Pada PASS Summit beberapa minggu yang lalu, Microsoft merilis CTP2.1 SQL Server 2019, dan salah satu peningkatan fitur besar yang disertakan dalam CTP adalah Scalar UDF Inlining. Sebelum rilis ini saya ingin bermain-main dengan perbedaan kinerja antara inlining UDF skalar dan eksekusi RBAR (baris demi baris) dari UDF skalar di versi SQL Server sebelumnya dan saya menemukan opsi sintaks untuk BUAT FUNGSI pernyataan di SQL Server Books Online yang belum pernah saya lihat sebelumnya.
DDL untuk BUAT FUNGSI mendukung klausa WITH untuk opsi fungsi dan saat membaca Buku Daring, saya perhatikan bahwa sintaksnya menyertakan yang berikut:
-- Klausul Fungsi Transact-SQL::= { [ ENKRIPSI ] | [ SKEMABINDING ] | [ MENGEMBALIKAN NULL PADA INPUT NULL | DIHUBUNGI PADA INPUT NULL ] | [ EXECUTE_AS_Clause ] }
Saya sangat penasaran dengan RETURNS NULL ON NULL INPUT opsi fungsi jadi saya memutuskan untuk melakukan beberapa pengujian. Saya sangat terkejut mengetahui bahwa ini sebenarnya adalah bentuk pengoptimalan UDF skalar yang telah ada di produk setidaknya sejak SQL Server 2008 R2.
Ternyata jika Anda tahu bahwa skalar UDF akan selalu mengembalikan hasil NULL ketika input NULL diberikan maka UDF harus SELALU dibuat dengan RETURNS NULL ON NULL INPUT pilihan, karena SQL Server bahkan tidak menjalankan definisi fungsi sama sekali untuk setiap baris di mana inputnya adalah NULL – hubungan arus pendek berlaku dan menghindari eksekusi yang sia-sia dari badan fungsi.
Untuk menunjukkan perilaku ini, saya akan menggunakan contoh SQL Server 2017 dengan Pembaruan Kumulatif terbaru yang diterapkan padanya dan AdventureWorks2017 database dari GitHub (Anda dapat mengunduhnya dari sini) yang dikirimkan dengan dbo.ufnLeadingZeros fungsi yang hanya menambahkan nol di depan ke nilai input dan mengembalikan delapan karakter string yang menyertakan nol di depan itu. Saya akan membuat versi baru dari fungsi itu yang menyertakan RETURNS NULL ON NULL INPUT sehingga saya dapat membandingkannya dengan fungsi asli untuk kinerja eksekusi.
GUNAKAN [AdventureWorks2017];GO CREATE FUNCTION [dbo].[ufnLeadingZeros_new]( @Value int ) RETURNS varchar(8) WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT AS BEGIN DECLARE @ReturnVal8); SET @ReturnValue =CONVERT(varchar(8), @Value); SET @ReturnValue =REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue; RETURN (@ReturnValue); AKHIR; PERGI Untuk tujuan menguji perbedaan kinerja eksekusi dalam mesin database dari dua fungsi, saya memutuskan untuk membuat sesi Acara yang Diperpanjang di server untuk melacak sqlserver.module_end event, yang diaktifkan pada akhir setiap eksekusi skalar UDF untuk setiap baris. Ini memungkinkan saya mendemonstrasikan semantik pemrosesan baris demi baris, dan juga membiarkan saya melacak berapa kali fungsi tersebut benar-benar dipanggil selama pengujian. Saya memutuskan untuk juga mengumpulkan sql_batch_completed dan sql_statement_completed acara dan filter semuanya dengan session_id untuk memastikan bahwa saya hanya menangkap informasi yang terkait dengan sesi tempat saya benar-benar menjalankan tes (jika Anda ingin mereplikasi hasil ini, Anda harus mengubah 74 di semua tempat dalam kode di bawah ini ke ID sesi apa pun yang Anda uji kode akan dijalankan). Sesi acara menggunakan TRACK_CAUSALITY sehingga mudah untuk menghitung berapa banyak eksekusi fungsi yang terjadi melalui activity_id.seq_no nilai untuk peristiwa (yang meningkat satu untuk setiap peristiwa yang memenuhi session_id filter).
