Dalam tip baru-baru ini, saya menjelaskan skenario di mana contoh SQL Server 2016 tampaknya berjuang dengan waktu pos pemeriksaan. Log kesalahan diisi dengan jumlah entri FlushCache yang mengkhawatirkan seperti ini:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Saya agak bingung dengan masalah ini, karena sistemnya jelas tidak bungkuk — banyak inti, memori 3TB, dan penyimpanan XtremIO. Dan tidak satu pun dari pesan FlushCache ini yang pernah dipasangkan dengan tanda peringatan I/O 15 detik di log kesalahan. Namun, jika Anda menumpuk banyak database transaksi tinggi di sana, pemrosesan pos pemeriksaan bisa menjadi sangat lamban. Bukan karena I/O langsung, tetapi lebih banyak rekonsiliasi yang harus dilakukan dengan sejumlah besar halaman kotor (bukan hanya dari komit transaksi) tersebar di sejumlah besar memori, dan berpotensi menunggu di lazywriter (karena hanya ada satu untuk seluruh instance).
Saya melakukan beberapa pembacaan cepat "penyegaran" dari beberapa posting yang sangat berharga:
- Bagaimana cara kerja pos pemeriksaan dan apa yang dicatat
- Poin Pemeriksaan Basis Data (SQL Server)
- Apa gunanya pos pemeriksaan untuk tempdb?
- Mitos SQL Server DBA sehari:(15/30) pos pemeriksaan hanya menulis halaman dari transaksi yang dilakukan
- Pesan FlushCache mungkin bukan kios IO yang sebenarnya
- Pos Pemeriksaan Tidak Langsung dan tempdb – penjadwal yang baik, yang buruk, dan yang tidak memberikan hasil
- Ubah Target Waktu Pemulihan Database
- Cara Kerjanya:Kapan pesan FlushCache ditambahkan ke Log Kesalahan SQL Server?
- Perubahan dalam Perilaku Pos Pemeriksaan SQL Server 2016
- Interval Pemulihan Target dan Pos Pemeriksaan Tidak Langsung – Default Baru 60 Detik di SQL Server 2016
- SQL 2016 – Berjalan Lebih Cepat:Default Pos Pemeriksaan Tidak Langsung
- SQL Server :RAM besar dan Pemeriksaan DB
Saya segera memutuskan bahwa saya ingin melacak durasi pos pemeriksaan untuk beberapa database yang lebih merepotkan ini, sebelum dan sesudah mengubah interval pemulihan target dari 0 (cara lama) menjadi 60 detik (cara baru). Kembali pada bulan Januari, saya meminjam sesi Acara yang Diperpanjang dari teman dan sesama warga Kanada, Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Saya menandai waktu saya mengubah setiap basis data, lalu