SQL Server 2014 SP2 dan yang lebih baru menghasilkan rencana eksekusi runtime ("aktual") yang dapat menyertakan waktu yang telah berlalu dan penggunaan CPU untuk setiap operator rencana eksekusi (lihat KB3170113 dan posting blog ini oleh Pedro Lopes).
Menafsirkan angka-angka ini tidak selalu semudah yang diharapkan. Ada perbedaan penting antara mode baris dan mode kumpulan eksekusi, serta masalah rumit dengan mode baris paralelisme . SQL Server membuat beberapa waktu penyesuaian dalam rencana paralel untuk mempromosikan konsistensi, tetapi mereka tidak diimplementasikan dengan sempurna. Hal ini dapat membuat sulit untuk menarik kesimpulan penyetelan kinerja yang baik.
Artikel ini bertujuan untuk membantu Anda memahami dari mana pengaturan waktu berasal dalam setiap kasus, dan bagaimana cara terbaik untuk menafsirkannya dalam konteks.
Penyiapan
Contoh berikut menggunakan Stack Overflow 2013 publik database (detail unduhan), dengan satu indeks ditambahkan:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Kueri tes mengembalikan jumlah pertanyaan dengan jawaban yang diterima, dikelompokkan berdasarkan bulan dan tahun. Mereka dijalankan di SQL Server 2019 CU9 , pada laptop dengan 8 inti, dan memori 16 GB yang dialokasikan untuk instans SQL Server 2019. Tingkat kompatibilitas 150 digunakan secara eksklusif.
Eksekusi Serial Mode Batch
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Rencana pelaksanaannya adalah (klik untuk memperbesar):
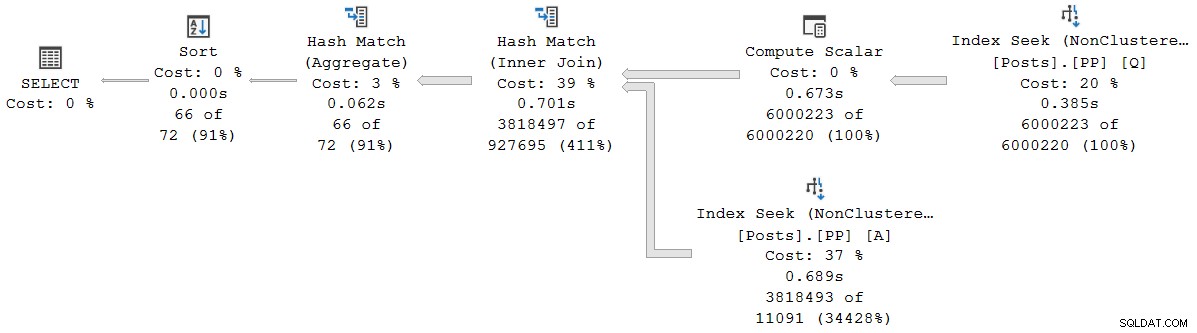
Setiap operator dalam paket ini berjalan dalam mode batch, berkat mode batch di rowstore Fitur Intelligent Query Processing di SQL Server 2019 (tidak diperlukan indeks columnstore). Kueri berjalan selama 2,523 md dengan waktu CPU 2.522ms yang digunakan, ketika semua data yang dibutuhkan sudah ada di buffer pool.
Seperti yang dicatat Pedro Lopes dalam posting blog yang ditautkan sebelumnya, waktu yang telah berlalu dan waktu CPU dilaporkan untuk mode batch individual operator mewakili waktu yang digunakan oleh operator itu sendiri .
SSMS menampilkan waktu yang berlalu dalam representasi grafis. Untuk melihat waktu CPU , pilih operator paket, lalu lihat di Properti jendela. Tampilan mendetail ini menunjukkan waktu yang telah berlalu dan CPU, per operator, dan per utas.
Waktu showplan (termasuk representasi XML) dipotong untuk milidetik. Jika Anda membutuhkan presisi yang lebih tinggi, gunakan query_thread_profile acara diperpanjang, yang melaporkan dalam mikrodetik . Output dari acara ini untuk rencana eksekusi yang ditunjukkan di atas adalah:
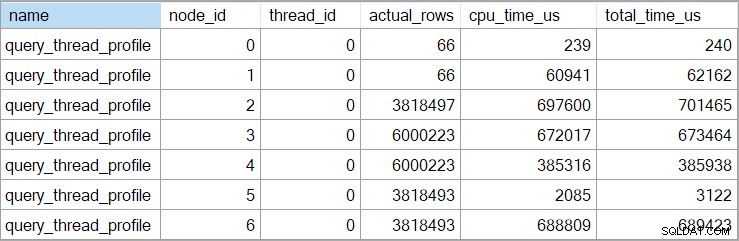
Ini menunjukkan waktu yang telah berlalu untuk join (node 2) adalah 701.465µs (dipotong menjadi 701ms di showplan). Agregat memiliki waktu berlalu 62.162µs (62ms). Pencarian indeks 'pertanyaan' ditampilkan sebagai berjalan selama 385 md, sedangkan peristiwa yang diperluas menunjukkan angka sebenarnya untuk simpul 4 adalah 385.938 md (hampir 386 md).
