Latar Belakang
Salah satu hal pertama yang saya lihat ketika saya memecahkan masalah kinerja adalah menunggu statistik melalui sys.dm_os_wait_stats DMV. Untuk melihat apa yang menunggu SQL Server, saya menggunakan kueri dari kumpulan Kueri Diagnostik SQL Server Glenn Berry saat ini. Bergantung pada outputnya, saya mulai menggali area tertentu di dalam SQL Server.
Sebagai contoh, jika saya melihat CXPACKET menunggu tinggi, saya memeriksa jumlah inti di server, jumlah node NUMA, dan nilai untuk derajat paralelisme maksimum dan ambang biaya untuk paralelisme. Ini adalah informasi latar belakang yang saya gunakan untuk memahami konfigurasi. Bahkan sebelum saya mempertimbangkan untuk membuat perubahan apa pun, saya mengumpulkan lebih banyak data kuantitatif, karena sistem dengan CXPACKET menunggu tidak selalu memiliki pengaturan yang salah untuk derajat paralelisme maksimum.
Demikian pula, sistem yang memiliki waktu tunggu tinggi untuk jenis menunggu terkait I/O seperti PAGEIOLATCH_XX, WRITELOG, dan IO_COMPLETION tidak selalu memiliki subsistem penyimpanan yang lebih rendah. Ketika saya melihat tipe menunggu terkait I/O sebagai menunggu teratas, saya langsung ingin memahami lebih banyak tentang penyimpanan yang mendasarinya. Apakah itu penyimpanan yang terpasang langsung atau SAN? Berapa tingkat RAID, berapa banyak disk yang ada dalam larik, dan berapa kecepatannya? Saya juga ingin tahu apakah file atau database lain berbagi penyimpanan. Dan meskipun penting untuk memahami konfigurasi, langkah logis berikutnya adalah melihat statistik file virtual melalui sys.dm_io_virtual_file_stats DMV.
Diperkenalkan pada SQL Server 2005, DMV ini adalah pengganti fungsi fn_virtualfilestats yang mungkin sudah diketahui dan disukai oleh Anda yang menjalankan SQL Server 2000 dan sebelumnya. DMV berisi informasi I/O kumulatif untuk setiap file database, tetapi data direset pada saat restart, ketika database ditutup, offline, terlepas dan disambungkan kembali, dll. Sangat penting untuk memahami bahwa data statistik file virtual tidak mewakili data saat ini. performance – ini adalah snapshot yang merupakan agregasi data I/O sejak kliring terakhir oleh salah satu peristiwa yang disebutkan di atas. Meskipun datanya tidak tepat waktu, itu masih bisa berguna. Jika waktu tunggu tertinggi untuk instans terkait dengan I/O, tetapi waktu tunggu rata-rata kurang dari 10 mdtk, penyimpanan mungkin tidak menjadi masalah – tetapi menghubungkan output dengan apa yang Anda lihat di sys.dm_io_virtual_stats masih layak untuk dikonfirmasi rendah latency. Selanjutnya, bahkan jika Anda melihat latensi tinggi di sys.dm_io_virtual_stats, Anda masih belum membuktikan bahwa penyimpanan adalah masalah.
Penyiapan
Untuk melihat statistik file virtual, saya menyiapkan dua salinan database AdventureWorks2012, yang dapat Anda unduh dari Codeplex. Untuk salinan pertama, selanjutnya dikenal sebagai EX_AdventureWorks2012, saya menjalankan skrip Jonathan Kehayias untuk memperluas tabel Sales.SalesOrderHeader dan Sales.SalesOrderDetail masing-masing menjadi 1,2 juta dan 4,9 juta baris. Untuk database kedua, BIG_AdventureWorks2012, saya menggunakan skrip dari posting partisi saya sebelumnya untuk membuat salinan tabel Sales.SalesOrderHeader dengan 123 juta baris. Kedua database disimpan di drive USB eksternal (Seagate Slim 500GB), dengan tempdb di disk lokal saya (SSD).