menganalisis hasil dari data Peristiwa yang Diperpanjang menggunakan kueri yang diterbitkan di tip asli. Hasil menunjukkan bahwa setelah berubah menjadi pos pemeriksaan tidak langsung, setiap database berubah dari pos pemeriksaan rata-rata 30 detik ke pos pemeriksaan rata-rata kurang dari sepersepuluh detik (dan pos pemeriksaan jauh lebih sedikit dalam banyak kasus, juga). Ada banyak hal yang harus dibongkar dari grafik ini, tetapi ini adalah data mentah yang saya gunakan untuk mempresentasikan argumen saya (klik untuk memperbesar):
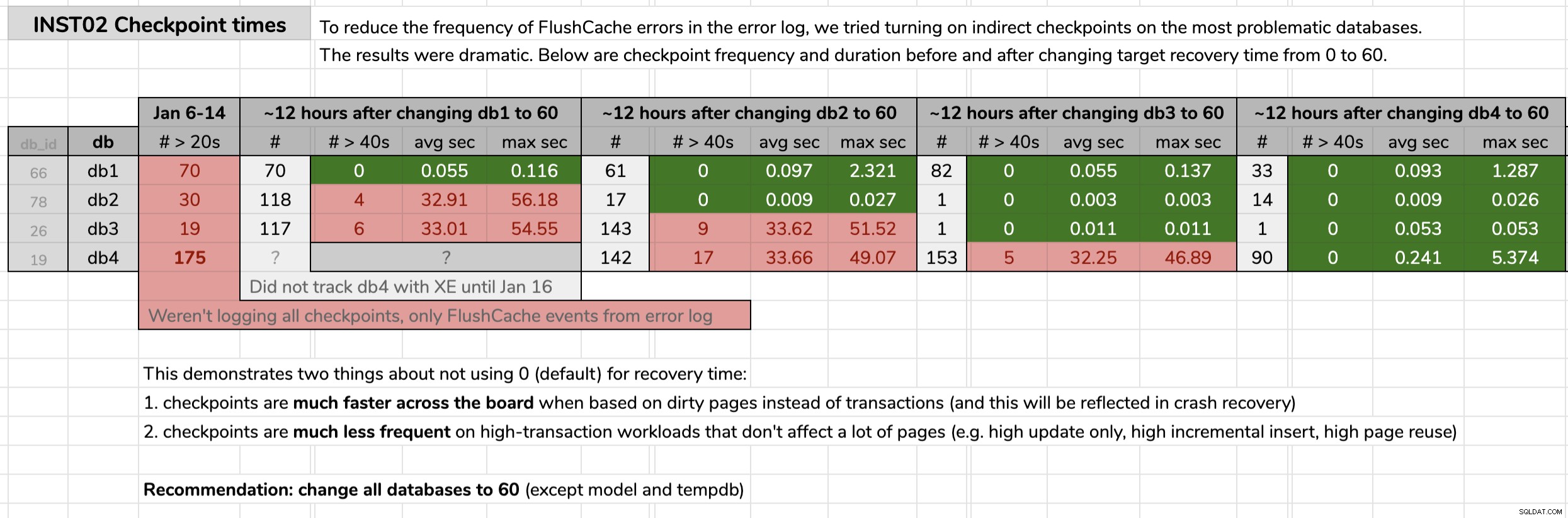 Bukti saya
Bukti saya
Setelah saya membuktikan kasus saya di seluruh database yang bermasalah ini, saya mendapat lampu hijau untuk menerapkan ini di semua database pengguna kami di seluruh lingkungan kami. Di dev terlebih dahulu, lalu di produksi, saya menjalankan yang berikut ini melalui kueri CMS untuk mendapatkan ukuran berapa banyak database yang kita bicarakan:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Beberapa catatan tentang kueri:
database_id > 4
Saya tidak ingin menyentuhmastersama sekali, dan saya tidak ingin mengubahtempdbnamun karena kami tidak menggunakan SQL Server 2017 CU terbaru (lihat KB #4497928 karena satu alasan bahwa detail itu penting). Yang terakhir mengesampingkanmodel, juga, karena mengubah model akan memengaruhitempdbpada failover/restart berikutnya. Saya bisa saja mengubahmsdb, dan saya mungkin akan kembali melakukannya di beberapa titik, tetapi fokus saya di sini adalah pada basis data pengguna.
[state] / is_read_only / is_in_standby
Kita perlu memastikan database yang kita coba ubah online dan tidak hanya bisa dibaca (saya menekan salah satu yang saat ini disetel untuk hanya baca, dan harus kembali lagi nanti).
OUTER APPLY (...)
Kami ingin membatasi tindakan kami ke database yang merupakan yang utama di AG atau tidak sama sekali di AG (dan juga harus memperhitungkan AG terdistribusi, di mana kami bisa menjadi primer dan lokal tetapi masih tidak dapat ditulis) . Jika Anda menjalankan pemeriksaan pada sekunder, Anda tidak dapat memperbaiki masalah di sana, tetapi Anda masih harus mendapatkan peringatan tentang hal itu. Terima kasih kepada Erik Darling untuk membantu dengan logika ini, dan Taylor Martell untuk memotivasi perbaikan.
