Dalam artikel saya sebelumnya, saya memulai seri baru tentang kait dengan menjelaskan apa itu, mengapa mereka dibutuhkan, dan mekanisme cara kerjanya, dan saya sangat menyarankan Anda membaca artikel itu sebelum artikel ini. Dalam artikel ini saya akan membahas kait FGCB_ADD_REMOVE dan menunjukkan bagaimana hal itu bisa menjadi hambatan.
Apa itu FGCB_ADD_REMOVE Latch?
Sebagian besar nama kelas kait terikat langsung ke struktur data yang mereka lindungi. Kait FGCB_ADD_REMOVE melindungi struktur data yang disebut FGCB, atau Blok Kontrol Grup File, dan akan ada salah satu kait ini untuk setiap grup file online dari setiap database online dalam contoh SQL Server. Setiap kali file dalam filegroup ditambahkan, dijatuhkan, ditumbuhkan, atau menyusut, latch harus diperoleh dalam mode EX, dan ketika mencari tahu file berikutnya untuk dialokasikan, latch harus diperoleh dalam mode SH untuk mencegah perubahan filegroup. (Ingat bahwa alokasi luas untuk filegroup dilakukan secara round-robin melalui file dalam filegroup, dan juga memperhitungkan pengisian proporsional , yang saya jelaskan di sini.)
Bagaimana Kait Menjadi Penghalang?
Skenario yang paling umum ketika kait ini menjadi hambatan adalah sebagai berikut:
- Ada database satu file, jadi semua alokasi harus berasal dari satu file data
- Pengaturan autogrow untuk file diatur menjadi sangat kecil (ingat, sebelum SQL Server 2016, pengaturan autogrow default untuk file data adalah 1MB!)
- Ada banyak operasi bersamaan yang membutuhkan ruang untuk dialokasikan (misalnya beban kerja penyisipan konstan dari banyak koneksi klien)
Dalam hal ini, meskipun hanya ada satu file, utas yang memerlukan alokasi masih harus memperoleh kait FGCB_ADD_REMOVE dalam mode SH. Kemudian akan mencoba untuk mengalokasikan dari file data tunggal, menyadari tidak ada ruang, dan kemudian memperoleh kait dalam mode EX sehingga kemudian dapat menumbuhkan file.
Mari kita bayangkan bahwa delapan utas yang berjalan pada delapan penjadwal terpisah semuanya mencoba mengalokasikan pada waktu yang sama, dan semua menyadari bahwa tidak ada ruang dalam file sehingga mereka perlu mengembangkannya. Mereka masing-masing akan mencoba untuk mendapatkan kait dalam mode EX. Hanya satu dari mereka yang dapat memperolehnya dan akan melanjutkan untuk mengembangkan file dan yang lain harus menunggu, dengan tipe tunggu LATCH_EX dan deskripsi sumber daya FGCB_ADD_REMOVE ditambah alamat memori kait.
Tujuh utas menunggu berada dalam antrian tunggu first-in-first-out (FIFO) gerendel. Ketika utas yang melakukan pertumbuhan file selesai, ia melepaskan kait dan memberikannya ke utas tunggu pertama. Pemilik gerendel yang baru ini pergi untuk mengembangkan file dan menemukan bahwa file tersebut telah berkembang dan tidak ada yang bisa dilakukan. Jadi itu melepaskan kait dan memberikannya ke utas tunggu berikutnya. Dan seterusnya.
Tujuh utas menunggu semuanya menunggu kait dalam mode EX tetapi akhirnya tidak melakukan apa-apa begitu mereka diberikan kait, jadi ketujuh utas pada dasarnya membuang waktu yang telah berlalu, dengan jumlah waktu yang terbuang meningkat sedikit untuk setiap utas semakin jauh ke bawah antrian menunggu FIFO.
Menunjukkan Kemacetan
Sekarang saya akan menunjukkan kepada Anda skenario yang tepat di atas, menggunakan acara yang diperluas. Saya telah membuat database file tunggal dengan pengaturan autogrow kecil, dan ratusan koneksi bersamaan hanya memasukkan data ke dalam tabel.
Saya dapat menggunakan sesi acara tambahan berikut untuk melihat apa yang terjadi:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO Sesi ini melacak saat utas memasuki antrean tunggu latch, saat meninggalkan antrean (yaitu saat diberikan latch), dan saat terjadi pertumbuhan file data. Menggunakan pelacakan kausalitas berarti kita dapat melihat garis waktu tindakan oleh setiap utas.