SQL Server menggunakan presisi tinggi Penghitung Kinerja Kueri API untuk menangkap data waktu. Ini menggunakan perangkat keras, biasanya osilator kristal, yang menghasilkan kutu pada tingkat konstan yang sangat tinggi terlepas dari kecepatan prosesor, pengaturan daya, atau hal semacam itu. Jam terus berjalan dengan kecepatan yang sama bahkan saat tidur. Lihat artikel tertaut yang sangat terperinci jika Anda tertarik dengan semua detail yang lebih baik. Ringkasan singkatnya adalah Anda dapat memercayai keakuratan angka mikrodetik.
Dalam rencana mode batch murni ini, total waktu eksekusi sangat dekat dengan jumlah waktu berlalu masing-masing operator. Perbedaannya sebagian besar terletak pada pekerjaan pasca-pernyataan yang tidak terkait dengan operator paket (yang semuanya telah ditutup saat itu), meskipun pemotongan milidetik juga berperan.
Dalam paket mode batch murni, Anda perlu menjumlahkan waktu operator saat ini dan anak secara manual untuk mendapatkan kumulatif waktu yang telah berlalu pada setiap node tertentu.
Eksekusi Paralel Mode Batch
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Rencana eksekusi adalah:
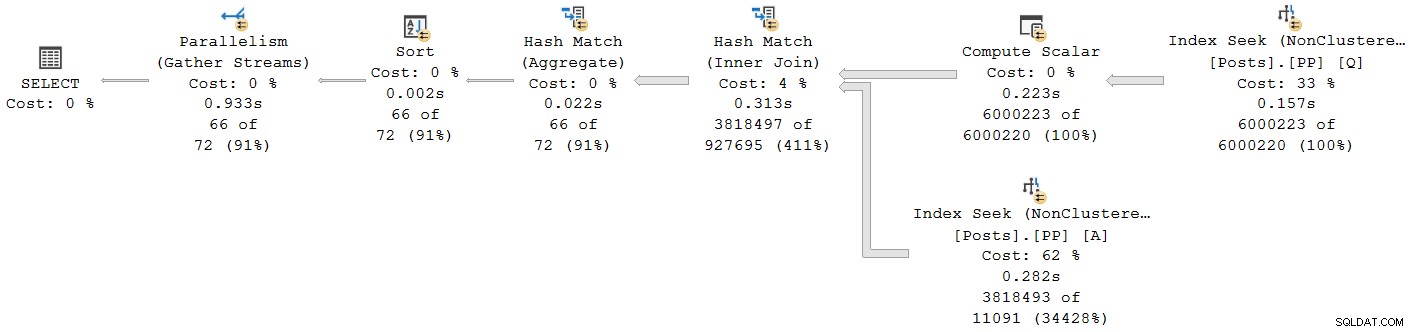
Setiap operator kecuali pertukaran aliran pengumpulan terakhir berjalan dalam mode batch. Total waktu yang telah berlalu adalah 933 md dengan 6.673 md waktu CPU dengan cache hangat.
Memilih hash join dan mencari di SSMS Properties jendela, kita melihat waktu CPU berlalu dan per utas untuk operator itu:
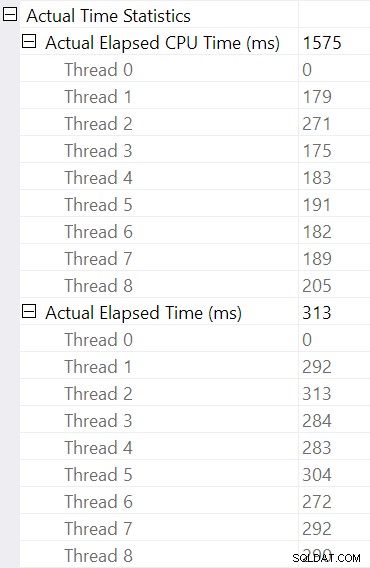
Waktu CPU dilaporkan untuk operator adalah jumlah dari waktu CPU utas individu. Operator yang dilaporkan waktu yang berlalu adalah maksimum dari waktu berlalu per-utas. Kedua perhitungan dilakukan pada nilai milidetik terpotong per-utas. Seperti sebelumnya, total waktu eksekusi sangat dekat dengan jumlah waktu yang dilalui oleh masing-masing operator.
Paket paralel mode batch tidak menggunakan pertukaran untuk mendistribusikan pekerjaan di antara utas. Operator batch diimplementasikan sehingga beberapa utas dapat bekerja secara efisien pada struktur bersama single tunggal (misalnya tabel hash). Beberapa sinkronisasi antar utas masih diperlukan dalam paket paralel mode batch, tetapi titik sinkronisasi dan detail lainnya tidak terlihat di output showplan.
