Apakah pilihan tipe data server SQL dan ukurannya penting?
Jawabannya terletak pada hasil yang Anda dapatkan. Apakah database Anda membengkak dalam waktu singkat? Apakah pertanyaan Anda lambat? Apakah Anda mendapatkan hasil yang salah? Bagaimana dengan kesalahan runtime selama penyisipan dan pembaruan?
Ini bukan tugas yang menakutkan jika Anda tahu apa yang Anda lakukan. Hari ini, Anda akan mempelajari 5 pilihan terburuk yang dapat dibuat dengan tipe data ini. Jika sudah menjadi kebiasaan Anda, ini yang harus kami perbaiki demi Anda sendiri dan pengguna Anda.
Banyak Tipe Data dalam SQL, Banyak Kebingungan
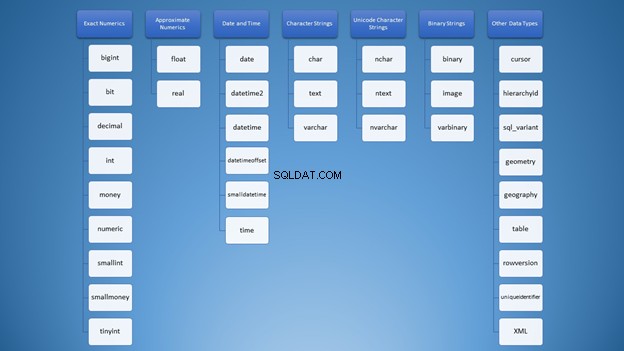
Ketika saya pertama kali belajar tentang tipe data SQL Server, pilihannya sangat banyak. Semua jenis bercampur dalam pikiran saya seperti awan kata ini pada Gambar 1:

Namun, kami dapat mengaturnya ke dalam kategori:
Namun, untuk menggunakan string, Anda memiliki banyak opsi yang dapat menyebabkan penggunaan yang salah. Pada awalnya, saya berpikir bahwa varchar dan nvarchar sama saja. Selain itu, keduanya adalah tipe string karakter. Menggunakan angka tidak berbeda. Sebagai pengembang, kita perlu mengetahui jenis mana yang akan digunakan dalam situasi yang berbeda.
Tapi Anda mungkin bertanya-tanya, apa hal terburuk yang bisa terjadi jika saya membuat pilihan yang salah? Biarkan saya memberi tahu Anda!
1. Memilih Tipe Data SQL yang Salah
Item ini akan menggunakan string dan bilangan bulat untuk membuktikan maksudnya.
Menggunakan Tipe Data SQL String Karakter yang Salah
Pertama, mari kembali ke string. Ada hal yang disebut string Unicode dan non-Unicode. Keduanya memiliki ukuran penyimpanan yang berbeda. Anda sering mendefinisikan ini pada kolom dan deklarasi variabel.
Sintaksnya adalah varchar (n)/char (n) atau nvarchar (n)/nchar (n) dimana n adalah ukurannya.
Perhatikan bahwa n bukan jumlah karakter tetapi jumlah byte. Ini adalah kesalahpahaman umum yang terjadi karena, di varchar , jumlah karakter sama dengan ukuran dalam byte. Tapi tidak di nvarchar .
Untuk membuktikan fakta ini, mari kita buat 2 tabel dan masukkan beberapa data ke dalamnya.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Sekarang mari kita periksa ukuran barisnya menggunakan DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Gambar 3 menunjukkan bahwa perbedaannya adalah dua kali lipat. Lihat di bawah.
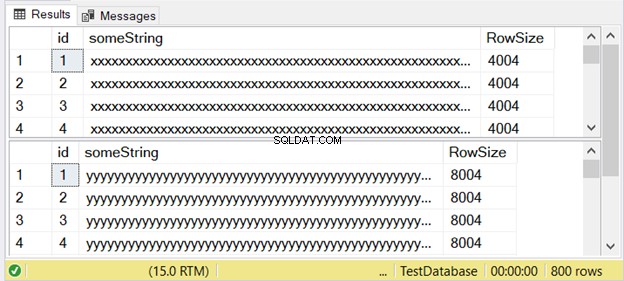
Perhatikan set hasil kedua dengan ukuran baris 8004. Ini menggunakan nvarchar tipe data. Ini juga hampir dua kali lebih besar dari ukuran baris set hasil pertama. Dan ini menggunakan varchar tipe data.