BUAT SESI ACARA [Session72] PADA SERVER ADD EVENT sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_completed( WHERE ( WHERE) [package0].[equal_uint64]([sqlserver].[session_id],(74)))) ADD EVENT sqlserver.sql_batch_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74) ))), ADD EVENT sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_starting( WHERE ([package0].[equal_uint64] ([sqlserver].[session_id],(74)))) WITH (TRACK_CAUSALITY=ON) GO
Setelah saya memulai sesi acara dan membuka Live Data Viewer di Management Studio, saya menjalankan dua kueri; yang menggunakan versi asli dari fungsi tersebut untuk memasukkan angka nol ke CurrencyRateID kolom di Sales.SalesOrderHeader tabel, dan fungsi baru untuk menghasilkan output yang identik tetapi menggunakan RETURNS NULL ON NULL INPUT opsi, dan saya menangkap informasi Rencana Eksekusi Aktual untuk perbandingan.
PILIH SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) DARI Sales.SalesOrderHeader; PERGI PILIH SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) DARI Sales.SalesOrderHeader; PERGI
Meninjau data Extended Events menunjukkan beberapa hal menarik. Pertama, fungsi aslinya berjalan 31.465 kali (dari hitungan module_end peristiwa) dan total waktu CPU untuk sql_statement_completed acara adalah 204 md dengan durasi 482 md.
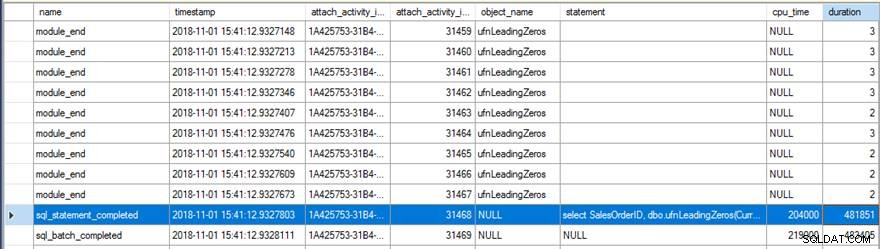
Versi baru dengan RETURNS NULL ON NULL INPUT opsi yang ditentukan hanya berjalan 13.976 kali (sekali lagi, dari hitungan module_end event) dan waktu CPU untuk sql_statement_completed acara adalah 78 md dengan durasi 359 md.

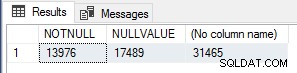
Saya menemukan ini menarik sehingga untuk memverifikasi jumlah eksekusi saya menjalankan kueri berikut untuk menghitung NOT NULL baris nilai, baris nilai NULL, dan baris total di Sales.SalesOrderHeader tabel.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, ROM
Angka-angka ini sama persis dengan jumlah module_end peristiwa untuk setiap pengujian, jadi ini jelas merupakan pengoptimalan kinerja yang sangat sederhana untuk UDF skalar yang harus digunakan jika Anda tahu bahwa hasil fungsi akan NULL jika nilai inputnya NULL, untuk hubung singkat/memotong eksekusi fungsi sepenuhnya untuk baris tersebut.
Informasi QueryTimeStats dalam Rencana Eksekusi Aktual juga mencerminkan peningkatan kinerja:
Ini adalah pengurangan yang cukup signifikan dalam waktu CPU saja, yang dapat menjadi masalah yang signifikan untuk beberapa sistem.
Penggunaan UDF skalar adalah anti-pola desain yang terkenal untuk kinerja dan ada berbagai metode untuk menulis ulang kode untuk menghindari penggunaan dan kinerjanya. Tetapi jika sudah ada dan tidak dapat dengan mudah diubah atau dihapus, cukup buat ulang UDF dengan RETURNS NULL ON NULL INPUT opsi bisa menjadi cara yang sangat sederhana untuk meningkatkan kinerja jika ada banyak masukan NULL di seluruh kumpulan data tempat UDF digunakan.