Eksekusi Serial Mode Baris
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Rencana eksekusi secara visual sama dengan rencana serial mode batch, tetapi setiap operator sekarang berjalan dalam mode baris:
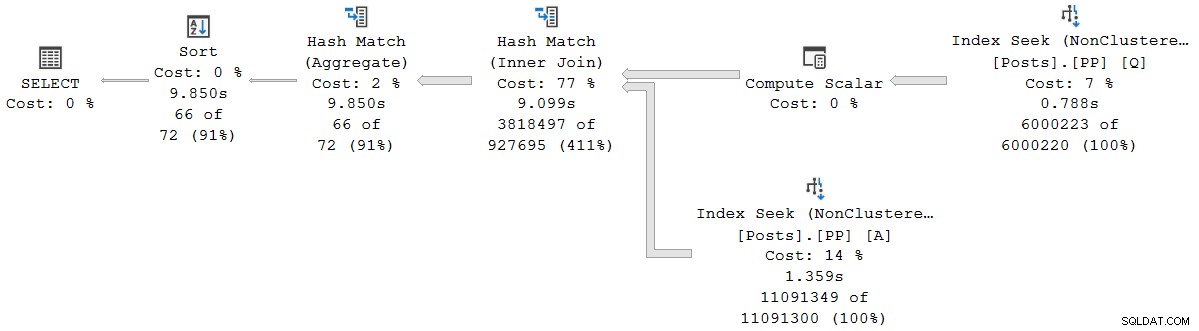
Kueri berjalan selama 9.850 md dengan waktu CPU 9.845ms. Ini jauh lebih lambat daripada kueri mode batch serial (2523ms/2522ms), seperti yang diharapkan. Lebih penting lagi untuk diskusi kali ini, mode baris operator berlalu dan waktu CPU mewakili waktu yang digunakan oleh operator saat ini dan semua turunannya .
Peristiwa yang diperpanjang juga menunjukkan CPU kumulatif dan waktu yang telah berlalu di setiap node (dalam mikrodetik):
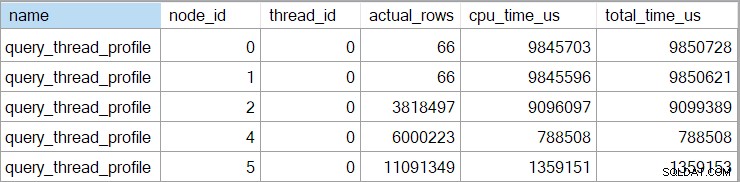
Tidak ada data untuk operator skalar komputasi (simpul 3) karena eksekusi mode baris dapat menunda sebagian besar komputasi ekspresi ke operator yang menggunakan hasilnya. Ini saat ini tidak diterapkan untuk eksekusi mode batch.
kumulatif . yang dilaporkan waktu yang telah berlalu untuk operator mode baris berarti waktu yang ditampilkan untuk operator pengurutan akhir sangat cocok dengan total waktu eksekusi untuk kueri (tetap ke resolusi milidetik). Waktu yang berlalu untuk hash join juga termasuk kontribusi dari dua indeks yang dicari di bawahnya, serta waktunya sendiri. Untuk menghitung waktu yang berlalu untuk penggabungan hash mode baris saja, kita perlu mengurangi kedua waktu pencarian darinya.
Ada keuntungan dan kerugian untuk kedua presentasi (kumulatif untuk mode baris, operator individu hanya untuk mode batch). Apa pun yang Anda suka, penting untuk mengetahui perbedaannya.
Paket mode eksekusi campuran
Secara umum, rencana eksekusi modern dapat berisi campuran mode baris dan operator mode batch. Operator mode batch akan melaporkan waktu hanya untuk diri mereka sendiri. Operator mode baris akan menyertakan total kumulatif hingga titik tersebut dalam rencana, termasuk semua operator anak. Untuk memperjelasnya:waktu kumulatif operator mode baris termasuk semua operator anak mode batch.
Kami melihat ini sebelumnya dalam rencana mode batch paralel:Operator pengumpulan stream terakhir (mode baris) memiliki waktu berlalu (kumulatif) yang ditampilkan selama 0,933 detik — termasuk semua operator mode batch turunannya. Operator lain semuanya mode batch, dan waktu yang dilaporkan untuk operator individu saja.
Situasi ini, di mana beberapa operator paket dalam paket yang sama memiliki waktu kumulatif dan yang lainnya tidak, tidak diragukan lagi akan dianggap sebagai membingungkan oleh banyak orang.
Eksekusi Paralel Mode Baris
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Rencana eksekusi adalah:

Setiap operator adalah mode baris. Kueri berjalan selama 4.677 md dengan waktu CPU 23.311 md (jumlah semua utas).
Sebagai paket mode baris eksklusif, kami mengharapkan semua waktu menjadi kumulatif . Berpindah dari anak ke orang tua (kanan ke kiri), waktu seharusnya meningkat ke arah itu.