Anda melihat implikasinya pada penyimpanan dan I/O. Gambar 4 menunjukkan pembacaan logis dari 2 kueri.
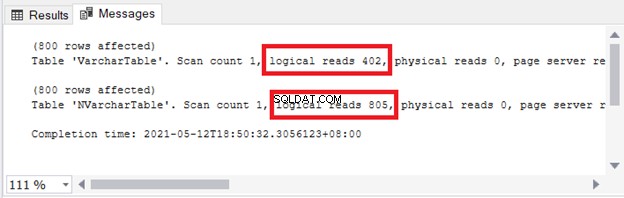
Lihat? Pembacaan logis juga dua kali lipat saat menggunakan nvarchar dibandingkan dengan varchar .
Jadi, Anda tidak bisa hanya menggunakan masing-masing secara bergantian. Jika Anda perlu menyimpan multibahasa karakter, gunakan nvarchar . Jika tidak, gunakan varchar .
Ini berarti jika Anda menggunakan nvarchar hanya untuk karakter bita tunggal (seperti bahasa Inggris), ukuran penyimpanan lebih tinggi . Performa kueri juga lebih lambat dengan pembacaan logis yang lebih tinggi.
Di SQL Server 2019 (dan lebih tinggi), Anda dapat menyimpan berbagai data karakter Unicode menggunakan varchar atau char dengan salah satu opsi susunan UTF-8.
Menggunakan SQL Tipe Data Numerik yang Salah
Konsep yang sama berlaku dengan bigint vs. int – ukurannya bisa berarti siang dan malam. Sukai nvarchar dan varchar , besar adalah dua kali ukuran int (8 byte untuk besar dan 4 byte untuk int ).
Namun, masalah lain mungkin terjadi. Jika Anda tidak keberatan dengan ukurannya, kesalahan dapat terjadi. Jika Anda menggunakan int kolom dan menyimpan angka yang lebih besar dari 2.147.483.647, aritmatika overflow akan terjadi:
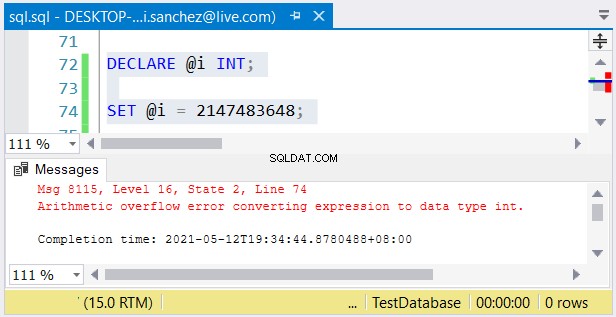
Saat memilih jenis bilangan bulat, pastikan data dengan nilai maksimum sesuai . Misalnya, Anda mungkin mendesain tabel dengan data historis. Anda berencana untuk menggunakan bilangan bulat sebagai nilai kunci utama. Apakah Anda pikir itu tidak akan mencapai 2.147.483.647 baris? Kemudian gunakan int bukannya besar sebagai tipe kolom kunci utama.
Hal Terburuk yang Bisa Terjadi
Memilih tipe data yang salah dapat memengaruhi kinerja kueri atau menyebabkan kesalahan waktu proses. Jadi, pilih tipe data yang tepat untuk data tersebut.
2. Membuat Baris Tabel Besar Menggunakan Tipe Data Besar untuk SQL
Item kami berikutnya terkait dengan yang pertama, tetapi akan lebih memperluas poin dengan contoh. Juga, ini ada hubungannya dengan halaman dan varchar . berukuran besar atau nvarchar kolom.
Ada apa dengan Halaman dan Ukuran Baris?
Konsep halaman di SQL Server dapat dibandingkan dengan halaman buku catatan spiral. Setiap halaman dalam buku catatan memiliki ukuran fisik yang sama. Anda menulis kata-kata dan menggambar di atasnya. Jika halaman tidak cukup untuk satu set paragraf dan gambar, Anda melanjutkan ke halaman berikutnya. Terkadang, Anda juga merobek halaman dan memulai dari awal.
