Rencana eksekusi menyediakan sumber informasi yang kaya yang dapat membantu kami mengidentifikasi cara untuk meningkatkan kinerja kueri penting. Orang sering mencari hal-hal seperti pemindaian dan pencarian besar sebagai cara untuk mengidentifikasi potensi pengoptimalan jalur akses data. Masalah ini sering kali dapat diselesaikan dengan cepat dengan membuat indeks baru atau memperluas indeks yang sudah ada dengan lebih banyak kolom yang disertakan.
Kami juga dapat menggunakan paket pasca-eksekusi untuk membandingkan jumlah baris aktual dengan yang diharapkan antara operator paket. Jika ini ditemukan berbeda secara signifikan, kami dapat mencoba memberikan informasi statistik yang lebih baik kepada pengoptimal dengan memperbarui statistik yang ada, membuat objek statistik baru, memanfaatkan statistik pada kolom yang dihitung, atau mungkin dengan memecah kueri kompleks menjadi komponen yang kurang kompleks. bagian.
Selain itu, kita juga dapat melihat operasi yang mahal dalam rencana, terutama yang memakan memori seperti penyortiran dan hashing. Penyortiran terkadang dapat dihindari melalui perubahan pengindeksan. Di lain waktu, kita mungkin harus memfaktorkan ulang kueri menggunakan sintaks yang mendukung rencana yang mempertahankan urutan tertentu yang diinginkan.
Terkadang, performa tetap tidak cukup baik bahkan setelah semua teknik penyetelan performa ini diterapkan. Kemungkinan langkah selanjutnya adalah memikirkan lebih banyak tentang rencana secara keseluruhan . Ini berarti mundur selangkah, mencoba memahami keseluruhan strategi yang dipilih oleh pengoptimal kueri, untuk melihat apakah kami dapat mengidentifikasi peningkatan algoritme.
Artikel ini membahas jenis analisis yang terakhir ini, menggunakan contoh masalah sederhana untuk menemukan nilai kolom unik dalam kumpulan data yang cukup besar. Seperti yang sering terjadi dalam analogi masalah dunia nyata, kolom yang diinginkan akan memiliki nilai unik yang relatif sedikit, dibandingkan dengan jumlah baris dalam tabel. Ada dua bagian dalam analisis ini:membuat data sampel, dan menulis kueri nilai-berbeda itu sendiri.
Membuat Data Sampel
Untuk memberikan contoh yang paling sederhana, tabel pengujian kami hanya memiliki satu kolom dengan indeks berkerumun (kolom ini akan menyimpan nilai duplikat sehingga indeks tidak dapat dinyatakan unik):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
Untuk memilih beberapa nomor dari udara, kami akan memilih untuk memuat sepuluh juta baris secara total, dengan distribusi yang merata pada seribu nilai berbeda . Teknik umum untuk menghasilkan data seperti ini adalah dengan menggabungkan beberapa tabel sistem dan menerapkan ROW_NUMBER fungsi. Kami juga akan menggunakan operator modulo untuk membatasi angka yang dihasilkan ke nilai berbeda yang diinginkan:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Perkiraan rencana eksekusi untuk kueri tersebut adalah sebagai berikut (klik gambar untuk memperbesarnya jika perlu):

Ini membutuhkan waktu sekitar 30 detik untuk membuat sampel data di laptop saya. Itu bukan waktu yang lama, tetapi tetap menarik untuk mempertimbangkan apa yang mungkin kita lakukan untuk membuat proses ini lebih efisien…
Analisis Rencana
Kita akan mulai dengan memahami untuk apa setiap operasi dalam rencana itu.
Bagian dari rencana eksekusi di sebelah kanan operator Segmen berkaitan dengan pembuatan baris dengan menggabungkan tabel sistem:

Operator Segmen ada jika fungsi jendela memiliki PARTITION BY ayat. Itu tidak terjadi di sini, tetapi tetap ada dalam rencana kueri. Operator Proyek Urutan menghasilkan nomor baris, dan Bagian Atas membatasi keluaran paket hingga sepuluh juta baris:

