Dalam posting terakhir saya, saya menunjukkan bahwa pada volume kecil, TVP dengan memori yang dioptimalkan dapat memberikan manfaat kinerja yang substansial untuk pola kueri biasa.
Untuk menguji pada skala yang sedikit lebih tinggi, saya membuat salinan SalesOrderDetailEnlarged table, yang telah saya kembangkan menjadi sekitar 5.000.000 baris berkat skrip ini oleh Jonathan Kehayias (blog | @SQLPoolBoy)).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Saya juga membuat tiga versi dalam memori dari tabel ini, masing-masing dengan jumlah ember yang berbeda (memancing "titik manis") – 16.384, 131.072, dan 1.048.576. (Anda dapat menggunakan angka yang lebih bulat, tetapi angka tersebut akan dibulatkan ke pangkat 2 berikutnya.) Contoh:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Perhatikan saya mengubah ukuran ember dari contoh sebelumnya (256). Saat membuat tabel, Anda ingin memilih "titik manis" untuk ukuran bucket – Anda ingin mengoptimalkan indeks hash untuk pencarian titik, artinya Anda menginginkan bucket sebanyak mungkin dengan sesedikit mungkin baris di setiap bucket. Tentu saja jika Anda membuat ~5 juta ember (karena dalam kasus ini, mungkin bukan contoh yang sangat baik, ada ~5 juta kombinasi nilai yang unik), Anda akan memiliki beberapa pemanfaatan memori dan pertukaran pengumpulan sampah untuk ditangani. Namun jika Anda mencoba memasukkan ~5 juta nilai unik ke dalam 256 ember, Anda juga akan mengalami beberapa masalah. Bagaimanapun, diskusi ini melampaui lingkup pengujian saya untuk posting ini.
