Ada banyak diskusi tentang In-Memory OLTP (fitur yang sebelumnya dikenal sebagai "Hekaton") dan bagaimana fitur ini dapat membantu beban kerja volume tinggi yang sangat spesifik. Di tengah percakapan yang berbeda, saya kebetulan melihat sesuatu di CREATE TYPE dokumentasi untuk SQL Server 2014 yang membuat saya berpikir mungkin ada kasus penggunaan yang lebih umum:

Penambahan yang relatif tenang dan tidak diketahui pada dokumentasi CREATE TYPE
Berdasarkan diagram sintaks, tampaknya parameter nilai tabel (TVP) dapat dioptimalkan memori, seperti halnya tabel permanen. Dan dengan itu, roda segera mulai berputar.
Satu hal yang saya gunakan untuk TVP adalah membantu pelanggan menghilangkan metode pemisahan string yang mahal di T-SQL atau CLR (lihat latar belakang di posting sebelumnya di sini, di sini, dan di sini). Dalam pengujian saya, menggunakan TVP biasa mengungguli pola yang setara menggunakan fungsi pemisahan CLR atau T-SQL dengan margin yang signifikan (25-50%). Saya bertanya-tanya secara logis:Apakah ada peningkatan kinerja dari TVP yang dioptimalkan memori?
Ada beberapa kekhawatiran tentang OLTP Dalam Memori secara umum, karena ada banyak keterbatasan dan celah fitur, Anda memerlukan grup file terpisah untuk data yang dioptimalkan memori, Anda perlu memindahkan seluruh tabel ke memori yang dioptimalkan, dan manfaat terbaik biasanya dicapai dengan juga membuat prosedur tersimpan yang dikompilasi secara asli (yang memiliki batasan sendiri). Seperti yang akan saya tunjukkan, dengan asumsi tipe tabel Anda berisi struktur data sederhana (misalnya, mewakili satu set bilangan bulat atau string), menggunakan teknologi ini hanya untuk TVP menghilangkan beberapa dari masalah ini.
Ujian
Anda masih memerlukan grup file yang dioptimalkan memori bahkan jika Anda tidak akan membuat tabel permanen yang dioptimalkan memori. Jadi mari kita buat database baru dengan struktur yang sesuai:
BUAT DATABASE xtp;GOALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA;GOALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod x') KE FILEGROUP GROUP; SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT =AKTIF;PERGI
Sekarang, kita dapat membuat tipe tabel biasa, seperti yang kita lakukan hari ini, dan tipe tabel yang dioptimalkan memori dengan indeks hash non-clustered dan jumlah ember yang saya tarik keluar dari udara (informasi lebih lanjut tentang menghitung kebutuhan memori dan jumlah ember di dunia nyata di sini):
GUNAKAN xtp;GO CREATE TYPE dbo.ClassicTVP AS TABLE( Item INT PRIMARY KEY); BUAT TYPE dbo.InMemoryTVP AS TABLE( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT =256)) WITH (MEMORY_OPTIMIZED =ON);
Jika Anda mencoba ini di database yang tidak memiliki grup file yang dioptimalkan memori, Anda akan mendapatkan pesan kesalahan ini, seperti yang Anda lakukan jika Anda mencoba membuat tabel yang dioptimalkan memori normal:
Msg 41337, Level 16, State 0, Line 9Grup file MEMORY_OPTIMIZED_DATA tidak ada atau kosong. Tabel yang dioptimalkan memori tidak dapat dibuat untuk database hingga memiliki satu grup file MEMORY_OPTIMIZED_DATA yang tidak kosong.