Mari kita lihat bagian paling kanan dari rencana:
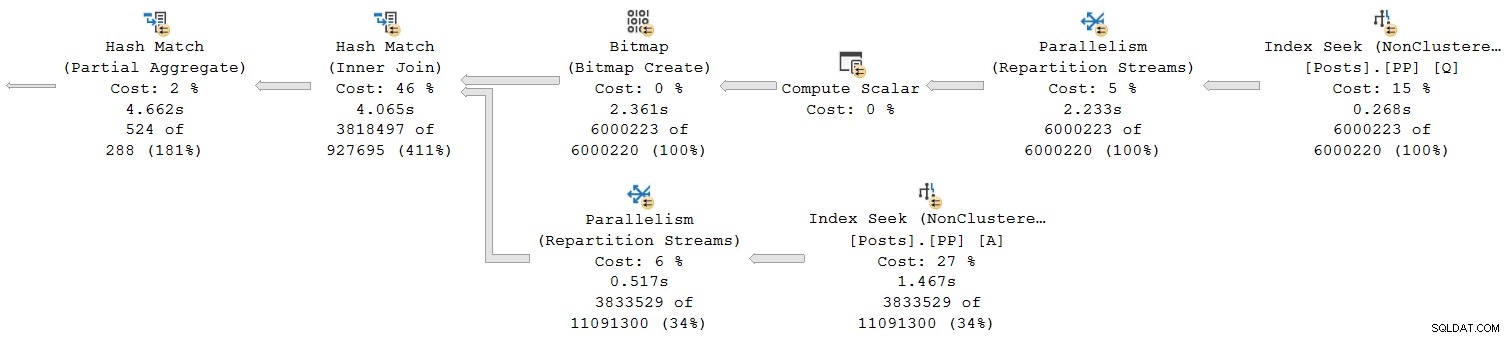
Bekerja dari kanan ke kiri di baris atas, waktu kumulatif tampaknya menjadi masalah. Tapi ada pengecualian pada input yang lebih rendah ke hash join:Pencarian indeks memiliki waktu yang telah berlalu 1.467 detik , sedangkan induknya aliran partisi ulang hanya memiliki waktu 0,517 detik .
Bagaimana seorang orang tua operator berjalan lebih sedikit waktu daripada anaknya apakah waktu yang telah berlalu bersifat kumulatif dalam rencana mode baris?
Waktu tidak konsisten
Ada beberapa bagian untuk menjawab teka-teki ini. Mari kita ambil sepotong demi sepotong, karena cukup rumit:
Pertama, ingat bahwa pertukaran (operator paralelisme) memiliki dua bagian. Tangan kiri (konsumen ) sisi terhubung ke satu set utas yang menjalankan operator di cabang paralel ke kiri. Tangan kanan (produser ) sisi pertukaran terhubung ke rangkaian berbeda yang menjalankan operator di cabang paralel di sebelah kanan.
Baris dari sisi produsen dirangkai menjadi paket dan kemudian ditransfer ke sisi konsumen. Ini memberikan tingkat penyangga dan kontrol aliran antara dua set utas yang terhubung. (Jika Anda membutuhkan penyegaran di bursa dan cabang paket paralel, silakan lihat artikel saya Rencana Eksekusi Paralel – Cabang dan Utas.)
Cakupan waktu kumulatif
Melihat cabang paralel di produser sisi pertukaran:
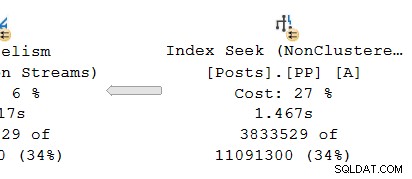
Seperti biasa, utas pekerja tambahan DOP (derajat paralelisme) menjalankan serial . independen salinan rencana operator di cabang ini. Jadi, pada DOP 8, ada 8 pencarian indeks serial independen yang bekerja sama untuk melakukan bagian pemindaian rentang dari operasi pencarian indeks keseluruhan (paralel). Setiap pencarian utas tunggal terhubung ke input (port) yang berbeda di sisi produsen dari tunggal yang dibagikan operator pertukaran.
Situasi serupa terjadi pada konsumen sisi pertukaran. Di DOP 8, ada 8 salinan utas tunggal terpisah dari cabang ini, semuanya berjalan secara independen:
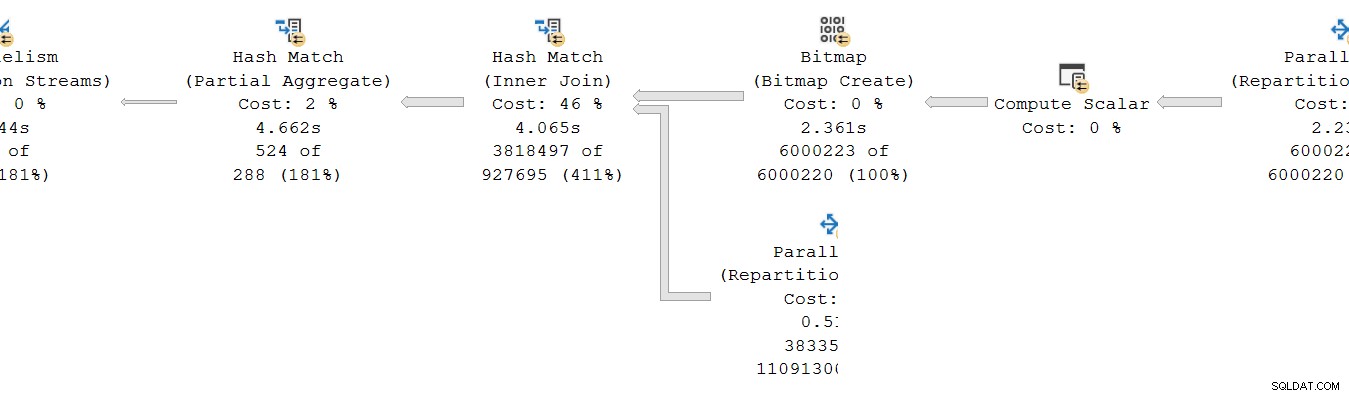
Masing-masing subplan utas tunggal ini berjalan dengan cara biasa, dengan setiap operator mengumpulkan waktu yang telah berlalu dan total waktu CPU di setiap node. Menjadi operator mode baris, setiap total mewakili waktu yang dihabiskan total kumulatif untuk simpul saat ini dan setiap turunannya.
