Penulis Tamu :Monica Rathbun (@SQLEspresso)
Terkadang masalah kinerja perangkat keras, seperti latensi Disk I/O, bermuara pada beban kerja yang tidak dioptimalkan daripada perangkat keras yang berkinerja buruk. Banyak Admin Database, termasuk saya, ingin segera menyalahkan penyimpanan atas kelambatannya. Sebelum Anda pergi dan menghabiskan banyak uang untuk perangkat keras baru, Anda harus selalu memeriksa beban kerja Anda untuk I/O yang tidak perlu.
Hal yang Perlu Diperiksa
Indeks yang Tidak Digunakan
Kita semua tahu kekuatan indeks. Memiliki indeks yang tepat dapat membuat perbedaan dalam kecepatan kueri selama bertahun-tahun. Namun, berapa banyak dari kita yang terus-menerus mempertahankan indeks kita di atas dan di luar pembangunan kembali indeks dan penataan ulang? Sangat penting untuk menjalankan skrip indeks secara teratur untuk mengevaluasi indeks mana yang benar-benar digunakan. Saya pribadi menggunakan kueri diagnostik Glenn Berry untuk melakukan ini.
Anda akan terkejut menemukan bahwa beberapa indeks Anda belum dibaca sama sekali. Indeks ini membebani sumber daya, terutama pada tabel yang sangat transaksional. Saat melihat hasilnya, perhatikan indeks yang memiliki jumlah penulisan yang tinggi dikombinasikan dengan jumlah pembacaan yang rendah. Dalam contoh ini, Anda dapat melihat saya membuang-buang waktu menulis. Indeks non-clustered telah ditulis hingga 11 juta kali, tetapi hanya dibaca dua kali.

Saya mulai dengan menonaktifkan indeks yang termasuk dalam kategori ini, dan kemudian menghapusnya setelah saya memastikan tidak ada masalah yang muncul. Melakukan latihan ini secara rutin dapat sangat mengurangi penulisan I/O yang tidak perlu ke sistem Anda, tetapi perlu diingat statistik penggunaan pada indeks Anda hanya sebaik reboot terakhir, jadi pastikan Anda telah mengumpulkan data untuk siklus bisnis penuh sebelum menghapus indeks sebagai "tidak berguna."
Indeks Tidak Ada
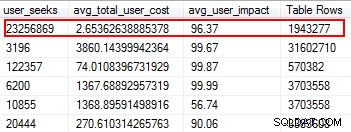
Indeks yang Hilang adalah salah satu hal termudah untuk diperbaiki; lagi pula, ketika Anda menjalankan rencana eksekusi, itu akan memberi tahu Anda jika ada indeks yang tidak ditemukan tetapi itu akan berguna. Tapi tunggu dulu, saya harap Anda tidak sembarangan menambahkan indeks berdasarkan saran ini. Melakukan hal ini dapat membuat indeks duplikat, dan indeks yang mungkin memiliki penggunaan minimal, dan karenanya membuang-buang I/O. Sekali lagi, kembali ke skrip Glenn, dia memberi kita alat yang hebat untuk mengevaluasi kegunaan indeks dengan menyediakan pencarian pengguna, dampak pengguna, dan jumlah baris. Perhatikan mereka dengan bacaan tinggi bersama dengan biaya dan dampak rendah. Ini adalah tempat yang bagus untuk memulai, dan akan membantu Anda mengurangi I/O baca.
Konversi Tersirat
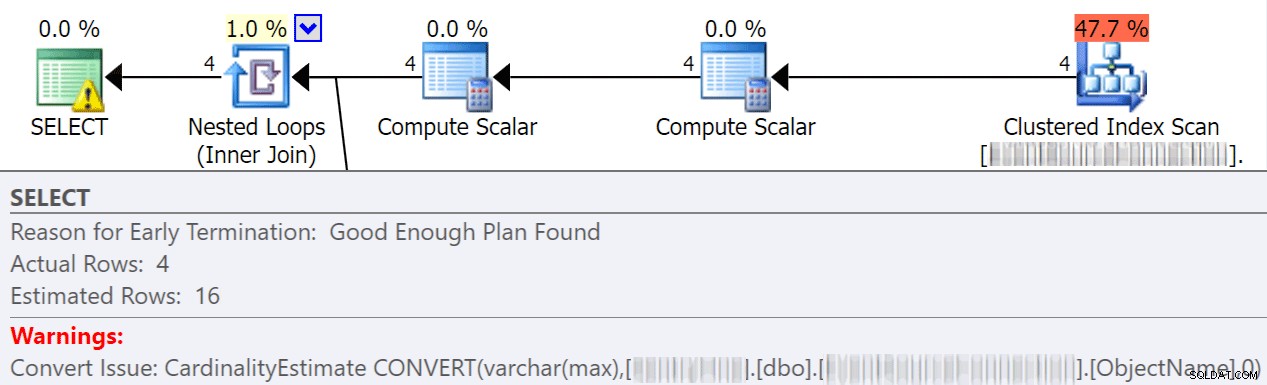
Konversi implisit sering terjadi saat kueri membandingkan dua kolom atau lebih dengan tipe data yang berbeda. Dalam contoh di bawah ini, sistem harus melakukan I/O ekstra untuk membandingkan kolom varchar(maks) dengan kolom nvarchar(4000), yang mengarah ke konversi implisit, dan akhirnya pemindaian alih-alih pencarian. Dengan memperbaiki tabel agar memiliki tipe data yang cocok, atau hanya mengonversi nilai ini sebelum evaluasi, Anda dapat sangat mengurangi I/O dan meningkatkan kardinalitas (perkiraan baris yang diharapkan oleh pengoptimal).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias merinci lebih banyak dalam pos yang bagus ini:" Seberapa mahalkah Konversi Implisit sisi kolom?"