Untuk menguji kueri terhadap tabel reguler yang tidak dioptimalkan memori, saya cukup menarik beberapa data ke dalam tabel baru dari database sampel AdventureWorks2012, menggunakan SELECT INTO untuk mengabaikan semua kendala, indeks, dan properti yang diperluas, lalu buat indeks berkerumun pada kolom yang saya tahu akan saya cari (ProductID ):
PILIH * INTO dbo.Produk DARI AdventureWorks2012.Production.Product; -- 504 baris BUAT INDEKS CLUSTERED UNIK p PADA dbo.Products(ProductID);
Selanjutnya saya membuat empat prosedur tersimpan:dua untuk setiap jenis tabel; masing-masing menggunakan EXISTS dan JOIN pendekatan (saya biasanya suka memeriksa keduanya, meskipun saya lebih suka EXISTS; nanti Anda akan melihat mengapa saya tidak ingin membatasi pengujian saya hanya EXISTS ). Dalam hal ini saya hanya menetapkan baris arbitrer ke variabel, sehingga saya dapat mengamati jumlah eksekusi yang tinggi tanpa berurusan dengan hasil dan output serta overhead lainnya:
-- TVP jadul menggunakan EXISTS:CREATE PROCEDURE dbo.ClassicTVP_Exists @Classic dbo.ClassicTVP READONLYASBEGIN SET NOCOUNT ON; MENYATAKAN @nama NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p WHERE EXISTS ( PILIH 1 FROM @Classic AS t WHERE t.Item =p.ProductID );ENDGO -- TVP Dalam Memori menggunakan EXISTS:CREATE PROCEDURE dbo.InMemoryTVP_Exists @InMemory dbo.InMemoryTVP READONLYASBEGIN SET NOCOUNT ON; MENYATAKAN @nama NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p WHERE EXISTS ( SELECT 1 FROM @InMemory AS t WHERE t.Item =p.ProductID );ENDGO -- TVP lama menggunakan JOIN:CREATE PROCEDURE dbo.ClassicTVP_Join @ Classic dbo.ClassicTVP READONLYASBEGIN SET NOCOUNT ON; MENYATAKAN @nama NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p INNER JOIN @Classic AS t ON t.Item =p.ProductID;ENDGO -- TVP Dalam Memori menggunakan JOIN:CREATE PROCEDURE dbo.InMemoryTVP_Join @InMemory dbo.InMemoryTVP READONLYASBEGIN SET NOCOUNT AKTIF; MENYATAKAN @nama NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;ENDGO
Selanjutnya, saya perlu mensimulasikan jenis kueri yang biasanya bertentangan dengan jenis tabel ini dan membutuhkan TVP atau pola serupa di tempat pertama. Bayangkan sebuah formulir dengan drop-down atau set kotak centang yang berisi daftar produk, dan pengguna dapat memilih 20 atau 50 atau 200 yang ingin mereka bandingkan, daftar, apa yang Anda miliki. Nilai-nilai tidak akan berada dalam satu set bersebelahan yang bagus; mereka biasanya akan tersebar di semua tempat (jika itu adalah rentang yang dapat diprediksi berdekatan, kueri akan jauh lebih sederhana:nilai awal dan akhir). Jadi saya hanya memilih 20 nilai sewenang-wenang dari tabel (mencoba untuk tetap di bawah, katakanlah, 5% dari ukuran tabel), dipesan secara acak. Cara mudah untuk membuat VALUES yang dapat digunakan kembali klausa seperti ini adalah sebagai berikut:
DECLARE @x VARCHAR(4000) =''; SELECT TOP (20) @x +='(' + RTRIM(ProductID) + '),' FROM dbo.Products ORDER BY NEWID(); PILIH @x; Hasilnya (Anda hampir pasti akan bervariasi):
