Saya memiliki banyak percakapan baru-baru ini tentang jenis beban kerja – khususnya memahami apakah beban kerja diparameterisasi, adhoc, atau campuran. Ini adalah salah satu hal yang kami lihat selama audit kesehatan, dan Kimberly memiliki kueri yang bagus dari cache Plan-nya dan mengoptimalkan posting beban kerja adhoc yang merupakan bagian dari toolkit kami. Saya telah menyalin kueri di bawah ini, dan jika Anda belum pernah menjalankannya di lingkungan produksi mana pun sebelumnya, luangkan waktu untuk melakukannya.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Jika saya menjalankan kueri ini terhadap lingkungan produksi, kita mungkin mendapatkan output seperti berikut:
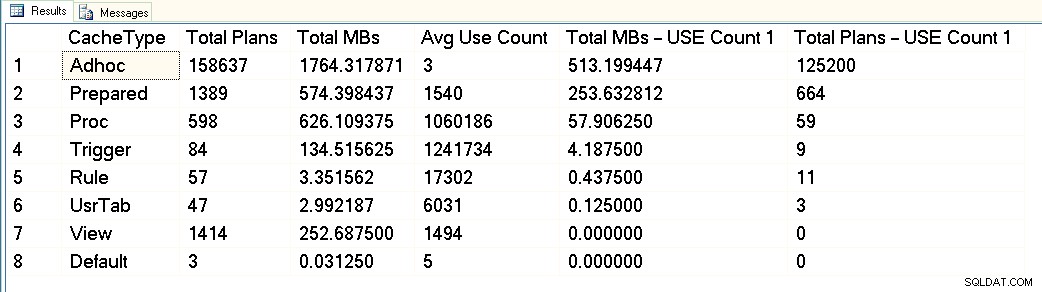
Dari tangkapan layar ini, Anda dapat melihat bahwa kami memiliki total sekitar 3GB yang didedikasikan untuk cache paket, dan 1,7GB dari itu untuk paket lebih dari 158.000 kueri adhoc. Dari 1,7 GB tersebut, sekitar 500 MB digunakan untuk 125.000 paket yang menjalankan SATU waktu saja. Sekitar 1GB dari cache paket adalah untuk paket yang disiapkan dan prosedur, dan mereka hanya menghabiskan ruang sekitar 300MB. Tetapi perhatikan jumlah penggunaan rata-rata – lebih dari 1 juta untuk prosedur. Dalam melihat keluaran ini, saya akan mengkategorikan beban kerja ini sebagai campuran – beberapa kueri berparameter, beberapa adhoc.
Posting blog Kimberly membahas opsi untuk mengelola cache paket yang diisi dengan banyak kueri adhoc. Plan cache bloat hanyalah satu masalah yang harus Anda hadapi ketika Anda memiliki beban kerja adhoc, dan dalam posting ini saya ingin menjelajahi efeknya pada CPU sebagai akibat dari semua kompilasi yang harus terjadi. Saat kueri dijalankan di SQL Server, kueri akan melalui kompilasi dan pengoptimalan, dan ada overhead yang terkait dengan proses ini, yang sering kali bermanifestasi sebagai biaya CPU. Setelah paket kueri disimpan dalam cache, paket tersebut dapat digunakan kembali. Kueri yang diparameterisasi akhirnya dapat menggunakan kembali paket yang sudah ada di cache, karena teks kuerinya persis sama. Saat kueri adhoc dijalankan, ia hanya akan menggunakan kembali paket dalam cache jika memiliki tepat teks dan nilai masukan yang sama .