Fungsi
Salah satu hal yang paling dapat dihindari dan mudah diperbaiki yang pernah saya temui yang menghemat biaya I/O adalah menghapus fungsi dari klausa where. Contoh sempurna adalah perbandingan tanggal, seperti yang ditunjukkan di bawah ini.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Apakah itu pada pernyataan GABUNG atau dalam klausa WHERE ini menyebabkan setiap kolom dikonversi sebelum dievaluasi. Dengan hanya mengubah kolom ini sebelum evaluasi menjadi tabel sementara, Anda dapat menghilangkan banyak I/O yang tidak perlu.
Atau, lebih baik lagi, jangan lakukan konversi sama sekali (untuk kasus khusus ini, Aaron Bertrand berbicara di sini tentang menghindari fungsi dalam klausa where, dan perhatikan bahwa ini masih bisa buruk meskipun convert to date adalah sargable).
ETL
Luangkan waktu untuk memeriksa bagaimana data Anda dimuat. Apakah Anda memotong dan memuat ulang tabel? Bisakah Anda menerapkan Replikasi, Replika AG hanya baca, atau pengiriman log sebagai gantinya? Apakah semua tabel sedang ditulis untuk benar-benar dibaca? Bagaimana Anda memuat data? Apakah melalui prosedur tersimpan atau SSIS? Meneliti hal-hal seperti ini dapat mengurangi I/O secara dramatis.
Di lingkungan saya, saya menemukan bahwa kami memotong 48 tabel setiap hari dengan lebih dari 120 juta baris setiap pagi. Selain itu, kami memuat 9,6 juta baris setiap jam. Bisa dibayangkan betapa tidak perlunya I/O yang dibuat. Dalam kasus saya, menerapkan replikasi transaksional adalah solusi pilihan saya. Setelah diterapkan, kami memiliki jauh lebih sedikit keluhan pengguna tentang pelambatan selama waktu muat kami, yang awalnya dikaitkan dengan penyimpanan yang lambat.
Pesan Berdasarkan &Kelompokkan Menurut
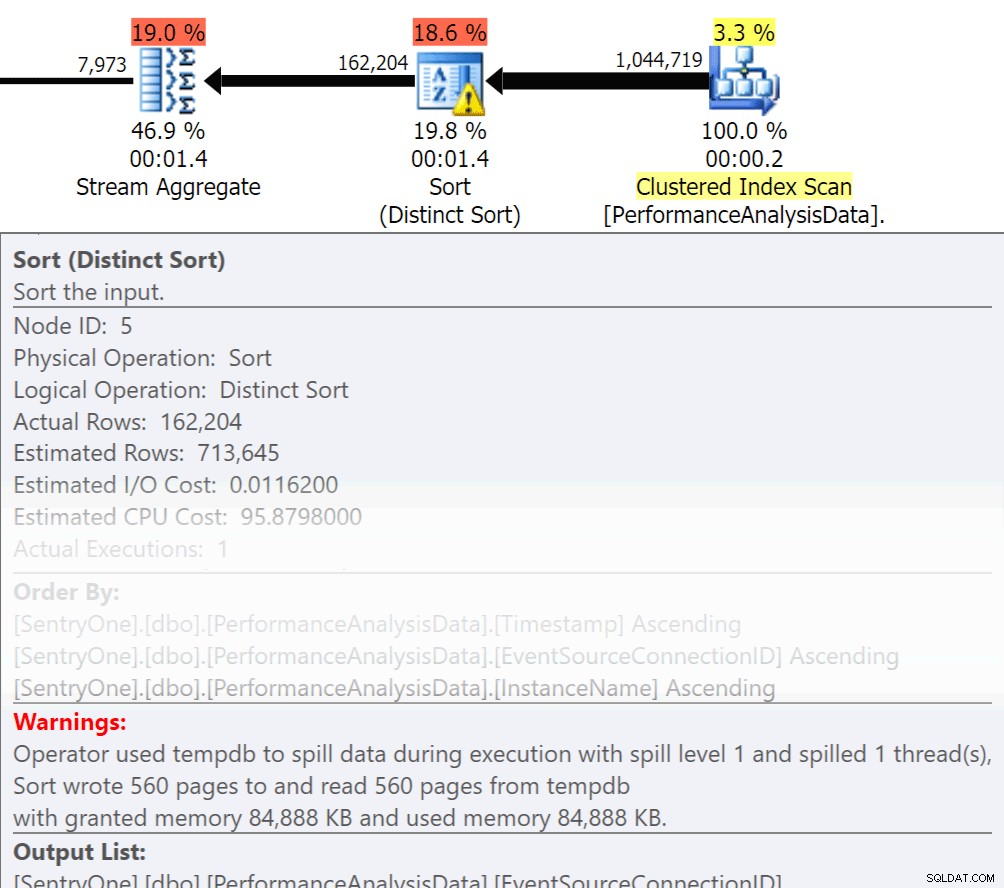 Tanyakan pada diri sendiri, apakah data itu harus dikembalikan secara berurutan? Apakah kita benar-benar perlu mengelompokkan dalam prosedur, atau dapatkah kita menanganinya dalam laporan atau aplikasi? Operasi Order By dan Group By dapat menyebabkan pembacaan tumpah ke disk, yang menyebabkan I/O disk tambahan. Jika tindakan ini diperlukan, pastikan Anda memiliki indeks pendukung dan statistik baru pada kolom yang sedang diurutkan atau dikelompokkan. Ini akan membantu pengoptimal selama pembuatan rencana. Karena kami terkadang menggunakan Order By dan Group By di tabel temp. pastikan Anda memiliki Auto Create Statistics On untuk TEMPDB serta database pengguna Anda. Semakin mutakhir statistiknya, semakin baik kardinalitas yang dapat diperoleh pengoptimal, menghasilkan rencana yang lebih baik, lebih sedikit tumpahan, dan lebih sedikit I/O.