Sebelum pengujian, saya membuat empat prosedur tersimpan khusus di setiap database (Create_Custom_SPs.zip), yang akan berfungsi sebagai beban kerja "normal" saya. Proses pengujian saya adalah sebagai berikut untuk setiap database:
- Mulai ulang instance.
- Tangkap statistik file virtual.
- Jalankan beban kerja "normal" selama dua menit (prosedur yang dipanggil berulang kali melalui skrip PowerShell).
- Tangkap statistik file virtual.
- Buat ulang semua indeks untuk tabel SalesOrder yang sesuai.
- Tangkap statistik file virtual.
Data
Untuk menangkap statistik file virtual, saya membuat tabel untuk menyimpan informasi historis, lalu menggunakan variasi kueri Jimmy May dari skrip DMV All-Stars untuk snapshot:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Saya memulai ulang instance dan kemudian segera menangkap statistik file. Ketika saya memfilter output untuk hanya melihat file database EX_AdventureWorks2012 dan tempdb, hanya data tempdb yang diambil karena tidak ada data yang diminta dari database EX_AdventureWorks2012:

Keluaran dari pengambilan awal sys.dm_os_virtual_file_stats
Saya kemudian menjalankan beban kerja "normal" selama dua menit (jumlah eksekusi setiap prosedur tersimpan sedikit berbeda), dan setelah itu menyelesaikan statistik file yang diambil lagi:

Keluaran dari sys.dm_os_virtual_file_stats setelah beban kerja normal
Kami melihat latensi 57 ms untuk file data EX_AdventureWorks2012. Tidak ideal, tetapi seiring waktu dengan beban kerja normal saya, ini mungkin akan seimbang. Ada latensi minimal untuk tempdb, yang diharapkan karena beban kerja yang saya jalankan tidak menghasilkan banyak aktivitas tempdb. Selanjutnya saya membangun kembali semua indeks untuk tabel Sales.SalesOrderHeaderEnlarged dan Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Pembuatan ulang memakan waktu kurang dari satu menit, dan perhatikan lonjakan latensi baca untuk file data EX_AdventureWorks2012, dan lonjakan latensi tulis untuk data EX_AdventureWorks2012 dan file log:

Keluaran dari sys.dm_os_virtual_file_stats setelah indeks dibangun kembali