Penyiapan
Untuk pengujian kami, kami akan menghasilkan string acak di TSQL dan menggabungkannya ke kueri sehingga setiap eksekusi memiliki nilai literal yang berbeda. Saya telah membungkus ini dalam prosedur tersimpan yang memanggil kueri menggunakan Dynamic String Execution (EXEC @QueryString), sehingga berperilaku seperti pernyataan adhoc. Memanggilnya dari dalam prosedur tersimpan berarti kita dapat mengeksekusinya beberapa kali.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
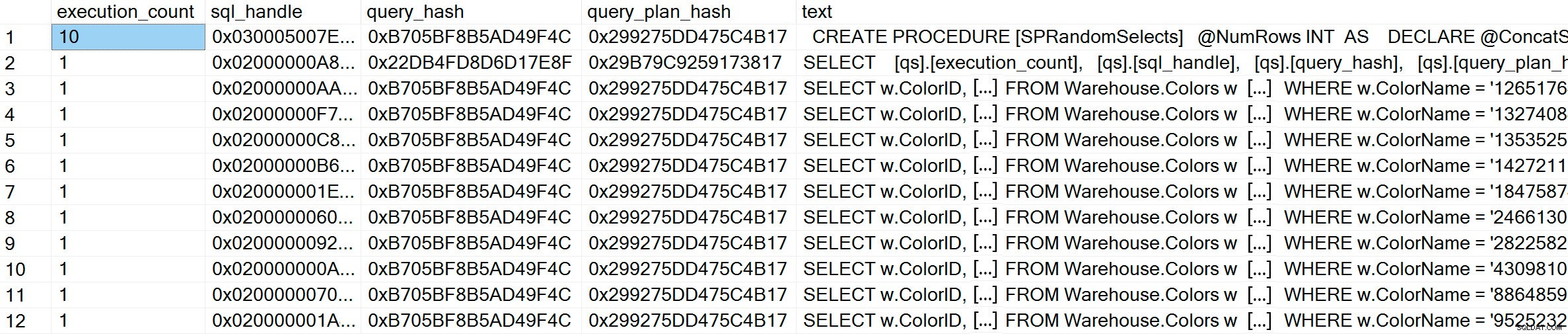
GO Setelah dijalankan, jika kita memeriksa cache rencana, kita dapat melihat bahwa kita memiliki 10 entri unik, masing-masing dengan execution_count 1 (perbesar gambar jika perlu untuk melihat nilai unik untuk predikat):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Sekarang kita membuat prosedur tersimpan yang hampir identik yang mengeksekusi kueri yang sama, tetapi berparameter:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO Di dalam cache rencana, selain 10 kueri adhoc, kami melihat satu entri untuk kueri berparameter yang telah dijalankan 10 kali. Karena input diparameterisasi, bahkan jika string yang sangat berbeda dilewatkan ke dalam parameter, teks kueri sama persis:
Pengujian
Sekarang setelah kita memahami apa yang terjadi di cache rencana, mari buat lebih banyak beban. Kami akan menggunakan file baris perintah yang memanggil file .sql yang sama pada 10 utas berbeda, dengan setiap file memanggil prosedur tersimpan 10.000 kali. Kami akan mengosongkan cache paket sebelum memulai, dan merekam Total CPU% dan SQL Compilations/sec dengan PerfMon saat skrip dijalankan.
Isi file Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Isi file parameterized.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Contoh file perintah (dilihat di Notepad) yang memanggil file .sql:
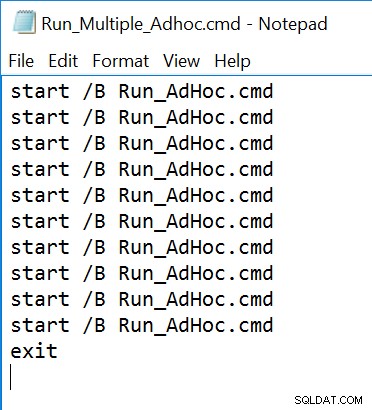
Contoh file perintah (dilihat di Notepad) yang membuat 10 utas, masing-masing memanggil file Run_Adhoc.cmd:
Setelah menjalankan setiap kumpulan kueri sebanyak 100.000 kali, jika kita melihat cache paket, kita akan melihat yang berikut:

Ada lebih dari 10.000 paket adhoc dalam cache paket. Anda mungkin bertanya-tanya mengapa tidak ada rencana untuk semua 100.000 kueri adhoc yang dijalankan, dan ini ada hubungannya dengan cara kerja cache rencana (ukurannya berdasarkan memori yang tersedia, ketika paket yang tidak digunakan sudah usang, dll.). Yang penting adalah begitu banyak paket adhoc yang ada, dibandingkan dengan apa yang kita lihat untuk jenis cache lainnya.