Tanyakan pada diri sendiri, apakah data itu harus dikembalikan secara berurutan? Apakah kita benar-benar perlu mengelompokkan dalam prosedur, atau dapatkah kita menanganinya dalam laporan atau aplikasi? Operasi Order By dan Group By dapat menyebabkan pembacaan tumpah ke disk, yang menyebabkan I/O disk tambahan. Jika tindakan ini diperlukan, pastikan Anda memiliki indeks pendukung dan statistik baru pada kolom yang sedang diurutkan atau dikelompokkan. Ini akan membantu pengoptimal selama pembuatan rencana. Karena kami terkadang menggunakan Order By dan Group By di tabel temp. pastikan Anda memiliki Auto Create Statistics On untuk TEMPDB serta database pengguna Anda. Semakin mutakhir statistiknya, semakin baik kardinalitas yang dapat diperoleh pengoptimal, menghasilkan rencana yang lebih baik, lebih sedikit tumpahan, dan lebih sedikit I/O.
Sekarang Group By pasti memiliki tempatnya dalam hal menggabungkan data alih-alih mengembalikan banyak baris. Tapi kuncinya di sini adalah untuk mengurangi I/O, penambahan agregasi menambah I/O.
Ringkasan
Ini hanyalah tip-of-the-gunung es dari hal-hal yang harus dilakukan, tetapi tempat yang bagus untuk mulai mengurangi I/O. Sebelum Anda menyalahkan perangkat keras atas masalah latensi Anda, lihat apa yang dapat Anda lakukan untuk meminimalkan tekanan disk.
Tentang Penulis
 Monica Rathbun saat ini adalah Konsultan di Denny Cherry &Associates Consulting, dan MVP Platform Data Microsoft. Dia telah menjadi Lone DBA selama 15 tahun, bekerja dengan semua aspek SQL Server dan Oracle. Dia melakukan perjalanan berbicara di SQLSaturdays membantu Lone DBA lainnya dengan teknik tentang bagaimana seseorang dapat melakukan pekerjaan banyak orang. Monica adalah Pemimpin Grup Pengguna SQL Server Hampton Roads dan merupakan Mentor Regional Mid-Atlantic Pass. Anda selalu dapat menemukan Monica di Twitter (@SQLEspresso) membagikan tips dan trik bermanfaat kepada pengikutnya. Ketika dia tidak sibuk dengan pekerjaan, Anda akan menemukannya bermain sebagai sopir taksi untuk kedua putrinya bolak-balik ke kelas dansa.
Monica Rathbun saat ini adalah Konsultan di Denny Cherry &Associates Consulting, dan MVP Platform Data Microsoft. Dia telah menjadi Lone DBA selama 15 tahun, bekerja dengan semua aspek SQL Server dan Oracle. Dia melakukan perjalanan berbicara di SQLSaturdays membantu Lone DBA lainnya dengan teknik tentang bagaimana seseorang dapat melakukan pekerjaan banyak orang. Monica adalah Pemimpin Grup Pengguna SQL Server Hampton Roads dan merupakan Mentor Regional Mid-Atlantic Pass. Anda selalu dapat menemukan Monica di Twitter (@SQLEspresso) membagikan tips dan trik bermanfaat kepada pengikutnya. Ketika dia tidak sibuk dengan pekerjaan, Anda akan menemukannya bermain sebagai sopir taksi untuk kedua putrinya bolak-balik ke kelas dansa.