Poin penting adalah bahwa jumlah kumulatif hanya sertakan operator di utas yang sama dan hanya di dalam cabang saat ini . Mudah-mudahan, ini masuk akal secara intuitif, karena setiap utas tidak tahu apa yang mungkin terjadi di tempat lain.
Bagaimana metrik mode baris dikumpulkan
Bagian kedua dari teka-teki berkaitan dengan cara penghitungan baris dan metrik waktu dikumpulkan dalam rencana mode baris. Saat informasi rencana runtime (“aktual”) diperlukan, mesin eksekusi menambahkan tak terlihat membuat profil operator ke sebelah kiri (induk) dari setiap operator dalam rencana yang akan dieksekusi saat runtime.
Operator ini dapat merekam (antara lain) perbedaan antara waktu di mana ia melewati kontrol ke operator anak, dan waktu ketika kontrol dikembalikan. Perbedaan waktu ini menunjukkan waktu yang telah berlalu untuk operator yang dipantau dan semua anaknya , karena anak memanggil ke anaknya sendiri per baris dan seterusnya. Operator dapat dipanggil berkali-kali (untuk menginisialisasi, lalu sekali per baris, akhirnya ditutup) sehingga waktu yang dikumpulkan oleh operator pembuatan profil adalah akumulasi atas kemungkinan banyak iterasi per baris.
Untuk detail selengkapnya tentang data profil dikumpulkan menggunakan metode pengambilan yang berbeda, lihat dokumentasi produk yang mencakup Infrastruktur Pembuatan Profil Kueri. Bagi mereka yang tertarik dengan hal-hal seperti itu, nama operator pembuatan profil tak terlihat yang digunakan oleh infrastruktur standar adalah sqlmin!CQScanProfileNew . Seperti semua iterator mode baris, ia memiliki Open , GetRow , dan Close metode, antara lain. Setiap metode berisi panggilan ke QueryPerformanceCounter Windows API untuk mengumpulkan nilai pengatur waktu resolusi tinggi saat ini.
Karena operator pembuatan profil berada di kiri operator target, ini hanya mengukur konsumen sisi pertukaran. Tidak ada tidak ada operator pembuatan profil untuk produser sisi pertukaran (sayangnya). Jika ada, itu akan cocok atau melebihi waktu yang telah berlalu yang ditunjukkan pada pencarian indeks, karena pencarian indeks dan sisi produsen menjalankan rangkaian utas yang sama dan sisi produsen pertukaran adalah operator induk dari pencarian indeks.
Waktu ditinjau kembali

Dengan semua itu, Anda mungkin masih mengalami masalah dengan pengaturan waktu yang ditunjukkan di atas. Bagaimana pencarian indeks dapat berlangsung 1,467 detik untuk meneruskan baris ke sisi produsen dari suatu pertukaran, tetapi sisi konsumen hanya membutuhkan waktu 0,517 detik untuk menerima mereka? Terlepas dari utas terpisah, buffering, dan yang lainnya, pasti pertukaran harus berjalan (end-to-end) lebih lama daripada pencarian?
Ya, memang, tapi itu pengukuran yang berbeda dari waktu yang telah berlalu atau CPU. Mari kita tepat tentang apa yang kita ukur di sini.
Untuk mode baris waktu yang berlalu , bayangkan stopwatch per utas di masing-masing operator. Stopwatch dimulai ketika SQL Server memasukkan kode untuk operator dari induknya, dan berhenti (tetapi tidak mengatur ulang) ketika kode itu meninggalkan operator untuk mengembalikan kontrol kembali ke induk (bukan ke anak). Waktu berlalu termasuk setiap penundaan atau penundaan penjadwalan – tak satu pun dari itu yang menghentikan jam tangan.
Untuk mode baris waktu CPU , bayangkan stopwatch yang sama dengan karakteristik yang sama, kecuali stopwatch tersebut berhenti selama menunggu dan menjadwalkan penundaan. Ini hanya mengakumulasikan waktu ketika operator atau salah satu anaknya secara aktif mengeksekusi pada scheduler (CPU). Total waktu pada stopwatch per thread per operator dibangun dari siklus start-stop untuk setiap baris.
Mari kita terapkan itu pada situasi saat ini dengan sisi konsumen dari bursa dan pencarian indeks:
Ingat, sisi konsumen dari pertukaran dan pencarian indeks berada di cabang yang terpisah, jadi keduanya berjalan di utas terpisah . Sisi konsumen tidak memiliki anak di utas yang sama. Pencarian indeks memiliki sisi produsen bursa sebagai induk utas yang sama, tetapi kami tidak memiliki stopwatch di sana.
