan yang dikompilasi secara native untuk mengakses tabel yang dikompilasi secara native. Prosedur tersebut berisi instruksi prosesor dan dapat dieksekusi langsung oleh CPU tanpa kompilasi lebih lanjut. Namun, ada beberapa batasan pada konstruksi T-SQL untuk prosedur tersimpan yang dikompilasi secara asli (dibandingkan dengan kode yang ditafsirkan secara tradisional). Poin penting lainnya adalah bahwa prosedur tersimpan yang dikompilasi secara asli hanya dapat mengakses tabel yang dioptimalkan memori.
Tidak ada kunci
OLTP Dalam Memori adalah sistem bebas kunci. Ini dimungkinkan karena SQL Server tidak pernah mengubah baris yang ada. Operasi UPDATE membuat versi baru dan menandai versi sebelumnya sebagai dihapus. Kemudian ia menyisipkan versi baris baru dengan data baru di dalamnya.
Indeks
Seperti yang mungkin sudah Anda duga, indeks sangat berbeda dari yang tradisional. Tabel yang dioptimalkan dalam memori tidak memiliki halaman. SQL Server menggunakan indeks untuk menghubungkan semua baris yang dimiliki tabel ke dalam satu struktur. Kami tidak dapat menggunakan pernyataan CREATE INDEX untuk membuat indeks untuk tabel yang dioptimalkan dalam memori. Setelah Anda membuat PRIMARY KEY pada kolom, SQL Server secara otomatis membuat indeks unik pada kolom tersebut. Sebenarnya, ini adalah satu-satunya indeks unik yang diizinkan. Anda dapat membuat maksimal delapan indeks pada tabel dengan memori yang dioptimalkan.
Dengan analogi dengan tabel, SQL Server menyimpan indeks yang dioptimalkan memori dalam memori. Namun, SQL Server tidak pernah mencatat operasi pada indeks. SQL Server memelihara indeks secara otomatis selama modifikasi tabel.
Tabel yang dioptimalkan memori mendukung dua jenis indeks:indeks hash dan indeks rentang . Keduanya adalah struktur non-cluster.
Indeks hash adalah jenis indeks baru, yang dirancang khusus untuk tabel dengan memori yang dioptimalkan. Ini sangat berguna untuk melakukan pencarian pada nilai-nilai tertentu. Indeks itu sendiri disimpan sebagai tabel hash. Ini adalah larik ember hash, di mana setiap ember adalah penunjuk ke satu baris.
Indeks rentang (non-clustered) berguna untuk mengambil rentang nilai.
Pemulihan
Mekanisme pemulihan dasar untuk database dengan tabel yang dioptimalkan memori sama dengan mekanisme pemulihan database dengan tabel berbasis disk. Namun, pemulihan tabel yang dioptimalkan memori mencakup langkah memuat tabel yang dioptimalkan memori ke dalam memori sebelum database tersedia untuk akses pengguna.
Saat SQL Server dimulai ulang, setiap database melewati fase proses pemulihan berikut:analisis , ulangi , dan membatalkan .
Pada fase analisis, mesin OLTP Dalam Memori mengidentifikasi inventaris pos pemeriksaan untuk memuat dan memuat entri log tabel sistemnya terlebih dahulu. Ini juga akan memproses beberapa catatan log alokasi file.
Pada fase redo, data dari pasangan data dan file delta dimuat ke dalam memori. Kemudian data diperbarui dari log transaksi aktif berdasarkan pos pemeriksaan tahan lama terakhir dan tabel dalam memori diisi dan indeks dibangun kembali. Selama fase ini, pemulihan tabel berbasis disk dan memori yang dioptimalkan berjalan secara bersamaan.
Fase undo tidak diperlukan untuk tabel dengan memori yang dioptimalkan karena OLTP Dalam Memori tidak mencatat transaksi yang tidak dikomit untuk tabel dengan memori yang dioptimalkan.
Ketika semua operasi selesai, database tersedia untuk diakses.
Ringkasan
Pada artikel ini, kami melihat sekilas mesin OLTP Dalam Memori SQL Server. Kami telah belajar bahwa struktur memori yang dioptimalkan disimpan dalam memori. Proses aplikasi dapat menemukan data yang diperlukan dengan mengakses struktur ini dalam memori tanpa memerlukan I/O disk. Dalam artikel berikut, kita akan melihat cara membuat dan mengakses database dan tabel OLTP Dalam Memori.
Bacaan lebih lanjut
OLTP Dalam Memori:Apa yang baru di SQL Server 2016
Menggunakan Indeks di Tabel yang Dioptimalkan Memori SQL Server