Menurut snapshot statistik file itu, latensinya mengerikan; lebih dari 600 ms untuk menulis! Jika saya melihat nilai ini untuk sistem produksi, akan mudah untuk langsung mencurigai masalah dengan penyimpanan. Namun, perlu diperhatikan juga bahwa AvgBPerWrite juga meningkat, dan penulisan blok yang lebih besar membutuhkan waktu lebih lama untuk diselesaikan. Peningkatan AvgBPerWrite diharapkan untuk tugas pembangunan kembali indeks.
Pahami bahwa saat Anda melihat data ini, Anda tidak mendapatkan gambaran yang lengkap. Cara yang lebih baik untuk melihat latensi menggunakan statistik file virtual adalah dengan mengambil snapshot dan kemudian menghitung latensi untuk periode waktu yang telah berlalu. Misalnya, skrip di bawah ini menggunakan dua snapshot (Saat Ini dan Sebelumnya) lalu menghitung jumlah baca dan tulis dalam jangka waktu tersebut, perbedaan nilai io_stall_read_ms dan io_stall_write_ms, lalu bagi delta io_stall_read_ms dengan jumlah pembacaan, dan delta io_stall_write_ms dengan jumlah tulisan. Dengan metode ini, kami menghitung jumlah waktu SQL Server menunggu di I/O untuk membaca atau menulis, dan kemudian membaginya dengan jumlah membaca atau menulis untuk menentukan latensi.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Saat kami menjalankan ini untuk menghitung latensi selama pembangunan kembali indeks, kami mendapatkan yang berikut:

Latensi dihitung dari sys.dm_io_virtual_file_stats selama pembuatan ulang indeks untuk EX_AdventureWorks2012
Sekarang kita dapat melihat bahwa latensi aktual selama waktu itu tinggi – yang kita harapkan. Dan jika kami kemudian kembali ke beban kerja normal kami dan menjalankannya selama beberapa jam, nilai rata-rata yang dihitung dari statistik file virtual akan berkurang seiring waktu. Faktanya, jika kita melihat data PerfMon yang diambil selama pengujian (dan kemudian diproses melalui PAL), kita melihat lonjakan yang signifikan pada Rata-rata. Disk sec/Baca dan Rta. Disk sec/Write yang berkorelasi dengan waktu indeks membangun kembali sedang berjalan. Namun di lain waktu, nilai latensi jauh di bawah nilai yang dapat diterima:
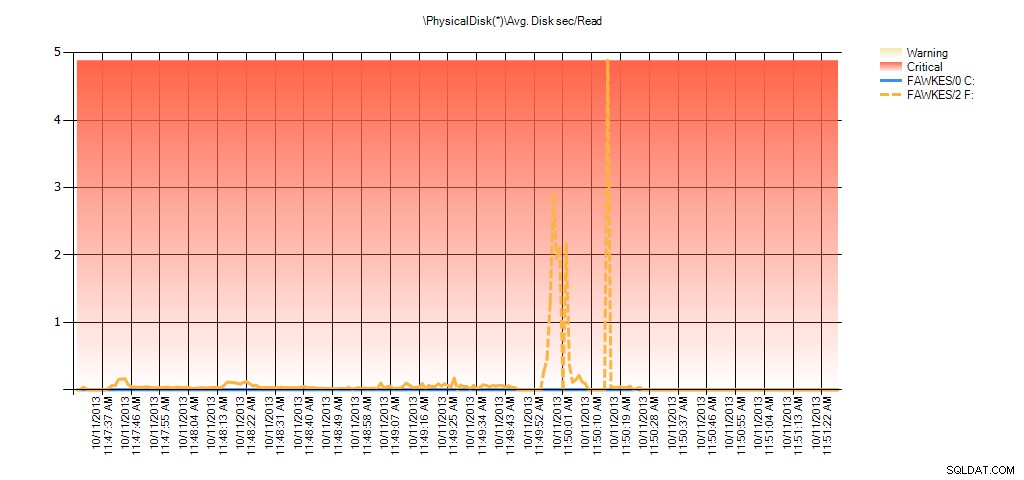
Ringkasan Detik Disk Rata-Rata/Baca dari PAL untuk EX_AdventureWorks2012 selama pengujian
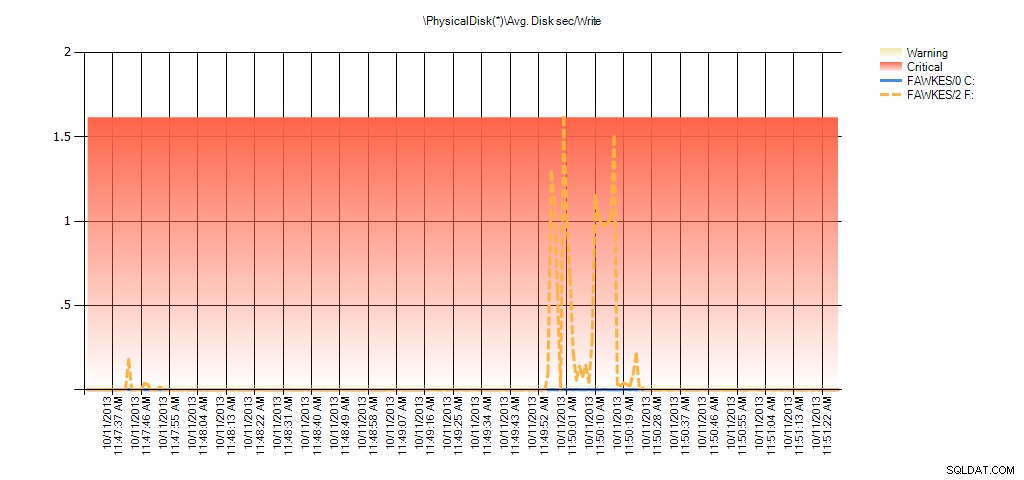
Ringkasan Detik Disk Rata-Rata/Tulis dari PAL untuk EX_AdventureWorks2012 selama pengujian
Anda dapat melihat perilaku yang sama untuk database BIG_AdventureWorks 2012. Berikut adalah informasi latensi berdasarkan snapshot statistik file virtual sebelum indeks dibangun kembali dan setelahnya:

Latensi dihitung dari sys.dm_io_virtual_file_stats selama pembuatan ulang indeks untuk BIG_AdventureWorks2012
Dan data Performance Monitor menunjukkan lonjakan yang sama selama pembangunan kembali:
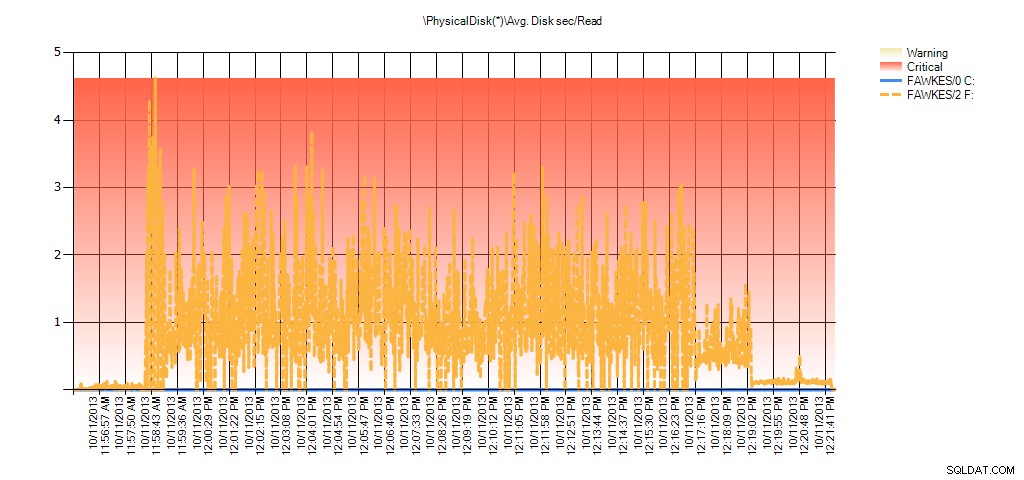
Ringkasan Rata-rata Detik Disk/Baca dari PAL untuk BIG_AdventureWorks2012 selama pengujian
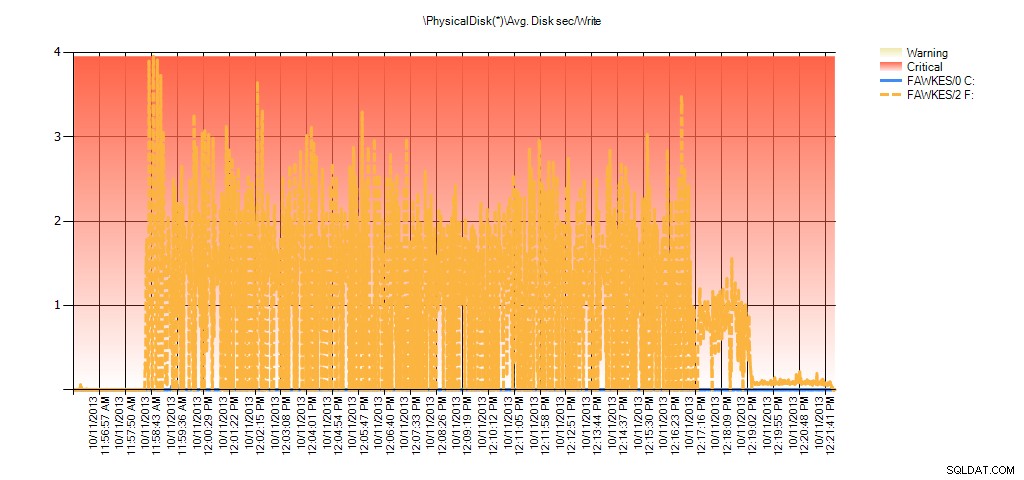
Ringkasan Rata-rata Detik Disk/Tulis dari PAL untuk BIG_AdventureWorks2012 selama pengujian
Kesimpulan
Statistik file virtual adalah titik awal yang bagus ketika Anda ingin memahami kinerja I/O untuk instance SQL Server. Jika Anda melihat menunggu terkait I/O saat melihat statistik menunggu, melihat sys.dm_io_virtual_file_stats adalah langkah logis berikutnya. Namun, pahami bahwa data yang Anda lihat adalah agregat sejak statistik terakhir dihapus oleh salah satu peristiwa terkait (misalnya restart, offline database, dll). Jika Anda melihat latensi rendah, maka subsistem I/O mengikuti beban kinerja. Namun, jika Anda melihat latensi tinggi, itu bukan kesimpulan pasti bahwa penyimpanan adalah masalah. Untuk benar-benar mengetahui apa yang terjadi, Anda dapat mulai memotret statistik file, seperti yang ditunjukkan di sini, atau Anda dapat menggunakan Monitor Kinerja untuk melihat latensi secara real time. Sangat mudah untuk membuat Kumpulan Pengumpul Data di PerfMon yang menangkap penghitung Disk Fisik Rata-rata. Disk Detik/Baca dan Rta. Disk Sec/Read untuk semua disk yang menampung file database. Jadwalkan Pengumpul Data untuk memulai dan menghentikan secara teratur, dan mengambil sampel setiap n detik (mis. 15), dan setelah Anda mengambil data PerfMon untuk waktu yang tepat, jalankan melalui PAL untuk memeriksa latensi dari waktu ke waktu.
