T-SQL Tuesday #78 dipandu oleh Wendy Pastrick, dan tantangan bulan ini adalah untuk "mempelajari sesuatu yang baru dan membuat blog tentangnya." Uraiannya condong ke fitur-fitur baru di SQL Server 2016, tetapi karena saya telah membuat blog dan mempresentasikan banyak dari itu, saya pikir saya akan menjelajahi sesuatu yang lain secara langsung yang selalu membuat saya benar-benar penasaran.
Saya telah melihat banyak orang menyatakan bahwa tumpukan bisa lebih baik daripada indeks berkerumun untuk skenario tertentu. Saya tidak bisa tidak setuju dengan itu. Namun, salah satu alasan menarik yang pernah saya lihat adalah bahwa Pencarian RID lebih cepat daripada Pencarian Kunci. Saya penggemar berat indeks berkerumun dan bukan penggemar berat tumpukan, jadi saya merasa ini perlu beberapa pengujian.
Jadi, mari kita uji!
Saya pikir akan lebih baik untuk membuat database dengan dua tabel, identik kecuali yang satu memiliki kunci utama yang dikelompokkan, dan yang lainnya memiliki kunci utama yang tidak dikelompokkan. Saya akan memuat waktu beberapa baris ke dalam tabel, memperbarui sekelompok baris dalam satu lingkaran, dan memilih dari indeks (memaksa Key atau RID Lookup).
Spesifikasi Sistem
Pertanyaan ini sering muncul, jadi untuk memperjelas detail penting tentang sistem ini, saya menggunakan VM 8-core dengan RAM 32 GB, didukung oleh penyimpanan PCIe. Versi SQL Server adalah 2014 SP1 CU6, tanpa perubahan konfigurasi khusus atau tanda pelacakan yang berjalan:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)13 Apr 2016 12:41:07
Hak Cipta (c) Microsoft Corporation
Edisi Pengembang (64- bit) pada Windows NT 6.3
Basis Data
Saya membuat database dengan banyak ruang kosong di data dan file log untuk mencegah peristiwa autogrow mengganggu pengujian. Saya juga menyetel database ke pemulihan sederhana untuk meminimalkan dampak pada log transaksi.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Tabel
Seperti yang saya katakan, dua tabel, dengan satu-satunya perbedaan adalah apakah kunci utama dikelompokkan.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Tabel Untuk Menangkap Waktu Proses
Saya bisa memantau CPU dan semua itu, tetapi sebenarnya rasa ingin tahu hampir selalu seputar runtime. Jadi saya membuat tabel logging untuk menangkap runtime setiap pengujian:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Uji Sisipan
Jadi, berapa lama waktu yang dibutuhkan untuk menyisipkan 2.000 baris, 100 kali? Saya mengambil beberapa data yang cukup mendasar dari sys.all_objects , dan menarik definisi untuk prosedur, fungsi, dll.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Uji Pembaruan
Untuk pengujian pembaruan, saya hanya ingin menguji kecepatan penulisan ke indeks berkerumun vs. tumpukan dengan cara yang sangat baris demi baris. Jadi saya membuang 200 baris acak ke dalam tabel #temp, lalu membuat kursor di sekitarnya (tabel #temp hanya memastikan bahwa 200 baris yang sama diperbarui di kedua versi tabel, yang mungkin berlebihan).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Tes Pilih
Jadi, di atas Anda melihat bahwa saya membuat indeks dengan Name sebagai kolom kunci di setiap tabel; untuk mengevaluasi biaya melakukan pencarian untuk sejumlah besar baris, saya menulis kueri yang menetapkan output ke variabel (menghilangkan I/O jaringan dan waktu rendering klien), tetapi memaksa penggunaan indeks:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Untuk yang satu ini saya ingin menunjukkan beberapa aspek menarik dari rencana sebelum menyusun hasil tes. Menjalankannya secara individual head-to-head memberikan metrik komparatif berikut:

Durasi tidak penting untuk satu pernyataan, tetapi lihat bacaan tersebut. Jika Anda menggunakan penyimpanan yang lambat, itu adalah perbedaan besar yang tidak akan Anda lihat dalam skala yang lebih kecil dan/atau pada SSD pengembangan lokal Anda.