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735 ),(441),(409),(454),(780),(966),(988),(512),
Tidak seperti INSERT...SELECT direct langsung , ini membuatnya cukup mudah untuk memanipulasi output tersebut menjadi pernyataan yang dapat digunakan kembali untuk mengisi TVP kami berulang kali dengan nilai yang sama dan melalui beberapa iterasi pengujian:
ATUR NOCOUNT AKTIF; MENYATAKAN @ClassicTVP dbo.ClassicTVP;MENYATAKAN @InMemoryTVP dbo.InMemoryTVP; MASUKKAN @ClassicTVP(Item) NILAI (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442) ,(450),(735),(441),(409),(454),(780),(966),(988),(512); MASUKKAN @InMemoryTVP(Item) NILAI (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442) ,(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP;EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Join @InMemory =@ Jika kita menjalankan batch ini menggunakan SQL Sentry Plan Explorer, rencana yang dihasilkan menunjukkan perbedaan besar:TVP dalam memori dapat menggunakan gabungan loop bersarang dan 20 pencarian indeks berkerumun baris tunggal, vs. gabungan gabungan yang diberi makan 502 baris oleh pemindaian indeks berkerumun untuk TVP klasik. Dan dalam hal ini, EXISTS dan JOIN menghasilkan rencana yang identik. Ini mungkin tip dengan jumlah nilai yang jauh lebih tinggi, tetapi mari kita lanjutkan dengan asumsi bahwa jumlah nilai akan kurang dari 5% dari ukuran tabel:
Rencana untuk TVP Klasik dan Dalam Memori
Tips alat untuk operator pemindaian/pencarian, menyoroti perbedaan utama – Klasik di kiri, In- Memori di kanan
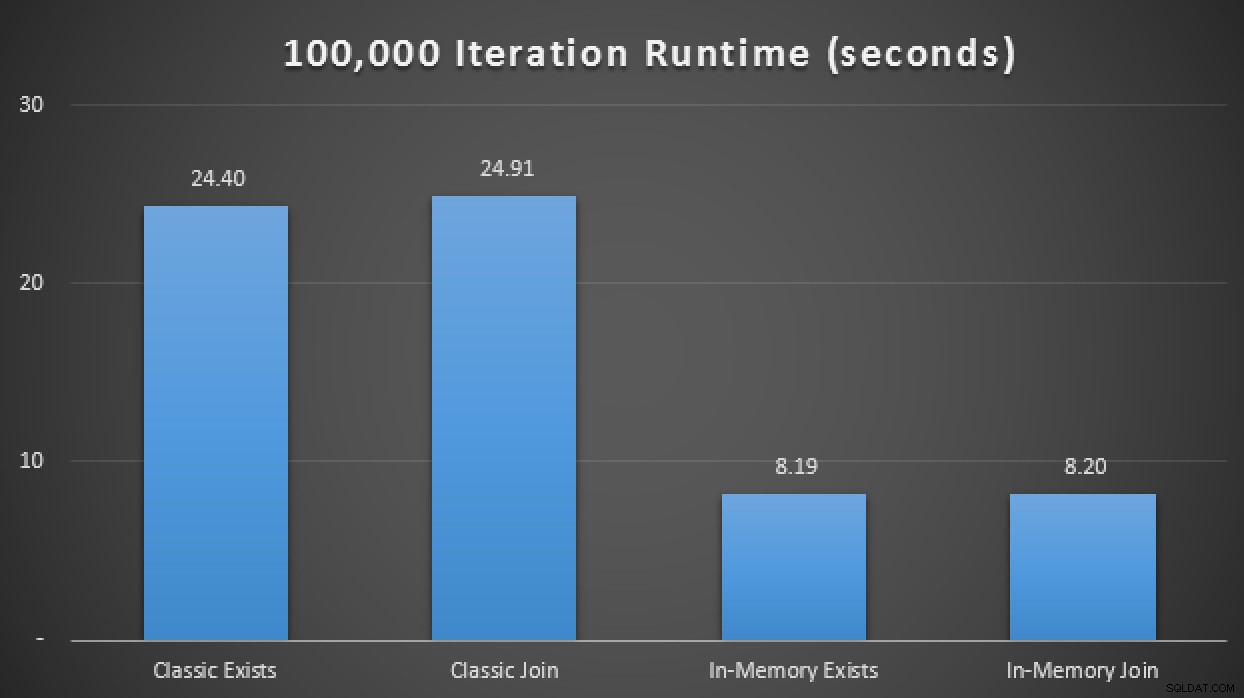
Sekarang apa artinya ini pada skala? Mari kita matikan semua koleksi showplan, dan ubah skrip pengujian sedikit untuk menjalankan setiap prosedur 100.000 kali, menangkap runtime kumulatif secara manual:
DECLARE @i TINYINT =1, @j INT =1; WHILE @i <=4MULAI PILIH SYSDATETIME(); SEMENTARA @j <=100000 BEGIN JIKA @i =1 BEGIN EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP; AKHIR JIKA @i =2 BEGIN EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP; SELESAI JIKA @i =3 MULAI EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP; SELESAI JIKA @i =4 MULAI EXEC dbo.InMemoryTVP_Join @InMemory =@InMemoryTVP; SETELAN AKHIR @j +=1; END SELECT @i +=1, @j =1;END SELECT SYSDATETIME();Dalam hasil, rata-rata lebih dari 10 proses, kami melihat bahwa, setidaknya dalam kasus uji terbatas ini, menggunakan jenis tabel yang dioptimalkan memori menghasilkan peningkatan sekitar 3X lipat pada metrik kinerja paling penting dalam OLTP (durasi waktu proses):
Hasil runtime menunjukkan peningkatan 3X dengan TVP Dalam MemoriDalam Memori + Dalam Memori + Dalam Memori :Awal Dalam Memori
Sekarang kita telah melihat apa yang dapat kita lakukan dengan hanya mengubah tipe tabel biasa kita menjadi tipe tabel yang dioptimalkan memori, mari kita lihat apakah kita dapat memeras performa lagi dari pola kueri yang sama ini saat kita menerapkan trifecta:an in-memory tabel, menggunakan prosedur tersimpan yang dioptimalkan memori yang dikompilasi secara asli, yang menerima tabel tabel dalam memori sebagai parameter bernilai tabel.