Menggunakan SQL Server Management Studio, saya dapat memilih opsi Tonton Data Langsung untuk sesi acara yang diperpanjang dan melihat semua aktivitas acara yang diperluas. Jika Anda ingin melakukan hal yang sama, pada jendela Live Data, klik kanan pada salah satu nama kolom di atas dan ubah kolom yang dipilih menjadi seperti di bawah ini:
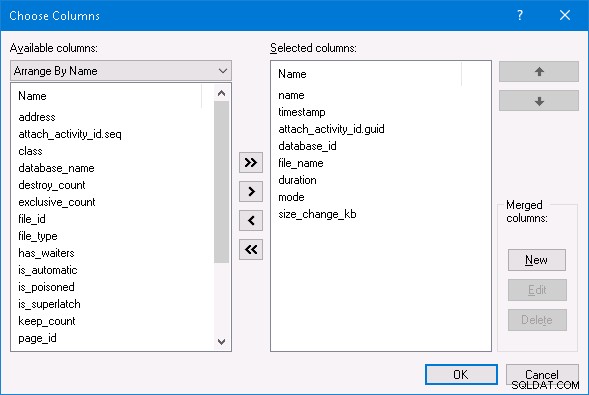
Saya membiarkan beban kerja berjalan selama beberapa menit untuk mencapai kondisi mapan dan kemudian melihat contoh sempurna dari skenario yang saya jelaskan di atas:
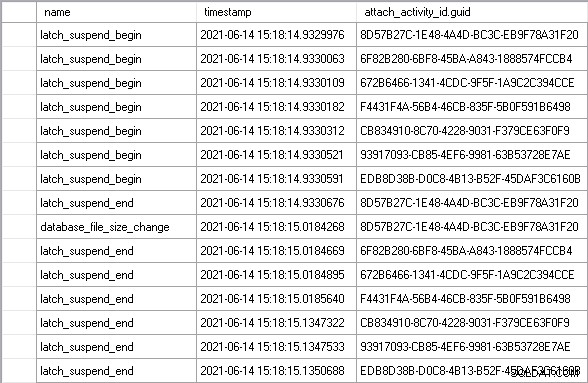
Menggunakan attach_activity_id.guid nilai untuk mengidentifikasi utas yang berbeda, kita dapat melihat bahwa tujuh utas mulai menunggu kait dalam waktu 61,5 mikrodetik. Utas dengan nilai GUID mulai 8D57 memperoleh kait dalam mode EX (latch_suspend_end event) dan kemudian segera mengembangkan file (database_file_size_change peristiwa). Utas 8D57 kemudian melepaskan kait dan memberikannya dalam mode EX ke utas 6F82, yang menunggu selama 85 milidetik. Tidak ada hubungannya sehingga memberikan kait ke utas 672B. Begitu seterusnya, hingga utas EDB8 diberikan kait, setelah menunggu selama 202 milidetik.
Secara total, enam utas yang menunggu tanpa alasan menunggu hampir 1 detik. Sebagian dari waktu itu adalah waktu tunggu sinyal, di mana meskipun thread telah diberikan latch, thread tersebut masih perlu naik ke atas antrian runnable penjadwal sebelum bisa masuk ke prosesor dan mengeksekusi kode. Anda mungkin mengatakan bahwa ini bukan ukuran yang adil dari waktu yang dihabiskan untuk menunggu kait, tetapi memang demikian, karena waktu tunggu sinyal tidak akan terjadi jika utas tidak harus menunggu sejak awal.
Selain itu, Anda mungkin berpikir bahwa penundaan 200 milidetik tidak terlalu banyak, tetapi itu semua tergantung pada perjanjian tingkat layanan kinerja untuk beban kerja yang bersangkutan. Kami memiliki beberapa klien bervolume tinggi di mana jika batch membutuhkan lebih dari 200 milidetik untuk dieksekusi, itu tidak diizinkan di sistem produksi!
Ringkasan
Jika Anda memantau menunggu di server Anda dan Anda melihat LATCH_EX adalah salah satu menunggu teratas, Anda dapat menggunakan kode di pos ini jadi lihat apakah FGCB_ADD_REMOVE adalah salah satu penyebabnya.
Cara termudah untuk memastikan bahwa beban kerja Anda tidak mencapai hambatan FGCB_ADD_REMOVE adalah memastikan bahwa tidak ada pengaturan autogrow file data yang dikonfigurasi menggunakan default pra-SQL Server 2016. Di sys.master_files tampilan, default 1MB akan ditampilkan sebagai file data (type_desc kolom disetel ke ROWS) dengan is_percent_growth kolom disetel ke 0, dan kolom pertumbuhan disetel ke 128.
Memberikan rekomendasi untuk autogrow apa yang harus disetel adalah diskusi lain, tetapi sekarang Anda mengetahui potensi dampak kinerja dari tidak mengubah default di versi sebelumnya.