Dan kemudian paket menampilkan dua pencarian yang berbeda, menggunakan SQL Sentry Plan Explorer:

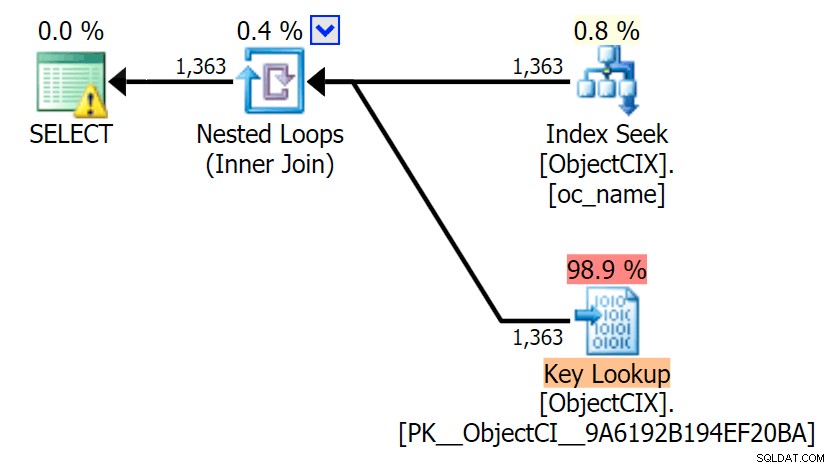
Paket terlihat hampir identik, dan Anda mungkin tidak melihat perbedaan pembacaan di SSMS kecuali jika Anda merekam I/O Statistik. Bahkan perkiraan biaya I/O untuk kedua pencarian serupa – 1,69 untuk Pencarian Kunci, dan 1,59 untuk pencarian RID. (Ikon peringatan di kedua paket adalah untuk indeks penutup yang hilang.)
Menarik untuk dicatat bahwa jika kita tidak memaksakan pencarian dan mengizinkan SQL Server untuk memutuskan apa yang harus dilakukan, SQL Server akan memilih pemindaian standar dalam kedua kasus – tidak ada peringatan indeks yang hilang, dan lihat seberapa dekat pembacaannya:

Pengoptimal mengetahui bahwa pemindaian akan jauh lebih murah daripada pencarian + pencarian dalam kasus ini. Saya memilih kolom LOB untuk penetapan variabel hanya untuk efek, tetapi hasilnya serupa dengan menggunakan kolom non-LOB juga.
Hasil Tes
Dengan tabel Pengaturan Waktu, saya dapat dengan mudah menjalankan tes beberapa kali (saya menjalankan selusin tes) dan kemudian datang dengan rata-rata untuk tes dengan kueri berikut:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