Setiap utas konsumen memulai arlojinya ketika operator induknya (sisi probe dari hash join) melewati kontrol (mis. untuk mengambil baris). Arloji terus berjalan saat konsumen mengambil baris dari paket pertukaran saat ini. Jam tangan berhenti ketika kontrol meninggalkan konsumen dan kembali ke sisi penyelidikan hash join. Orang tua lebih lanjut (agregat parsial dan pertukaran induknya) juga akan bekerja pada baris itu (dan mungkin menunggu) sebelum kontrol kembali ke sisi konsumen dari pertukaran kita untuk mengambil baris berikutnya. Pada saat itu, sisi konsumen dari pertukaran kami mulai mengakumulasi waktu yang telah berlalu dan waktu CPU lagi.
Sementara itu, terlepas dari apa pun yang mungkin dilakukan oleh utas cabang sisi konsumen, pencarian indeks utas terus mencari baris dalam indeks dan memasukkannya ke dalam pertukaran. Sebuah utas pencarian indeks memulai stopwatch-nya ketika sisi produsen bursa memintanya untuk berturut-turut. Stopwatch dijeda ketika baris dilewatkan ke bursa. Saat bursa meminta baris berikutnya, stopwatch pencarian indeks dilanjutkan.
Perhatikan bahwa pertukaran sisi produsen mungkin mengalami CXPACKET menunggu saat buffer pertukaran terisi, tetapi itu tidak akan menambah waktu yang telah berlalu yang dicatat pada pencarian indeks karena stopwatch-nya tidak berjalan saat itu terjadi. Jika kita memiliki stopwatch untuk sisi produsen bursa, waktu berlalu yang hilang akan muncul di sana.
Untuk memperkirakan ringkasan situasi secara visual, diagram berikut menunjukkan kapan setiap operator mengakumulasi waktu yang telah berlalu di dua cabang paralel:
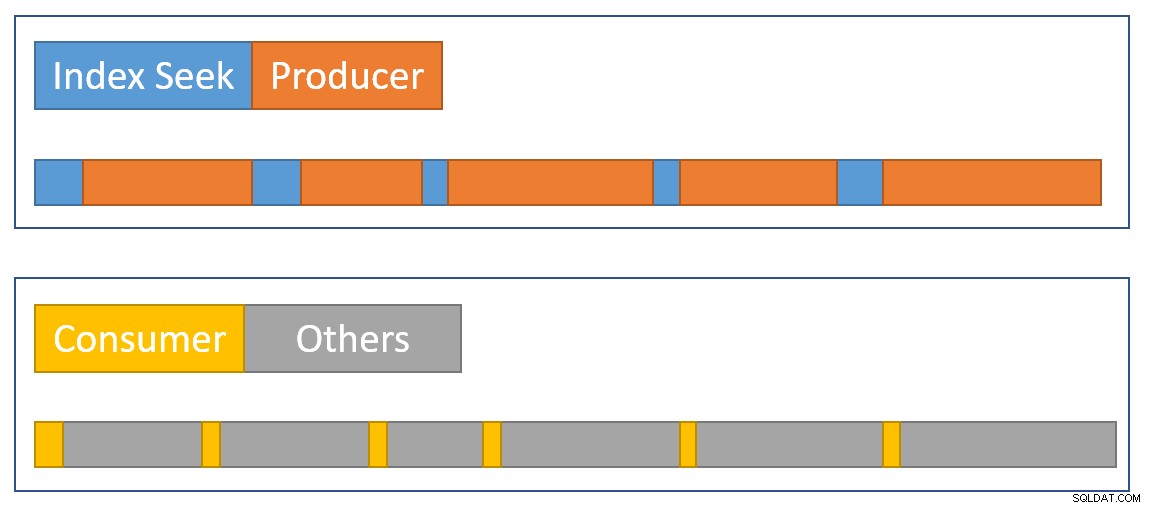
biru bar waktu pencarian indeks pendek karena mengambil baris dari indeks cepat. oranye waktu produksi mungkin lama karena CXPACKET menunggu. kuning waktu konsumen singkat karena cepat untuk mengambil baris dari pertukaran ketika data tersedia. abu-abu segmen waktu mewakili waktu yang digunakan oleh operator lain (sisi hash join probe, agregat parsial, dan sisi produsen bursa induknya) di atas sisi konsumen bursa.
Kami berharap paket pertukaran diisi dengan cepat oleh pencarian indeks, tetapi dikosongkan perlahan (relatif berbicara) oleh operator sisi konsumen karena mereka memiliki lebih banyak pekerjaan yang harus dilakukan. Ini berarti paket dalam pertukaran biasanya akan penuh atau hampir penuh. Konsumen akan dapat mengambil baris tunggu dengan cepat, tetapi produsen mungkin harus menunggu ruang paket muncul.
Sayang sekali kita tidak bisa melihat waktu yang telah berlalu di sisi produsen bursa. Saya telah lama berpandangan bahwa pertukaran harus diwakili oleh dua operator yang berbeda dalam rencana eksekusi. Itu akan mempersulit CXPACKET /CXCONSUMER menunggu analisis jauh lebih diperlukan, dan rencana eksekusi jauh lebih mudah untuk dipahami. Operator produsen pertukaran secara alami akan mendapatkan operator profilnya sendiri.
Desain alternatif
Ada banyak cara SQL Server dapat mencapai kumulatif yang konsisten berlalu dan waktu CPU di seluruh cabang paralel pada prinsipnya . Alih-alih membuat profil operator, setiap baris dapat membawa informasi tentang berapa banyak waktu yang telah berlalu dan waktu CPU yang telah diperoleh sejauh ini dalam perjalanannya melalui rencana. Dengan riwayat yang terkait dengan setiap baris, tidak masalah bagaimana pertukaran mendistribusikan ulang baris di antara utas dan seterusnya.