Skalar Hitung mendefinisikan ekspresi yang menerapkan fungsi modulo dan menambahkan satu ke hasil:

Kita dapat melihat bagaimana label ekspresi Sequence Project dan Compute Scalar berhubungan menggunakan tab Expressions Plan Explorer:

Ini memberi kita perasaan yang lebih lengkap untuk alur rencana ini:Proyek Urutan memberi nomor pada baris dan memberi label pada ekspresi Expr1050; Compute Scalar melabeli hasil dari modulo dan komputasi plus-satu sebagai Expr1052 . Perhatikan juga konversi implisit dalam ekspresi Compute Scalar. Kolom tabel tujuan bertipe integer, sedangkan ROW_NUMBER fungsi menghasilkan bigint, jadi konversi penyempitan diperlukan.
Operator berikutnya dalam rencana adalah Sortir. Menurut perkiraan biaya pengoptimal kueri, ini diharapkan menjadi operasi yang paling mahal (88,1% perkiraan ):

Mungkin tidak segera jelas mengapa paket ini menampilkan penyortiran, karena tidak ada persyaratan pemesanan eksplisit dalam kueri. Sortir ditambahkan ke rencana untuk memastikan baris tiba di operator Sisipkan Indeks Cluster dalam urutan indeks berkerumun. Ini mendorong penulisan berurutan, menghindari pemisahan halaman, dan merupakan salah satu prasyarat untuk INSERT yang di-log minimal operasi.
Ini semua adalah hal yang berpotensi baik, tetapi Sortir itu sendiri agak mahal. Memang, memeriksa rencana eksekusi pasca-eksekusi ("aktual") mengungkapkan Sort juga kehabisan memori pada waktu eksekusi dan harus tumpah ke tempdb fisik cakram:

Tumpahan Sortir terjadi meskipun perkiraan jumlah baris tepat, dan terlepas dari kenyataan bahwa kueri diberikan semua memori yang diminta (seperti yang terlihat di properti rencana untuk INSERT root) simpul):

Sortir tumpahan juga ditunjukkan dengan adanya IO_COMPLETION menunggu di tab statistik tunggu Plan Explorer PRO:

Terakhir untuk bagian analisis rencana ini, perhatikan DML Request Sort properti operator Sisipan Indeks Clustered disetel true:

Tanda ini menunjukkan bahwa pengoptimal memerlukan subpohon di bawah Sisipkan untuk menyediakan baris dalam urutan kunci indeks yang diurutkan (karenanya perlu operator Sortir yang bermasalah).
Menghindari Pengurutan
Sekarang kita tahu mengapa Sortir muncul, kita dapat menguji untuk melihat apa yang terjadi jika kita menghapusnya. Ada beberapa cara kami dapat menulis ulang kueri untuk "membodohi" pengoptimal dengan berpikir lebih sedikit baris yang akan dimasukkan (jadi penyortiran tidak akan bermanfaat) tetapi cara cepat untuk menghindari pengurutan secara langsung (hanya untuk tujuan eksperimental) adalah dengan menggunakan tanda jejak tidak berdokumen 8795. Ini menetapkan DML Request Sort properti ke false, sehingga baris tidak lagi diperlukan untuk tiba di Sisipan Indeks Cluster dalam urutan kunci berkerumun:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Rencana kueri pasca-eksekusi yang baru adalah sebagai berikut (klik gambar untuk memperbesar):