Bagan batang sederhana menunjukkan perbandingannya:
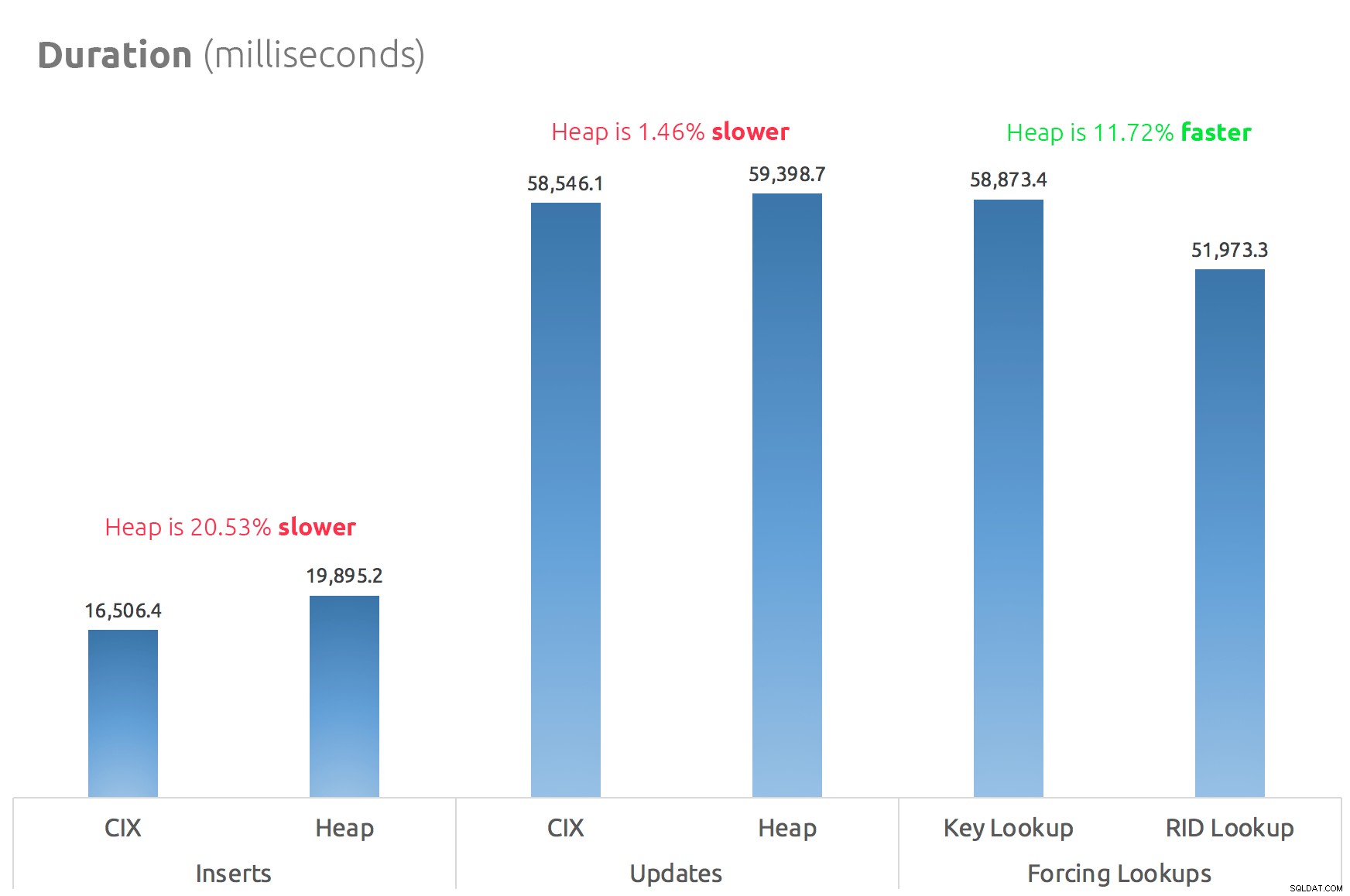
Kesimpulan
Jadi, rumor itu benar:dalam hal ini setidaknya, Pencarian RID secara signifikan lebih cepat daripada Pencarian Kunci. Langsung ke file:page:slot jelas lebih efisien dalam hal I/O daripada mengikuti b-tree (dan jika Anda tidak menggunakan penyimpanan modern, delta bisa jauh lebih terlihat).
Apakah Anda ingin memanfaatkannya, dan membawa semua aspek heap lainnya, akan bergantung pada beban kerja Anda – heap sedikit lebih mahal untuk operasi tulis. Tapi ini tidak definitif – ini bisa sangat bervariasi tergantung pada struktur tabel, indeks, dan pola akses.
Saya menguji hal-hal yang sangat sederhana di sini, dan jika Anda ragu tentang hal ini, saya sangat menyarankan untuk menguji beban kerja Anda yang sebenarnya pada perangkat keras Anda sendiri dan membandingkannya sendiri (dan jangan lupa untuk menguji beban kerja yang sama di mana indeks penutup ada; Anda mungkin akan mendapatkan kinerja keseluruhan yang jauh lebih baik jika Anda dapat menghilangkan pencarian sama sekali). Pastikan untuk mengukur semua metrik yang penting bagi Anda; hanya karena saya fokus pada durasi tidak berarti itu yang paling Anda butuhkan. :-)