Itu bukan cara produk dirancang, jadi bukan itu yang kami miliki (dan mungkin juga tidak efisien). Agar adil, desain mode baris asli hanya berkaitan dengan hal-hal seperti mengumpulkan jumlah baris aktual dan jumlah iterasi di setiap operator. Menambahkan waktu berlalu per operator ke rencana adalah fitur yang paling banyak diminta , tetapi tidak mudah untuk memasukkannya ke dalam kerangka kerja yang ada.
Ketika pemrosesan mode batch ditambahkan ke produk, pendekatan yang berbeda (waktu hanya untuk operator saat ini) dapat diimplementasikan sebagai bagian dari pengembangan asli tanpa merusak apa pun. Sekali lagi, pada prinsipnya , operator mode baris dapat dimodifikasi untuk bekerja dengan cara yang sama seperti operator mode batch, tetapi itu akan membutuhkan banyak pekerjaan rekayasa ulang setiap operator mode baris yang ada. Menambahkan titik data baru ke operator profil mode baris yang ada jauh lebih mudah. Mengingat sumber daya teknik yang terbatas, dan daftar panjang peningkatan produk yang diinginkan, kompromi seperti ini sering kali harus dilakukan.
Masalah kedua
Inkonsistensi waktu kumulatif lainnya terjadi pada rencana saat ini di sisi kiri:

Sekilas, ini tampak seperti masalah yang sama:Agregat parsial memiliki waktu berlalu 4.662 detik , tetapi pertukaran di atasnya hanya berjalan selama 2,844 detik . Mekanika dasar yang sama seperti sebelumnya tentu saja sedang dimainkan, tetapi ada faktor penting lainnya. Satu petunjuk terletak pada waktu yang mencurigakan yang dilaporkan untuk agregat aliran, pengurutan, dan pertukaran partisi ulang.
Ingat "penyesuaian waktu" yang saya sebutkan di pendahuluan? Di sinilah mereka masuk. Mari kita lihat masing-masing waktu yang telah berlalu untuk utas di sisi konsumen dari pertukaran aliran partisi ulang:
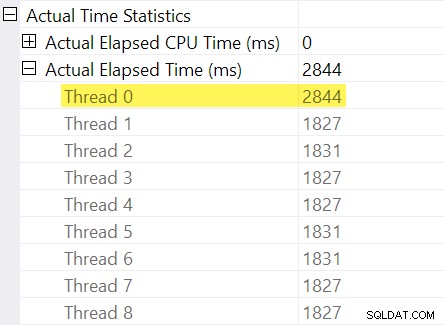
Ingatlah bahwa rencana menunjukkan waktu yang telah berlalu untuk operator paralel sebagai maksimum dari waktu per-utas. Semua 8 utas memiliki waktu yang telah berlalu sekitar 1.830 md tetapi ada entri tambahan untuk "Utas 0" dengan 2.844 md. Memang setiap operator di cabang paralel ini (konsumen pertukaran, pengurutan, dan agregat aliran) memiliki sama Kontribusi 2.844 md dari “Utas 0”.
Thread nol (alias tugas induk atau koordinator) hanya menjalankan operator secara langsung di sebelah kiri operator pengumpulan arus terakhir. Mengapa ada pekerjaan yang ditugaskan di sini, di cabang paralel?
Penjelasan
Masalah ini dapat terjadi ketika ada operator pemblokiran di cabang paralel di bawah (di sebelah kanan) yang sekarang. Tanpa penyesuaian ini, operator di cabang saat ini akan melaporkan kurang dari waktu yang telah berlalu dengan jumlah waktu yang dibutuhkan untuk membuka cabang anak (ada rumit alasan arsitektural untuk ini).
SQL Server memperhitungkan hal ini dengan merekam penundaan cabang anak di bursa di operator pembuatan profil tak terlihat. Nilai waktu dicatat terhadap tugas induk (“Utas 0”) dalam perbedaan antara aktif pertama dan terakhir aktif waktu. (Mungkin tampak aneh untuk mencatat nomor dengan cara ini, tetapi pada saat nomor tersebut perlu dicatat, utas pekerja paralel tambahan belum dibuat).
Dalam kasus saat ini, penyesuaian 2.844 md sebagian besar muncul karena waktu yang dibutuhkan hash join untuk membangun tabel hashnya. (Perhatikan waktu ini berbeda dari total waktu eksekusi gabungan hash, yang mencakup waktu yang dibutuhkan untuk memproses sisi penyelidikan gabungan).
Kebutuhan akan penyesuaian muncul karena hash join memblokir input build-nya. (Menariknya, hash agregat parsial dalam rencana tidak dianggap memblokir dalam konteks ini karena hanya diberikan jumlah memori minimal, tidak pernah tumpah ke tempdb , dan berhenti mengagregasi jika kehabisan memori (sehingga kembali ke mode streaming). Craig Freedman menjelaskan hal ini dalam postingannya, Partial Aggregation).