Pertama, kita perlu membuat salinan tabel baru, dan mengisinya dari tabel lokal yang sudah kita buat:
CREATE TABLE dbo.Products_InMemory( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStock NOTLevel , ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Ukuran] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Berat] DECIMAL(8, 2) NULL(8, 2) DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, Se llStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT =256))_BILONTIM( MEMORIZE_BILONTIM); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;Selanjutnya, kami membuat prosedur tersimpan yang dikompilasi secara asli yang menggunakan jenis tabel yang dioptimalkan memori yang ada sebagai TVP:
BUAT PROSEDUR dbo.InMemoryProcedure @InMemory dbo.InMemoryTVP READONLYWITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL =SNAPSHOT, LANGUAGE =N'us_english'); MENYATAKAN @Nama NVARCHAR(50); SELECT @Name =Name FROM dbo.Products_InMemory AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;END GOBeberapa peringatan. Kami tidak dapat menggunakan tipe tabel reguler yang tidak dioptimalkan memori sebagai parameter untuk prosedur tersimpan yang dikompilasi secara asli. Jika kita mencoba, kita mendapatkan:
Msg 41323, Level 16, State 1, Procedure InMemoryProcedure
Tipe tabel 'dbo.ClassicTVP' bukan tipe tabel yang dioptimalkan memori dan tidak dapat digunakan dalam prosedur tersimpan yang dikompilasi secara asli.Selain itu, kami tidak dapat menggunakan
Msg 12311, Level 16, Status 37, Procedure NativeCompiled_ExistsEXISTSpola di sini baik; ketika kita mencoba, kita mendapatkan:
Subquery (kueri yang disarangkan di dalam kueri lain) tidak didukung dengan prosedur tersimpan yang dikompilasi secara asli.Ada banyak peringatan dan batasan lain dengan In-Memory OLTP dan prosedur tersimpan yang dikompilasi secara asli, saya hanya ingin berbagi beberapa hal yang mungkin tampak jelas hilang dari pengujian.
Jadi menambahkan prosedur tersimpan yang dikompilasi secara asli baru ini ke matriks uji di atas, saya menemukan bahwa – sekali lagi, rata-rata lebih dari 10 proses – ia mengeksekusi 100.000 iterasi hanya dalam 1,25 detik. Ini mewakili peningkatan sekitar 20X dibandingkan TVP biasa dan peningkatan 6-7X dibandingkan TVP dalam memori menggunakan tabel dan prosedur tradisional:
Hasil runtime menunjukkan peningkatan hingga 20X dengan In-Memory di sekelilingnyaKesimpulan
Jika Anda menggunakan TVP sekarang, atau Anda menggunakan pola yang dapat diganti oleh TVP, Anda benar-benar harus mempertimbangkan untuk menambahkan TVP yang dioptimalkan memori ke rencana pengujian Anda, tetapi perlu diingat bahwa Anda mungkin tidak melihat peningkatan yang sama dalam skenario Anda. (Dan, tentu saja, perlu diingat bahwa TVP pada umumnya memiliki banyak peringatan dan batasan, dan juga tidak sesuai untuk semua skenario. Erland Sommarskog memiliki artikel bagus tentang TVP saat ini di sini.)
Sebenarnya Anda mungkin melihat bahwa pada volume dan konkurensi yang rendah, tidak ada perbedaan – tetapi harap uji pada skala yang realistis. Ini adalah tes yang sangat sederhana dan dibuat-buat pada laptop modern dengan satu SSD, tetapi ketika Anda berbicara tentang volume nyata dan/atau disk mekanis yang berputar, karakteristik kinerja ini mungkin lebih berat. Ada tindak lanjut yang datang dengan beberapa demonstrasi tentang ukuran data yang lebih besar.