Untuk menguji terhadap tabel standar, saya membuat prosedur tersimpan yang serupa seperti pada pengujian sebelumnya:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Jadi pertama-tama, untuk melihat rencana, katakanlah, 1.000 baris dimasukkan ke dalam variabel tabel, lalu jalankan prosedurnya:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Kali ini, kita melihat bahwa dalam kedua kasus, pengoptimal telah memilih pencarian indeks berkerumun terhadap tabel dasar dan loop bersarang bergabung melawan TVP. Beberapa metrik biaya berbeda, tetapi sebaliknya, rencananya sangat mirip:
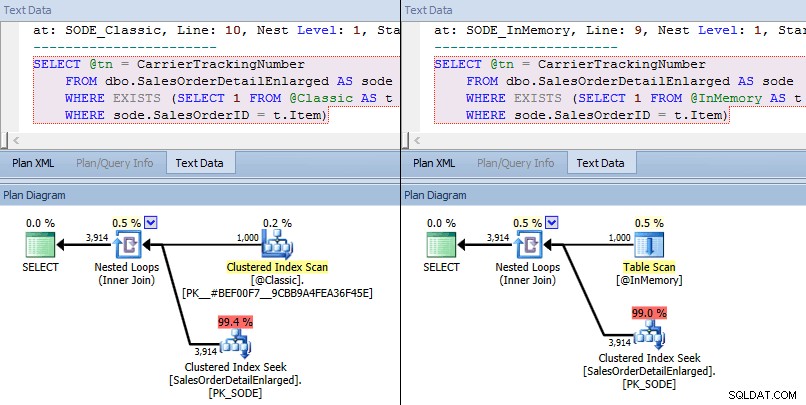 Paket serupa untuk TVP dalam memori vs. TVP klasik pada skala yang lebih tinggi
Paket serupa untuk TVP dalam memori vs. TVP klasik pada skala yang lebih tinggi
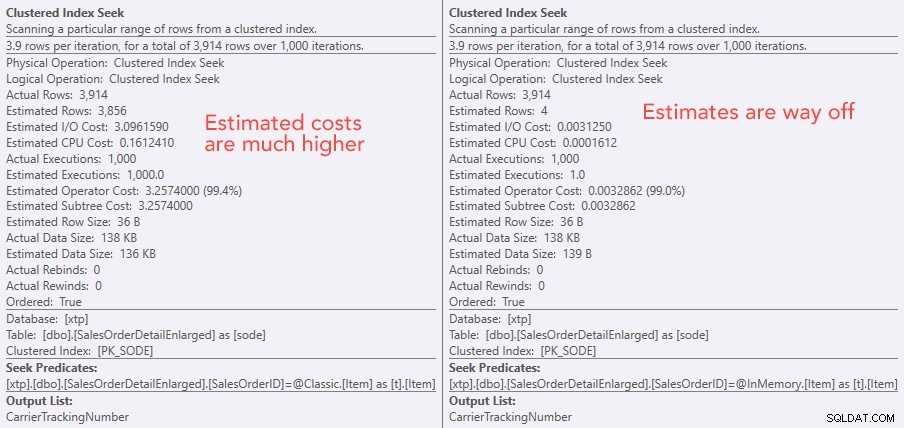 Membandingkan biaya operator pencarian – Klasik di sebelah kiri, Dalam Memori di sebelah kanan
Membandingkan biaya operator pencarian – Klasik di sebelah kiri, Dalam Memori di sebelah kanan
Nilai absolut dari biaya membuatnya tampak seperti TVP klasik akan jauh lebih tidak efisien daripada TVP Dalam Memori. Tetapi saya bertanya-tanya apakah ini benar dalam praktiknya (terutama karena angka Perkiraan Jumlah Eksekusi di sebelah kanan tampak mencurigakan), jadi tentu saja, saya menjalankan beberapa tes. Saya memutuskan untuk memeriksa nilai 100, 1.000, dan 2.000 untuk dikirim ke prosedur.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
Hasil kinerja menunjukkan bahwa, pada jumlah pencarian titik yang lebih besar, menggunakan TVP Dalam Memori menyebabkan hasil yang sedikit berkurang, menjadi sedikit lebih lambat setiap saat:
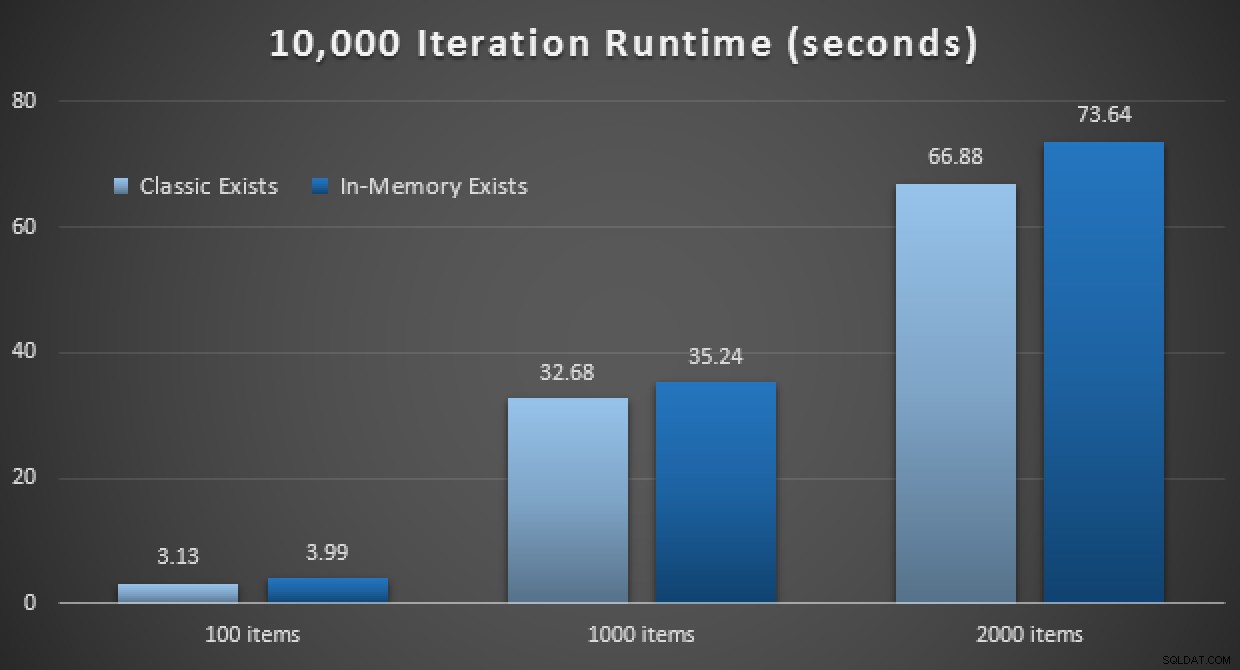
Hasil 10.000 eksekusi menggunakan TVP klasik dan dalam memori
Jadi, bertentangan dengan kesan yang mungkin Anda ambil dari posting saya sebelumnya, menggunakan TVP dalam memori belum tentu bermanfaat dalam semua kasus.
