Minggu lalu saya menerbitkan posting berjudul #BackToBasics :DATEFROMPARTS() , di mana saya menunjukkan cara menggunakan fungsi 2012+ ini untuk kueri rentang tanggal yang lebih bersih dan lebih baik. Saya menggunakannya untuk menunjukkan bahwa jika Anda menggunakan predikat tanggal terbuka, dan Anda memiliki indeks pada kolom tanggal/waktu yang relevan, Anda dapat berakhir dengan penggunaan indeks yang jauh lebih baik dan I/O yang lebih rendah (atau, dalam kasus terburuk , sama, jika pencarian tidak dapat digunakan karena alasan tertentu, atau jika tidak ada indeks yang sesuai):
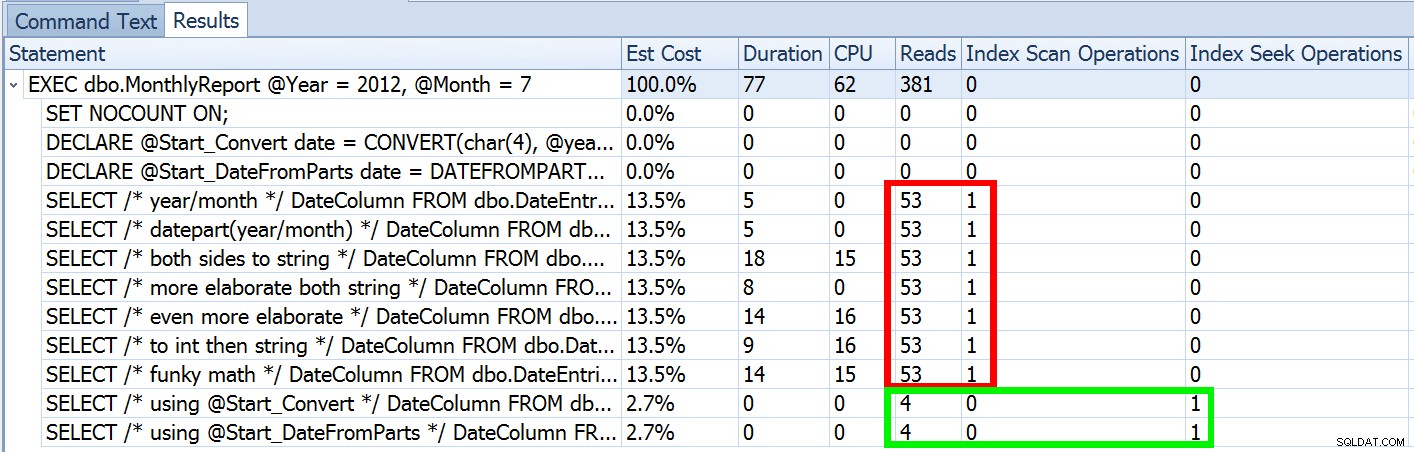
Tapi itu hanya sebagian dari cerita (dan untuk lebih jelasnya, DATEFROMPARTS() tidak secara teknis diperlukan untuk mencari, hanya saja lebih bersih dalam hal ini). Jika kami memperkecil sedikit, kami melihat bahwa perkiraan kami jauh dari akurat, kerumitan yang tidak ingin saya perkenalkan di posting sebelumnya:
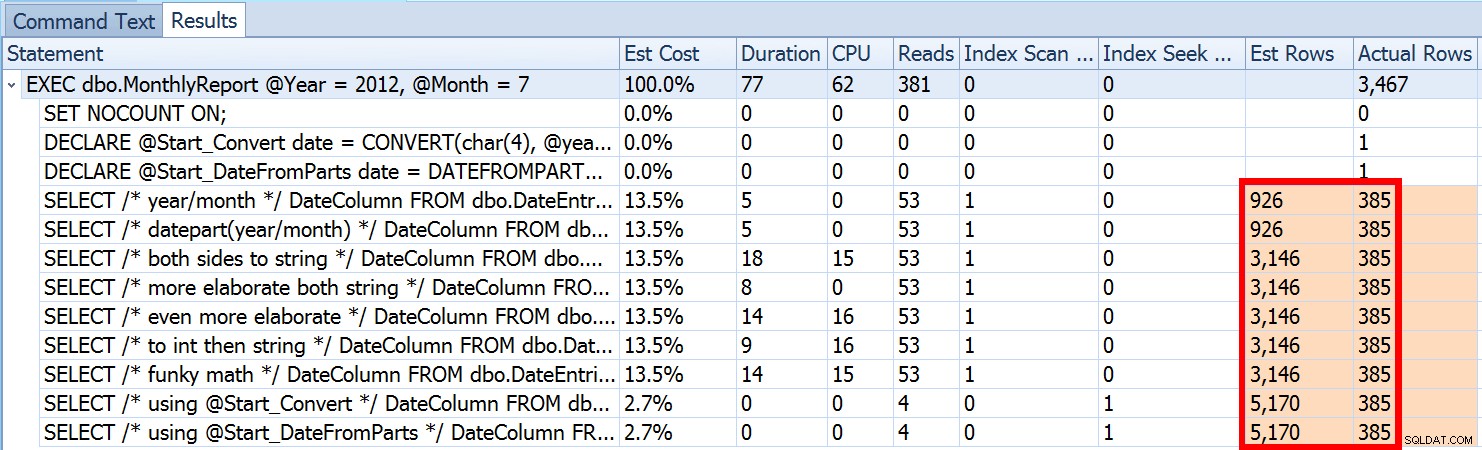
Ini tidak biasa untuk predikat ketidaksetaraan dan dengan pemindaian paksa. Dan tentu saja, bukankah metode yang saya sarankan menghasilkan statistik yang paling tidak akurat? Berikut adalah pendekatan dasar (Anda bisa mendapatkan skema tabel, indeks, dan data sampel dari posting saya sebelumnya):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Sekarang, perkiraan yang tidak akurat tidak selalu menjadi masalah, tetapi dapat menyebabkan masalah dengan pilihan rencana yang tidak efisien di dua ekstrem. Satu paket mungkin tidak optimal ketika rentang yang dipilih akan menghasilkan persentase tabel atau indeks yang sangat kecil atau sangat besar, dan ini bisa menjadi sangat sulit bagi SQL Server untuk memprediksi saat distribusi data tidak merata. Joseph Sack menguraikan hal-hal umum yang dapat dipengaruhi oleh perkiraan buruk dalam postingannya, "Sepuluh Ancaman Umum terhadap Kualitas Rencana Eksekusi:"
"[...] perkiraan baris yang buruk dapat memengaruhi berbagai keputusan termasuk pemilihan indeks, operasi pencarian vs. pemindaian, eksekusi paralel versus serial, pemilihan algoritme gabungan, pemilihan gabungan fisik dalam vs. luar (mis. build vs. probe), pembuatan spool, pencarian bookmark vs. akses kluster penuh atau tabel tumpukan, aliran atau pemilihan agregat hash, dan apakah modifikasi data menggunakan rencana lebar atau sempit."