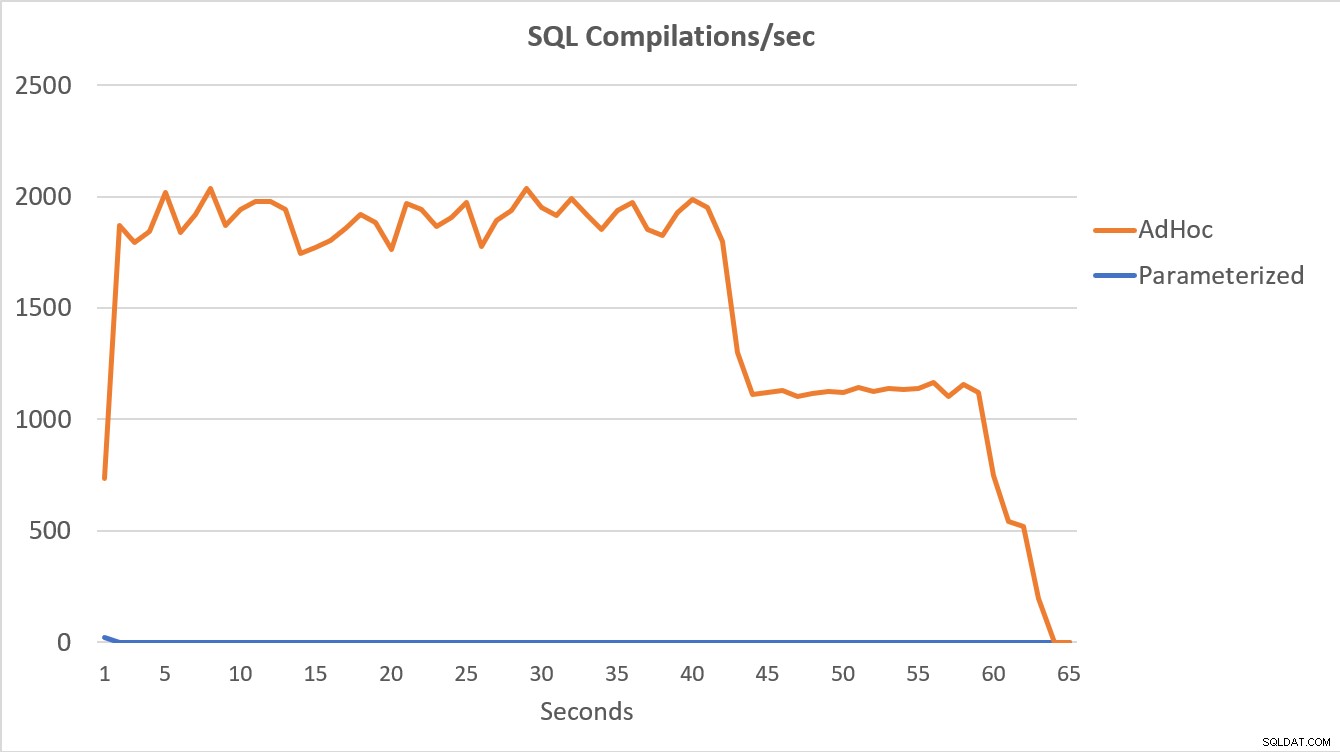
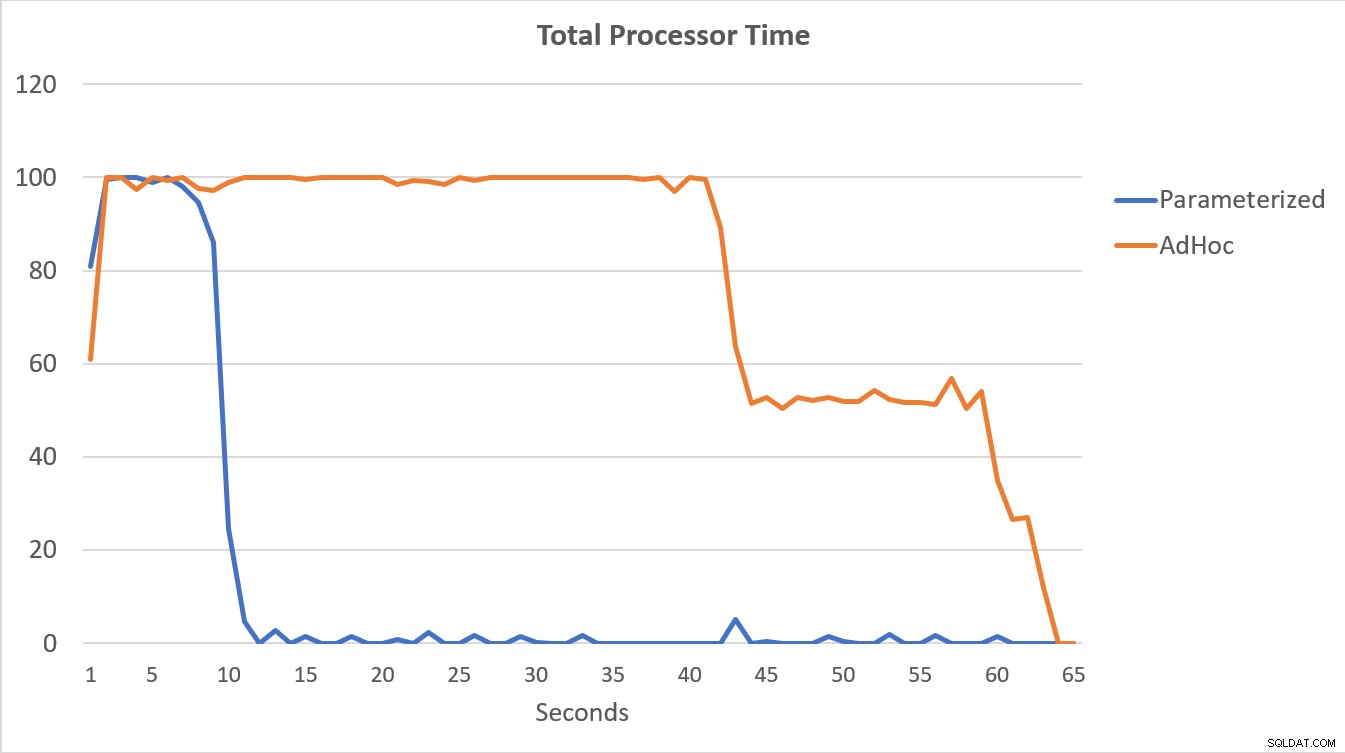
Data PerfMon, dalam grafik di bawah, paling jitu. Eksekusi 100.000 kueri berparameter selesai dalam waktu kurang dari 15 detik, dan ada lonjakan kecil dalam Kompilasi/dtk di awal, yang hampir tidak terlihat pada grafik. Jumlah eksekusi adhoc yang sama membutuhkan waktu lebih dari 60 detik untuk diselesaikan, dengan Compilations/dtk melonjak mendekati 2000 sebelum turun mendekati 1000 sekitar 45 detik, dengan CPU mendekati atau 100% untuk sebagian besar waktu.
Ringkasan
Pengujian kami sangat sederhana karena kami hanya mengirimkan variasi untuk satu kueri adhoc, sedangkan dalam lingkungan produksi, kita dapat memiliki ratusan atau ribuan variasi berbeda untuk ratusan atau ribuan query adhoc yang berbeda. Dampak kinerja dari kueri adhoc ini bukan hanya pengasapan cache paket yang terjadi, meskipun melihat cache paket adalah tempat yang bagus untuk memulai jika Anda tidak terbiasa dengan jenis beban kerja yang Anda miliki. Kueri adhoc dalam jumlah besar dapat mendorong kompilasi dan oleh karena itu CPU, yang terkadang dapat ditutup-tutupi dengan menambahkan lebih banyak perangkat keras, tetapi pasti ada titik di mana CPU menjadi hambatan. Jika menurut Anda ini mungkin merupakan masalah, atau potensi masalah, di lingkungan Anda, maka carilah untuk mengidentifikasi kueri adhoc mana yang paling sering berjalan, dan lihat opsi apa yang Anda miliki untuk membuat parameternya. Jangan salah paham – ada potensi masalah dengan kueri berparameter (mis. stabilitas rencana karena kemiringan data), dan itu masalah lain yang mungkin harus Anda selesaikan. Terlepas dari beban kerja Anda, penting untuk dipahami bahwa jarang ada metode "setel dan lupakan" untuk pengkodean, konfigurasi, pemeliharaan, dll. Solusi SQL Server adalah entitas yang hidup dan bernafas yang selalu berubah dan terus-menerus menjaga dan memberi makan ke melakukan dengan andal. Salah satu tugas DBA adalah terus mengikuti perubahan itu dan mengelola kinerja sebaik mungkin – baik itu terkait dengan tantangan kinerja adhoc atau parameter.