Operator Sortir telah hilang, tetapi kueri baru berjalan selama lebih dari 50 detik (dibandingkan dengan 30 detik sebelum). Ada beberapa alasan untuk ini. Pertama, kami kehilangan kemungkinan penyisipan dengan log minimal karena ini memerlukan data yang diurutkan (Urutan Permintaan DML =true). Kedua, sejumlah besar pemisahan halaman "buruk" akan terjadi selama penyisipan. Dalam kasus yang tampaknya kontra-intuitif, ingat bahwa meskipun ROW_NUMBER fungsi nomor baris berurutan, efek dari operator modulo adalah untuk menyajikan urutan berulang angka 1…1000 ke Sisipan Indeks Cluster.
Masalah mendasar yang sama terjadi jika kita menggunakan trik T-SQL untuk menurunkan jumlah baris yang diharapkan untuk menghindari pengurutan alih-alih menggunakan tanda pelacakan yang tidak didukung.
Menghindari Sortir II
Melihat rencana secara keseluruhan, tampak jelas bahwa kami ingin menghasilkan baris dengan cara yang menghindari pengurutan eksplisit, tetapi masih menuai manfaat dari logging minimal dan penghindaran pemisahan halaman yang buruk. Sederhananya:kami ingin rencana yang menyajikan baris dalam urutan kunci berkerumun, tetapi tanpa pengurutan.
Berbekal wawasan baru ini, kami dapat mengekspresikan kueri kami dengan cara yang berbeda. Kueri berikut menghasilkan setiap angka dari 1 hingga 1000 dan gabungan silang yang ditetapkan dengan 10.000 baris untuk menghasilkan tingkat duplikasi yang diperlukan. Idenya adalah untuk menghasilkan set sisipan yang menampilkan 10.000 baris bernomor '1' kemudian 10.000 bernomor '2' … dan seterusnya.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Sayangnya, pengoptimal masih menghasilkan rencana dengan semacam:

Tidak banyak yang bisa dikatakan dalam pertahanan pengoptimal di sini, ini hanya rencana gila. Ia telah memilih untuk menghasilkan 10.000 baris kemudian menggabungkan silang dengan angka dari 1 hingga 1000. Ini tidak memungkinkan urutan alami angka dipertahankan, sehingga pengurutan tidak dapat dihindari.
Menghindari Penyortiran – Akhirnya!
Strategi yang terlewatkan oleh pengoptimal adalah mengambil angka 1…1000 pertama , dan gabungkan silang setiap nomor dengan 10.000 baris (membuat 10.000 salinan dari setiap nomor secara berurutan). Rencana yang diharapkan akan menghindari pengurutan dengan menggunakan gabungan loop bersarang yang mempertahankan urutan dari baris pada input luar.
Kami dapat mencapai hasil ini dengan memaksa pengoptimal untuk mengakses tabel turunan dalam urutan yang ditentukan dalam kueri, menggunakan FORCE ORDER petunjuk kueri:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Akhirnya, kami mendapatkan rencana yang kami cari:
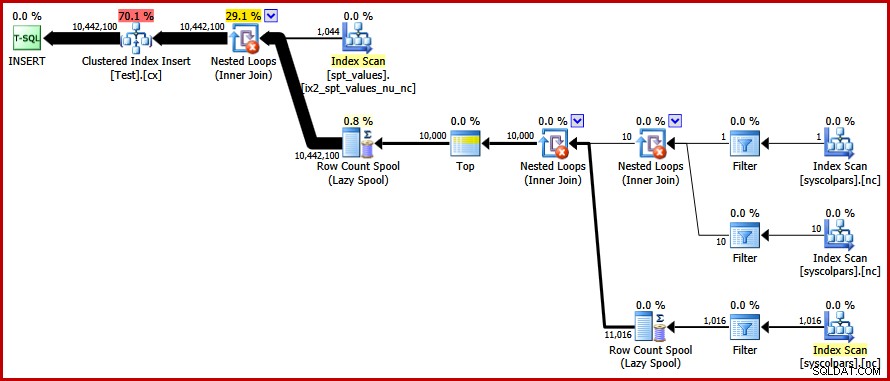
Paket ini menghindari pengurutan eksplisit sambil tetap menghindari pemisahan halaman "buruk" dan memungkinkan penyisipan yang dicatat secara minimal ke indeks berkerumun (dengan asumsi database tidak menggunakan FULL model pemulihan). Itu memuat sepuluh juta baris dalam waktu sekitar 9 detik di laptop saya (dengan satu disk berputar SATA 7200 rpm). Ini menunjukkan peningkatan efisiensi yang nyata selama 30-50 detik waktu berlalu yang terlihat sebelum penulisan ulang.
Menemukan Nilai yang Berbeda
Sekarang kita memiliki data sampel yang dibuat, kita dapat mengalihkan perhatian kita untuk menulis kueri untuk menemukan nilai yang berbeda dalam tabel. Cara alami untuk mengekspresikan persyaratan ini dalam T-SQL adalah sebagai berikut:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Rencana eksekusi sangat sederhana, seperti yang Anda harapkan:

Ini membutuhkan waktu sekitar 2900 md untuk berjalan di mesin saya, dan membutuhkan 43.406 pembacaan logis:

Menghapus MAXDOP (1) petunjuk kueri menghasilkan rencana paralel:

Ini selesai dalam waktu sekitar 1500 md (tetapi dengan 8.764 md waktu CPU yang digunakan), dan 43.804 pembacaan logis:

Rencana dan hasil kinerja yang sama jika kita menggunakan GROUP BY bukannya DISTINCT .
Algoritme yang Lebih Baik
Paket kueri yang ditampilkan di atas membaca semua nilai dari tabel dasar dan memprosesnya melalui Agregat Aliran. Memikirkan tugas secara keseluruhan, tampaknya tidak efisien untuk memindai semua 10 juta baris ketika kita mengetahui bahwa hanya ada sedikit nilai yang berbeda.
Strategi yang lebih baik mungkin untuk menemukan satu nilai terendah dalam tabel, kemudian menemukan nilai tertinggi berikutnya, dan seterusnya sampai kita kehabisan nilai. Yang terpenting, pendekatan ini cocok untuk pencarian tunggal ke dalam indeks daripada memindai setiap baris.
Kami dapat menerapkan ide ini dalam satu kueri menggunakan CTE rekursif, di mana bagian jangkar menemukan terendah nilai yang berbeda, maka bagian rekursif menemukan nilai yang berbeda berikutnya dan seterusnya. Upaya pertama untuk menulis kueri ini adalah:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Sayangnya, sintaks tersebut tidak dapat dikompilasi:

Oke, jadi fungsi agregat tidak diperbolehkan. Alih-alih menggunakan MIN , kita dapat menulis logika yang sama menggunakan TOP (1) dengan ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Masih belum ada kegembiraan.
Ternyata kita bisa menyiasati batasan ini dengan menulis ulang bagian rekursif untuk memberi nomor pada kandidat baris dalam urutan yang diperlukan, lalu memfilter untuk baris yang diberi nomor 'satu'. Ini mungkin tampak sedikit berputar-putar, tetapi logikanya persis sama:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Kueri ini tidak kompilasi, dan hasilkan rencana pasca-eksekusi berikut:

Perhatikan operator Top di bagian rekursif dari rencana eksekusi (disorot). Kami tidak dapat menulis T-SQL TOP di bagian rekursif dari ekspresi tabel umum rekursif, tetapi itu tidak berarti pengoptimal tidak dapat menggunakannya! Pengoptimal memperkenalkan Top berdasarkan alasan tentang jumlah baris yang perlu diperiksa untuk menemukan satu nomor '1'.
Kinerja rencana (non-paralel) ini jauh lebih baik daripada pendekatan Agregat Aliran. Ini selesai dalam waktu sekitar 50 md , dengan 3007 pembacaan logis terhadap tabel sumber (dan 6001 baris dibaca dari meja kerja spool), dibandingkan dengan 1500 md terbaik sebelumnya (waktu CPU 8764 mdtk pada DOP 8) dan 43.804 pembacaan logis:


Kesimpulan
Tidak selalu mungkin untuk mencapai terobosan dalam kinerja kueri dengan mempertimbangkan elemen rencana kueri individual sendiri. Terkadang, kita perlu menganalisis strategi di balik keseluruhan rencana eksekusi, lalu berpikir secara lateral untuk menemukan algoritme dan implementasi yang lebih efisien.