Ada juga yang lain, seperti hibah memori yang terlalu besar atau terlalu kecil. Dia melanjutkan untuk menjelaskan beberapa penyebab perkiraan buruk yang lebih umum, tetapi penyebab utama dalam kasus ini hilang dari daftarnya:perkiraan. Karena kami menggunakan variabel lokal untuk mengubah int . yang masuk parameter ke satu date local lokal variabel, SQL Server tidak tahu apa nilainya, jadi itu membuat tebakan standar kardinalitas berdasarkan seluruh tabel.
Kami melihat di atas bahwa perkiraan untuk pendekatan yang saya sarankan adalah 5.170 baris. Sekarang, kita tahu bahwa dengan predikat ketidaksetaraan, dan dengan SQL Server tidak mengetahui nilai parameter, itu akan menebak 30% dari tabel. 31,645 * 0.3 bukan 5.170. Juga bukan 31,465 * 0.3 * 0.3 , ketika kita ingat bahwa sebenarnya ada dua predikat yang bekerja melawan kolom yang sama. Jadi dari mana nilai 5.170 ini?
Seperti yang dijelaskan Paul White dalam postingnya, "Estimasi Kardinalitas untuk Beberapa Predikat," penaksir kardinalitas baru di SQL Server 2014 menggunakan backoff eksponensial, sehingga mengalikan jumlah baris tabel (31.465) dengan selektivitas predikat pertama (0,3) , lalu mengalikannya dengan akar kuadrat selektivitas predikat kedua (~0.547723).
31,645 * (0,3) * KJT (0,3) ~=5,170,227Jadi, sekarang kita bisa melihat di mana SQL Server muncul dengan perkiraannya; apa saja metode yang dapat kita gunakan untuk melakukan sesuatu?
- Masukkan parameter tanggal. Jika memungkinkan, Anda dapat mengubah aplikasi agar melewati parameter tanggal yang tepat, bukan parameter bilangan bulat yang terpisah.
- Gunakan prosedur pembungkus. Variasi pada metode #1 – misalnya jika Anda tidak dapat mengubah aplikasi – adalah dengan membuat prosedur tersimpan kedua yang menerima parameter tanggal yang dibuat dari yang pertama.
- Gunakan
OPTION (RECOMPILE). Dengan sedikit biaya kompilasi setiap kali kueri dijalankan, ini memaksa SQL Server untuk mengoptimalkan berdasarkan nilai yang disajikan setiap kali, alih-alih mengoptimalkan satu paket untuk nilai parameter yang tidak diketahui, pertama, atau rata-rata. (Untuk pembahasan menyeluruh tentang topik ini, lihat "Parameter Sniffing, Embedding, and the RECOMPILE Options" dari Paul White.
- Gunakan SQL dinamis. Memiliki SQL dinamis menerima
dateyang dibuat variabel memaksa parameterisasi yang tepat (sama seperti jika Anda memanggil prosedur tersimpan dengandateparameter), tetapi sedikit jelek, dan lebih sulit untuk dipelihara.