Mengingat bahwa penyesuaian waktu yang telah berlalu menunjukkan penundaan inisialisasi di cabang anak, SQL Server seharusnya untuk memperlakukan nilai “Utas 0” sebagai offset untuk nomor waktu berlalu per-utas yang diukur dalam cabang saat ini. Mengambil maksimum dari semua utas karena waktu yang telah berlalu adalah wajar secara umum, karena utas cenderung mulai pada waktu yang sama. Itu tidak masuk akal untuk melakukan ini ketika salah satu nilai utas adalah offset untuk semua nilai lainnya!
Kita dapat melakukan perhitungan offset yang benar secara manual menggunakan data yang tersedia dalam rencana. Di sisi konsumen, kami memiliki:
Waktu berlalu maksimum di antara utas pekerja tambahan adalah 1.831 md (tidak termasuk nilai offset yang disimpan di "Utas 0"). Menambahkan offset dari 2.844 md menghasilkan total 4.675 md .
Dalam rencana apa pun dengan waktu per-utas kurang daripada offset, operator akan salah menunjukkan offset sebagai total waktu yang telah berlalu. Hal ini mungkin terjadi ketika operator pemblokiran sebelumnya lambat (mungkin pengurutan atau agregat global pada kumpulan data yang besar) dan operator cabang yang lebih baru memakan waktu lebih sedikit.
Meninjau kembali bagian dari rencana ini:
Mengganti offset 2.844 md yang salah ditetapkan ke aliran partisi ulang, pengurutan, dan operator agregat aliran dengan 4.675 md yang kami hitung value menempatkan waktu kumulatif yang telah berlalu dengan rapi antara 4.662 md pada agregat parsial dan 4.676 md di aliran pengumpulan terakhir. (Pengurutan dan agregat beroperasi pada sejumlah kecil baris sehingga penghitungan waktu yang telah berlalu sama dengan pengurutan, tetapi secara umum sering kali berbeda):

Semua operator dalam fragmen paket di atas memiliki 0 mdtk dari waktu CPU yang telah berlalu di semua utas (selain dari agregat parsial, yang memiliki 14.891 md). Oleh karena itu, rencana dengan nomor yang dihitung kami jauh lebih masuk akal daripada yang ditampilkan:
- 4.675 md – 4.662 md =13 md berlalu adalah jumlah yang jauh lebih masuk akal untuk waktu yang digunakan oleh aliran partisi ulang sendiri . Operator ini tidak menggunakan waktu CPU, dan hanya memproses 524 baris.
- 0 md berlalu (untuk resolusi milidetik) masuk akal untuk kumpulan kecil dan aliran (sekali lagi, tidak termasuk anak-anak mereka).
- 4.676 md – 4.675 md =1 md tampaknya bagus untuk aliran pengumpulan terakhir untuk mengumpulkan 66 baris ke utas tugas induk untuk dikembalikan ke klien.
Selain inkonsistensi yang jelas dalam rencana yang diberikan antara agregat parsial (4.662 md) dan aliran partisi ulang (2.844 md), tidak masuk akal untuk berpikir bahwa aliran pengumpulan akhir dari 66 baris dapat menyebabkan 4.676 md – 2,844 md = 1.832 md dari waktu yang telah berlalu. Angka yang dikoreksi (1 md) jauh lebih akurat, dan tidak akan menyesatkan penyetel kueri.
Sekarang, meskipun penghitungan offset ini dilakukan dengan benar, rencana mode baris paralel mungkin tidak menunjukkan waktu kumulatif yang konsisten dalam semua kasus, untuk alasan yang dibahas sebelumnya. Mencapai konsistensi penuh mungkin sulit, atau bahkan tidak mungkin tanpa perubahan arsitektur besar.
Untuk mengantisipasi pertanyaan yang mungkin muncul pada saat ini:Tidak, analisis pencarian bursa dan indeks sebelumnya tidak melibatkan kesalahan perhitungan offset “Utas 0”. Tidak ada operator pemblokiran di bawah pertukaran itu, jadi tidak ada penundaan inisialisasi yang muncul.
Contoh terakhir
Contoh query berikut ini menggunakan database dan indeks yang sama seperti sebelumnya. Saya tidak akan membahasnya terlalu detail karena hanya berfungsi untuk memperluas poin yang telah saya buat, untuk pembaca yang tertarik.
Fitur dari demo ini adalah:
- Tanpa
ORDER GROUPpetunjuk, ini menunjukkan bagaimana agregat parsial tidak dianggap sebagai operator pemblokiran, jadi tidak ada penyesuaian "Utas 0" yang muncul pada pertukaran aliran partisi ulang. Waktu yang berlalu konsisten. - Dengan petunjuknya, jenis pemblokiran diperkenalkan alih-alih agregat parsial hash. Dua berbeda Penyesuaian "Utas 0" muncul di dua pertukaran partisi ulang. Waktu yang berlalu tidak konsisten di kedua cabang, dengan cara yang berbeda.
Pertanyaan:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Rencana eksekusi tanpa ORDER GROUP (tidak ada penyesuaian, waktu yang konsisten):

Rencana eksekusi dengan ORDER GROUP (dua penyesuaian berbeda, waktu tidak konsisten):

Ringkasan dan kesimpulan
Operator paket mode baris melaporkan kumulatif kali termasuk semua operator anak di utas yang sama. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.