Artikel ini menunjukkan bagaimana SQL Server menggabungkan informasi kepadatan dari beberapa statistik kolom tunggal, untuk menghasilkan perkiraan kardinalitas untuk agregasi pada beberapa kolom. Detailnya mudah-mudahan menarik dalam diri mereka. Mereka juga memberikan wawasan tentang beberapa pendekatan umum dan algoritme yang digunakan oleh penduga kardinalitas.
Pertimbangkan contoh kueri database AdventureWorks berikut, yang mencantumkan jumlah item inventaris produk di setiap nampan di setiap rak di gudang:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Perkiraan rencana eksekusi menunjukkan 1.069 baris sedang dibaca dari tabel, diurutkan ke dalam Shelf dan Bin pesanan, lalu digabungkan menggunakan operator Agregat Aliran:
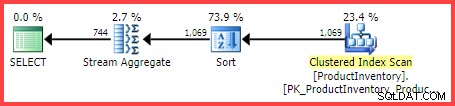
Perkiraan Rencana Eksekusi
Pertanyaannya adalah, bagaimana pengoptimal kueri SQL Server sampai pada perkiraan akhir 744 baris?
Statistik yang Tersedia
Saat mengkompilasi kueri di atas, pengoptimal kueri akan membuat statistik satu kolom di Shelf dan Bin kolom, jika statistik yang sesuai belum ada. Antara lain, statistik ini memberikan informasi tentang jumlah nilai kolom yang berbeda (dalam vektor kepadatan):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Hasilnya dirangkum dalam tabel di bawah ini (kolom ketiga dihitung dari kepadatan):
| Kolom | Kepadatan | 1 / Kepadatan |
|---|---|---|
| Rak | 0,04761905 | 21 |
| Sampah | 0.01612903 | 62 |
Informasi vektor kepadatan Rak dan Bak
Sebagai catatan dokumentasi, kebalikan dari kepadatan adalah jumlah nilai yang berbeda dalam kolom. Dari informasi statistik yang ditunjukkan di atas, SQL Server mengetahui bahwa ada 21 Shelf distinct yang berbeda nilai dan 62 Bin distinct yang berbeda nilai dalam tabel, saat statistik dikumpulkan.
Tugas memperkirakan jumlah baris yang dihasilkan oleh GROUP BY klausa sepele ketika hanya satu kolom yang terlibat (dengan asumsi tidak ada predikat lain). Misalnya, mudah untuk melihat bahwa GROUP BY Shelf akan menghasilkan 21 baris; GROUP BY Bin akan menghasilkan 62.
Namun, tidak segera jelas bagaimana SQL Server dapat memperkirakan jumlah (Shelf, Bin) yang berbeda kombinasi untuk GROUP BY Shelf, Bin kami pertanyaan. Untuk mengajukan pertanyaan dengan cara yang sedikit berbeda:Diberikan 21 rak dan 62 tempat sampah, berapa banyak kombinasi rak dan tempat sampah unik yang akan ada? Mengesampingkan aspek fisik dan pengetahuan manusia lainnya tentang domain masalah, jawabannya bisa di mana saja dari maks (21, 62) =62 hingga (21 * 62) =1,302. Tanpa informasi lebih lanjut, tidak ada cara yang jelas untuk mengetahui di mana harus memberikan perkiraan dalam kisaran tersebut.
Namun, untuk kueri contoh kami, SQL Server memperkirakan 744.312 baris (dibulatkan menjadi 744 dalam tampilan Plan Explorer) tetapi atas dasar apa?
Peristiwa Perpanjangan Estimasi Kardinalitas
Cara terdokumentasi untuk melihat proses estimasi kardinalitas adalah dengan menggunakan Peristiwa Diperpanjang query_optimizer_estimate_cardinality (meskipun berada di saluran "debug"). Saat sesi yang mengumpulkan acara ini berjalan, operator rencana eksekusi mendapatkan properti tambahan StatsCollectionId yang menghubungkan perkiraan operator individu dengan perhitungan yang menghasilkannya. Untuk contoh kueri kami, pengumpulan statistik id 2 ditautkan ke perkiraan kardinalitas untuk grup menurut operator agregat.
Output yang relevan dari Extended Event untuk kueri pengujian kami adalah:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Pasti ada beberapa informasi berguna di sana.
Kita dapat melihat bahwa plan meninggalkan kelas kalkulator nilai yang berbeda (CDVCPlanLeaf ) digunakan, menggunakan statistik kolom tunggal pada Shelf dan Bin sebagai masukan. Elemen kumpulan statistik mencocokkan fragmen ini dengan id (2) yang ditampilkan dalam rencana eksekusi, yang menunjukkan perkiraan kardinalitas 744,31 , dan informasi lebih lanjut tentang id objek statistik yang digunakan juga.
Sayangnya, tidak ada dalam output acara yang mengatakan dengan tepat bagaimana kalkulator sampai pada angka akhir, yang merupakan hal yang sangat kami minati.