- Jika Anda memiliki instance yang menjalankan versi lama seperti SQL Server 2008 R2 (saya menemukannya!), Anda harus mengubahnya sedikit, karena
target_recovery_time_in_secondskolom tidak ada di sana. Saya harus menggunakan SQL dinamis untuk menyiasatinya dalam satu kasus, tetapi Anda juga dapat memindahkan atau menghapus sementara instance tersebut dalam hierarki CMS Anda. Anda juga tidak boleh bermalas-malasan seperti saya, dan menjalankan kode di Powershell alih-alih jendela kueri CMS, tempat Anda dapat dengan mudah memfilter basis data yang diberikan sejumlah properti sebelum mencapai masalah waktu kompilasi.
Dalam produksi, ada 102 instance (sekitar setengah) dan 1.590 total database menggunakan pengaturan lama. Semuanya ada di SQL Server 2017, jadi mengapa pengaturan ini begitu umum? Karena dibuat sebelum pos pemeriksaan tidak langsung menjadi default di SQL Server 2016. Berikut adalah contoh hasilnya:
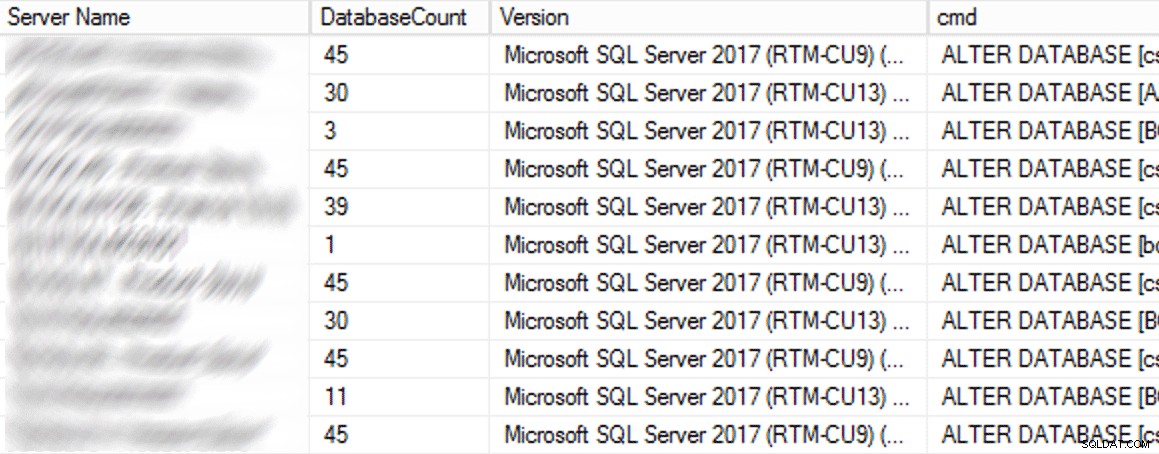 Hasil sebagian dari kueri CMS.
Hasil sebagian dari kueri CMS.
Kemudian saya menjalankan query CMS lagi, kali ini dengan sys.sp_executesql tidak dikomentari. Butuh sekitar 12 menit untuk menjalankannya di seluruh 1.590 basis data. Dalam satu jam, saya sudah mendapatkan laporan tentang orang-orang yang mengamati penurunan CPU yang signifikan pada beberapa instance yang lebih sibuk.
Saya masih memiliki lebih banyak yang harus dilakukan. Misalnya, saya perlu menguji dampak potensial pada tempdb , dan apakah ada bobot dalam kasus penggunaan kami untuk cerita horor yang pernah saya dengar. Dan kami perlu memastikan bahwa pengaturan 60 detik adalah bagian dari otomatisasi kami dan semua permintaan pembuatan basis data, terutama yang dibuat dengan skrip atau dipulihkan dari cadangan.