Dalam posting saya sebelumnya di seri ini, saya menunjukkan bahwa tidak semua skenario kueri dapat mengambil manfaat dari teknologi OLTP Dalam Memori. Faktanya, menggunakan Hekaton dalam kasus penggunaan tertentu sebenarnya dapat berdampak buruk pada kinerja (klik untuk memperbesar):

Profil monitor kinerja selama eksekusi prosedur tersimpan
Namun, saya mungkin telah menumpuk tumpukan melawan Hekaton dalam skenario itu, dengan dua cara:
- Jenis tabel dengan memori yang dioptimalkan yang saya buat memiliki jumlah ember 256, tetapi saya meneruskan hingga 2.000 nilai untuk dibandingkan. Dalam posting blog yang lebih baru dari tim SQL Server, mereka menjelaskan bahwa ukuran yang terlalu besar dari jumlah ember lebih baik daripada mengecilkannya – sesuatu yang saya tahu secara umum, tetapi tidak menyadarinya juga memiliki efek signifikan pada variabel tabel:Pertahankan ingat bahwa untuk indeks hash, bucket_count harus sekitar 1-2X jumlah kunci indeks unik yang diharapkan. Over-sizing biasanya lebih baik daripada under-sizing:jika terkadang Anda hanya memasukkan 2 nilai dalam variabel, tetapi terkadang memasukkan hingga 1000 nilai, biasanya lebih baik untuk menentukan
BUCKET_COUNT=1000.Mereka tidak secara eksplisit membahas alasan sebenarnya untuk ini, dan saya yakin ada banyak detail teknis yang dapat kami selidiki, tetapi panduan preskriptif tampaknya terlalu berlebihan.
- Kunci utama adalah indeks hash pada dua kolom, sedangkan parameter nilai tabel hanya mencoba mencocokkan nilai di salah satu kolom tersebut. Sederhananya, ini berarti bahwa indeks hash tidak dapat digunakan. Tony Rogerson menjelaskan ini sedikit lebih detail dalam posting blog baru-baru ini:Hash dihasilkan di semua kolom yang terdapat dalam indeks, Anda juga harus menentukan semua kolom dalam indeks hash pada ekspresi pemeriksaan kesetaraan Anda jika tidak, indeks tidak dapat digunakan .
Saya tidak menunjukkannya sebelumnya, tetapi perhatikan bahwa rencana terhadap tabel yang dioptimalkan memori dengan indeks hash dua kolom sebenarnya melakukan pemindaian tabel daripada pencarian indeks yang mungkin Anda harapkan terhadap indeks hash non-cluster (sejak terkemuka kolomnya adalah
SalesOrderID):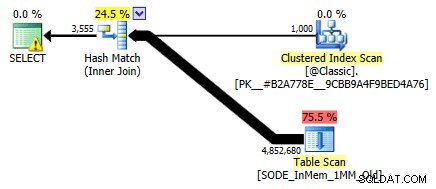
Paket kueri yang melibatkan tabel dalam memori dengan dua kolom indeks hashUntuk lebih spesifik, dalam indeks hash, kolom terdepan tidak berarti bukit kacang itu sendiri; hash masih cocok di semua kolom, sehingga tidak berfungsi seperti indeks B-tree tradisional sama sekali (dengan indeks tradisional, predikat yang hanya melibatkan kolom terdepan masih bisa sangat berguna dalam menghilangkan baris).
Apa yang Harus Dilakukan?
Pertama, saya membuat indeks hash sekunder hanya di SalesOrderID kolom. Contoh satu tabel seperti itu, dengan sejuta ember:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); Ingat bahwa jenis tabel kami diatur dengan cara ini:
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Setelah saya mengisi tabel baru dengan data, dan membuat prosedur tersimpan baru untuk mereferensikan tabel baru, rencana yang kami dapatkan dengan benar menunjukkan pencarian indeks terhadap indeks hash kolom tunggal:

Paket yang ditingkatkan menggunakan indeks hash satu kolom
Tapi apa artinya itu bagi kinerja? Saya menjalankan rangkaian pengujian yang sama lagi – kueri terhadap tabel ini dengan jumlah bucket 16K, 131K, dan 1MM; menggunakan TVP klasik dan dalam memori dengan nilai 100, 1.000, dan 2.000; dan dalam kasus TVP dalam memori, menggunakan prosedur tersimpan tradisional dan prosedur tersimpan yang dikompilasi secara asli. Begini performanya untuk 10.000 iterasi per kombinasi:

Profil kinerja untuk 10.000 iterasi terhadap indeks hash satu kolom, menggunakan TVP 256-bucket
Anda mungkin berpikir, hei, profil kinerja itu tidak terlihat bagus; sebaliknya, ini jauh lebih baik dari tes saya sebelumnya bulan lalu. Itu hanya menunjukkan bahwa jumlah ember untuk tabel dapat memiliki dampak besar pada kemampuan SQL Server untuk menggunakan indeks hash secara efektif. Dalam kasus ini, menggunakan jumlah ember 16K jelas tidak optimal untuk semua kasus ini, dan akan menjadi lebih buruk secara eksponensial karena jumlah nilai di TVP meningkat.
Sekarang, ingat, jumlah ember TVP adalah 256. Jadi apa yang akan terjadi jika saya meningkatkannya, sesuai panduan Microsoft? Saya membuat tipe tabel kedua dengan ukuran ember yang lebih sesuai. Karena saya menguji nilai 100, 1.000, dan 2.000, saya menggunakan kekuatan 2 berikutnya untuk hitungan ember (2.048):
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
Saya membuat prosedur pendukung untuk ini, dan menjalankan tes yang sama lagi. Berikut adalah profil kinerja secara berdampingan:

Perbandingan profil kinerja dengan 256- dan 2.048-bucket TVP
Perubahan jumlah ember untuk jenis tabel tidak memiliki dampak yang saya harapkan, mengingat pernyataan Microsoft tentang ukuran. Itu benar-benar tidak memiliki banyak efek positif sama sekali; sebenarnya untuk beberapa skenario itu sedikit lebih buruk. Namun secara keseluruhan, profil performa, untuk semua maksud dan tujuan, sama.
Namun, apa yang memiliki efek besar adalah menciptakan indeks hash *benar* untuk mendukung pola kueri. Saya bersyukur bahwa saya dapat menunjukkan bahwa – terlepas dari tes saya sebelumnya yang menunjukkan sebaliknya – tabel dalam memori dan TVP dalam memori dapat mengalahkan cara lama untuk mencapai hal yang sama. Mari kita ambil kasus yang paling ekstrim dari contoh saya sebelumnya, ketika tabel hanya memiliki indeks hash dua kolom:

Profil kinerja untuk 10 iterasi terhadap indeks hash dua kolom
Bilah paling kanan menunjukkan durasi hanya 10 iterasi dari prosedur tersimpan asli yang cocok dengan indeks hash yang tidak sesuai – waktu kueri berkisar antara 735 hingga 1.601 milidetik. Namun, sekarang, dengan indeks hash yang tepat, kueri yang sama dieksekusi dalam rentang yang jauh lebih kecil – dari 0,076 milidetik hingga 51,55 milidetik. Jika kita mengabaikan kasus terburuk (jumlah ember 16 ribu), perbedaannya bahkan lebih jelas. Dalam semua kasus, ini setidaknya dua kali lebih efisien (setidaknya dalam hal durasi) sebagai metode mana pun, tanpa prosedur tersimpan yang dikompilasi secara naif, terhadap tabel yang dioptimalkan memori yang sama; dan ratusan kali lebih baik daripada pendekatan mana pun terhadap tabel lama kami yang dioptimalkan memori dengan indeks hash dua kolom tunggal.
Kesimpulan
Saya harap saya telah menunjukkan bahwa banyak perhatian harus dilakukan ketika menerapkan tabel yang dioptimalkan memori dari jenis apa pun, dan bahwa dalam banyak kasus, menggunakan TVP yang dioptimalkan memori sendiri mungkin tidak menghasilkan peningkatan kinerja terbesar. Anda akan ingin mempertimbangkan untuk menggunakan prosedur tersimpan yang dikompilasi secara asli untuk mendapatkan hasil maksimal, dan untuk skala terbaik, Anda benar-benar ingin memperhatikan jumlah ember untuk indeks hash di tabel yang dioptimalkan memori (tapi mungkin tidak sangat memperhatikan jenis tabel yang dioptimalkan memori).
Untuk bacaan tambahan tentang teknologi In-Memory OLTP secara umum, Anda mungkin ingin melihat sumber daya berikut:
- Blog Tim SQL Server (Tag:Hekaton dan Tag:OLTP Dalam Memori – bukankah nama kode menyenangkan?)
- Blog Bob Beauchemin
- Blog Klaus Aschenbrenner