- Berantakan dengan petunjuk dan tanda jejak. Paul White membicarakan beberapa di antaranya dalam postingan yang disebutkan di atas.
Saya tidak akan menyarankan bahwa ini adalah daftar yang lengkap, dan saya tidak akan mengulangi saran Paul tentang petunjuk atau tanda jejak, jadi saya hanya akan fokus untuk menunjukkan bagaimana empat pendekatan pertama dapat mengurangi masalah dengan perkiraan yang buruk. .
1. Parameter Tanggal
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Prosedur Pembungkus
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. OPSI (REKOMPILASI)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. SQL Dinamis
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Ujian
Dengan empat set prosedur, mudah untuk membuat tes yang akan menunjukkan kepada saya rencana dan perkiraan yang diturunkan SQL Server. Karena beberapa bulan lebih sibuk daripada yang lain, saya memilih tiga bulan yang berbeda, dan mengeksekusi semuanya beberapa kali.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Hasil? Setiap paket menghasilkan Pencarian Indeks yang sama, tetapi perkiraannya hanya benar di ketiga rentang tanggal di OPTION (RECOMPILE) Versi:kapan. Sisanya terus menggunakan estimasi yang diturunkan dari set parameter pertama (Juli 2012), dan sementara mereka mendapatkan estimasi yang lebih baik untuk pertama eksekusi, perkiraan itu belum tentu lebih baik untuk selanjutnya eksekusi menggunakan parameter yang berbeda (kasus klasik, buku teks tentang parameter sniffing):
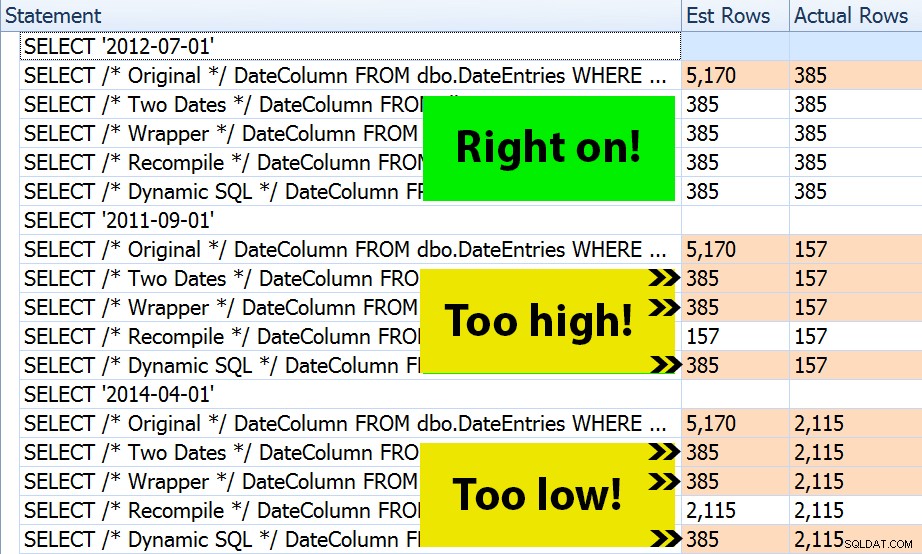
Perhatikan bahwa di atas bukan *exact* output dari SQL Sentry Plan Explorer – misalnya, saya menghapus baris pohon pernyataan yang menunjukkan panggilan prosedur tersimpan luar dan deklarasi parameter.
Terserah Anda untuk menentukan apakah taktik kompilasi setiap waktu adalah yang terbaik untuk Anda, atau apakah Anda perlu "memperbaiki" apa pun sejak awal. Di sini, kami berakhir dengan rencana yang sama, dan tidak ada perbedaan mencolok dalam metrik kinerja runtime. Tetapi pada tabel yang lebih besar, dengan distribusi data yang lebih miring, dan varians yang lebih besar dalam nilai predikat (misalnya, pertimbangkan laporan yang dapat mencakup satu minggu, satu tahun, dan apa pun di antaranya), mungkin perlu diselidiki. Dan perhatikan bahwa Anda dapat menggabungkan metode di sini – misalnya, Anda dapat beralih ke parameter tanggal yang tepat *dan* menambahkan OPTION (RECOMPILE) , jika Anda mau.
Kesimpulan
Dalam kasus khusus ini, yang merupakan penyederhanaan yang disengaja, upaya untuk mendapatkan perkiraan yang benar tidak benar-benar membuahkan hasil – kami tidak mendapatkan rencana yang berbeda, dan kinerja runtime setara. Namun, tentu saja ada kasus lain, di mana ini akan membuat perbedaan, dan penting untuk mengenali perbedaan perkiraan dan menentukan apakah itu mungkin menjadi masalah saat data Anda tumbuh dan/atau distribusi Anda miring. Sayangnya, tidak ada jawaban hitam-putih, karena banyak variabel akan mempengaruhi apakah overhead kompilasi dibenarkan – seperti banyak skenario, IT DEPENDS™ …