Jika Anda menemukan bahwa latensi I/O terjadi selama beban kerja normal Anda, dan bukan hanya selama tugas pemeliharaan yang mendorong I/O, Anda masih tidak dapat menunjuk ke penyimpanan sebagai masalah mendasar. Latensi penyimpanan dapat terjadi karena berbagai alasan, seperti:
- SQL Server harus membaca terlalu banyak data karena rencana kueri yang tidak efisien atau indeks yang hilang
- Terlalu sedikit memori yang dialokasikan ke instance dan data yang sama dibaca dari disk berulang kali karena tidak dapat disimpan di memori
- Konversi implisit menyebabkan pemindaian indeks atau tabel
- Kueri menjalankan SELECT * jika tidak semua kolom diperlukan
- Masalah rekaman yang diteruskan dalam tumpukan menyebabkan I/O tambahan
- Kepadatan halaman yang rendah akibat fragmentasi indeks, pemisahan halaman, atau pengaturan faktor pengisian yang salah menyebabkan I/O tambahan
Apa pun akar masalahnya, yang penting untuk dipahami tentang kinerja – terutama yang berkaitan dengan I/O – adalah jarang ada satu titik data yang dapat Anda gunakan untuk menunjukkan masalah dengan tepat. Menemukan masalah sebenarnya membutuhkan banyak fakta yang, jika disatukan, membantu Anda mengungkap masalahnya.
Terakhir, perhatikan bahwa dalam beberapa kasus latensi penyimpanan mungkin sepenuhnya dapat diterima. Sebelum Anda menuntut penyimpanan yang lebih cepat atau perubahan kode, tinjau pola beban kerja dan Perjanjian Tingkat Layanan (SLA) untuk database. Dalam kasus Gudang Data yang melaporkan layanan kepada pengguna, SLA untuk kueri mungkin bukan nilai sub-detik yang sama yang Anda harapkan untuk sistem OLTP volume tinggi. Dalam solusi DW, latensi I/O yang lebih besar dari satu detik mungkin dapat diterima dan diharapkan dengan sempurna. Pahami harapan bisnis dan penggunanya, lalu tentukan tindakan apa, jika ada, yang harus diambil. Dan jika perubahan diperlukan, kumpulkan data kuantitatif yang Anda perlukan untuk mendukung argumen Anda, yaitu statistik tunggu, statistik file virtual, dan latensi dari Performance Monitor.