Sebelumnya saya juga melihat prosedur tersimpan yang dikompilasi secara asli dan tabel dalam memori, dalam kombinasi dengan TVP dalam memori. Bisakah ini membuat perbedaan di sini? Spoiler:sama sekali tidak. Saya membuat tiga prosedur seperti ini:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Spoiler lain:Saya tidak dapat menjalankan 9 tes ini dengan jumlah iterasi 10.000 – terlalu lama. Alih-alih, saya mengulang dan menjalankan setiap prosedur 10 kali, menjalankan serangkaian tes itu 10 kali, dan mengambil rata-rata. Berikut adalah hasilnya:
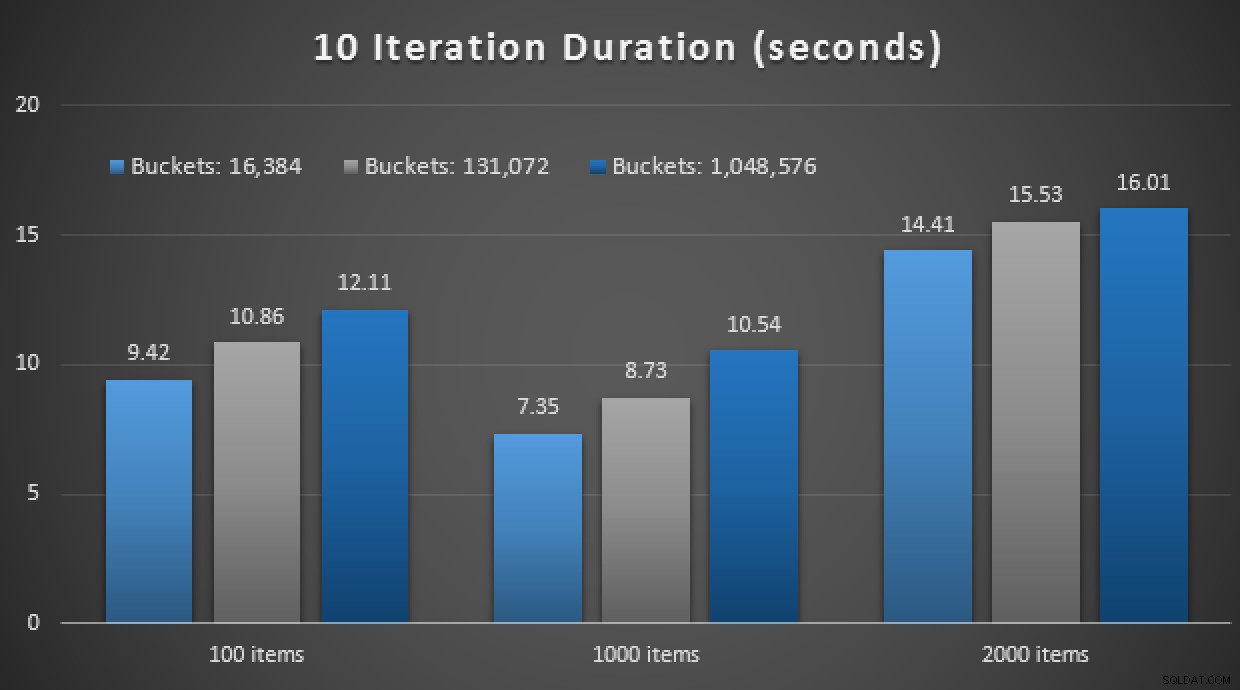
Hasil dari 10 eksekusi menggunakan TVP dalam memori dan dikompilasi secara asli disimpan prosedur
Secara keseluruhan, eksperimen ini agak mengecewakan. Hanya dengan melihat besarnya perbedaan, dengan tabel di disk, panggilan prosedur tersimpan rata-rata diselesaikan dalam rata-rata 0,0036 detik. Namun, ketika semuanya menggunakan teknologi dalam memori, panggilan prosedur tersimpan rata-rata adalah 1,1662 detik. Aduh . Kemungkinan besar saya baru saja memilih kasus penggunaan yang buruk untuk didemonstrasikan secara keseluruhan, tetapi tampaknya pada saat itu merupakan "percobaan pertama" yang intuitif.
Kesimpulan
Ada banyak lagi untuk diuji di sekitar skenario ini, dan saya memiliki lebih banyak posting blog untuk diikuti. Saya belum mengidentifikasi kasus penggunaan optimal untuk TVP dalam memori pada skala yang lebih besar, tetapi berharap posting ini berfungsi sebagai pengingat bahwa meskipun solusi tampaknya optimal dalam satu kasus, tidak pernah aman untuk menganggapnya sama-sama berlaku untuk skenario yang berbeda. Inilah tepatnya bagaimana OLTP Dalam Memori harus didekati:sebagai solusi dengan serangkaian kasus penggunaan sempit yang mutlak harus divalidasi sebelum diimplementasikan dalam produksi.