Menggabungkan jumlah yang berbeda
Pergi ke rute yang kurang terdokumentasi, kami dapat meminta perkiraan rencana untuk kueri dengan tanda jejak 2363 dan 3604 diaktifkan:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Ini mengembalikan informasi debug ke tab Pesan di SQL Server Management Studio. Bagian yang menarik direproduksi di bawah ini:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Ini menunjukkan banyak informasi yang sama seperti yang dilakukan Acara yang Diperpanjang dalam format yang (bisa dibilang) lebih mudah digunakan:
- Operator relasional input untuk menghitung perkiraan kardinalitas untuk (
LogOp_GbAgg– kelompok logis berdasarkan agregat) - Kalkulator yang digunakan (
CDVCPlanLeaf) dan memasukkan statistik - Detail pengumpulan statistik yang dihasilkan
Informasi baru yang menarik adalah bagian tentang menggunakan kardinalitas ambient untuk menggabungkan hitungan yang berbeda .
Ini dengan jelas menunjukkan bahwa nilai 21, 62, dan 1069 digunakan, tetapi (dengan frustrasi) masih belum tepat perhitungan mana yang dilakukan untuk sampai pada 744.312 hasil.
Untuk Sang Debugger!
Melampirkan debugger dan menggunakan simbol publik memungkinkan kita untuk menjelajahi secara detail jalur kode yang diikuti saat mengompilasi kueri contoh.
Snapshot di bawah ini menunjukkan bagian atas tumpukan panggilan pada titik representatif dalam proses:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Ada beberapa detail menarik di sini. Bekerja dari bawah ke atas, kita melihat bahwa kardinalitas diturunkan menggunakan CE yang diperbarui (CCardFrameworkSQL12 ) tersedia di SQL Server 2014 dan yang lebih baru (CE asli adalah CCardFrameworkSQL7 ), untuk grup menurut operator logika agregat (CLogOp_GbAgg ).
Menghitung kardinalitas yang berbeda melibatkan penggabungan (munging) beberapa input, menggunakan pengambilan sampel tanpa penggantian.
Referensi ke H dan logaritma (alami) pada metode kedua dari atas menunjukkan penggunaan Shannon Entropy dalam perhitungan:
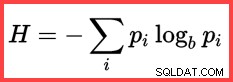
Entropi Shannon
Entropi dapat digunakan untuk memperkirakan korelasi informasional (informasi timbal balik) antara dua statistik:
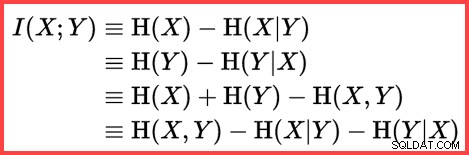
Informasi Bersama
Menyatukan semua ini, kita dapat membuat skrip perhitungan T-SQL yang cocok dengan cara SQL Server menggunakan pengambilan sampel tanpa penggantian, Shannon Entropy, dan informasi bersama untuk menghasilkan perkiraan kardinalitas akhir.
Kita mulai dengan angka input (kardinalitas ambient dan jumlah nilai yang berbeda di setiap kolom):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; Frekuensi dari setiap kolom adalah jumlah rata-rata baris per nilai yang berbeda:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Pengambilan sampel tanpa penggantian (SWR) adalah masalah sederhana dengan mengurangi jumlah rata-rata baris per nilai (frekuensi) yang berbeda dari jumlah total baris:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Hitung entropi (N log N) dan informasi timbal balik:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Sekarang kita telah memperkirakan seberapa berkorelasi dua set statistik, kita dapat menghitung perkiraan akhir:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Hasil perhitungannya adalah 744.311823994677, yaitu 744.312 dibulatkan menjadi tiga tempat desimal.
Untuk kenyamanan, berikut adalah seluruh kode dalam satu blok:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Pemikiran Terakhir
Perkiraan akhir tidak sempurna dalam kasus ini – kueri contoh sebenarnya mengembalikan 441 baris.
Untuk mendapatkan perkiraan yang lebih baik, kami dapat memberikan informasi yang lebih baik kepada pengoptimal tentang kepadatan Bin dan Shelf kolom menggunakan statistik multikolom. Misalnya:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Dengan statistik itu (baik seperti yang diberikan, atau sebagai efek samping dari penambahan indeks multikolom yang serupa), perkiraan kardinalitas untuk kueri contoh tepat. Jarang sekali menghitung agregasi sederhana seperti itu. Dengan predikat tambahan, statistik multicolumn mungkin kurang efektif. Namun demikian, penting untuk diingat bahwa informasi kepadatan tambahan yang disediakan oleh statistik multikolom dapat berguna untuk agregasi (serta perbandingan kesetaraan).
Tanpa statistik multikolom, kueri agregat dengan predikat tambahan mungkin masih dapat menggunakan logika penting yang ditampilkan dalam artikel ini. Misalnya, alih-alih menerapkan rumus ke kardinalitas tabel, rumus ini dapat diterapkan ke histogram masukan langkah demi langkah.
Konten terkait:Estimasi Kardinalitas untuk Predikat pada COUNT Ekspresi