Demikian juga, data tabel, entri indeks, dan gambar di SQL Server disimpan di halaman.
Sebuah halaman memiliki ukuran yang sama yaitu 8 KB. Jika deretan data sangat besar, tidak akan muat halaman 8 KB. Satu atau beberapa kolom akan ditulis pada halaman lain di bawah unit alokasi ROW_OVERFLOW_DATA. Ini berisi penunjuk ke baris asli pada halaman di bawah unit alokasi IN_ROW_DATA.
Berdasarkan ini, Anda tidak bisa hanya memasukkan banyak kolom dalam tabel selama desain database. Akan ada konsekuensi pada I/O. Selain itu, jika Anda banyak melakukan kueri pada data baris-overflow ini, waktu eksekusi lebih lambat . Ini bisa menjadi mimpi buruk.
Masalah muncul saat Anda memaksimalkan semua kolom dengan ukuran bervariasi. Kemudian, data akan tumpah ke halaman berikutnya di bawah ROW_OVERFLOW_DATA. perbarui kolom dengan data berukuran lebih kecil, dan itu perlu dihapus di halaman itu. Baris data baru yang lebih kecil akan ditulis pada halaman di bawah IN_ROW_DATA bersama dengan kolom lainnya. Bayangkan I/O yang terlibat di sini.
Contoh Baris Besar
Mari kita siapkan data kita terlebih dahulu. Kami akan menggunakan tipe data karakter string dengan ukuran besar.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Mendapatkan Ukuran Baris
Dari data yang dihasilkan, mari kita periksa ukuran barisnya berdasarkan DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
300 catatan pertama akan sesuai dengan halaman IN_ROW_DATA karena setiap baris memiliki kurang dari 8060 byte atau 8 KB. Tapi 100 baris terakhir terlalu besar. Lihat hasil yang ditetapkan pada Gambar 6.
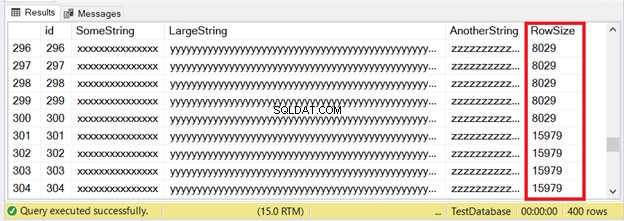
Anda melihat bagian dari 300 baris pertama. 100 berikutnya melebihi batas ukuran halaman. Bagaimana kita tahu 100 baris terakhir dalam unit alokasi ROW_OVERFLOW_DATA?
Memeriksa ROW_OVERFLOW_DATA
Kami akan menggunakan sys.dm_db_index_physical_stats . Ini mengembalikan informasi halaman tentang tabel dan entri indeks.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Himpunan hasil ada pada Gambar 7.

Itu ada. Gambar 7 menunjukkan 100 baris di bawah ROW_OVERFLOW_DATA. Ini konsisten dengan Gambar 6 ketika ada baris besar yang dimulai dengan baris 301 hingga 400.
Pertanyaan berikutnya adalah berapa banyak pembacaan logis yang kita dapatkan ketika kita menanyakan 100 baris ini. Mari kita coba.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Kami melihat 102 pembacaan logis dan 100 pembacaan logis lob LargeTable . Biarkan angka-angka ini untuk saat ini – kami akan membandingkannya nanti.
Sekarang, mari kita lihat apa yang terjadi jika kita memperbarui 100 baris dengan data yang lebih kecil.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Pernyataan pembaruan ini menggunakan pembacaan logis dan pembacaan logika lob yang sama seperti pada Gambar 8. Dari sini, kita mengetahui sesuatu yang lebih besar terjadi karena pembacaan logika lob sebanyak 100 halaman.
Tapi untuk memastikannya, mari kita periksa dengan sys.dm_db_index_physical_stats seperti yang kami lakukan sebelumnya. Gambar 9 menunjukkan hasilnya:

Hilang! Halaman dan baris dari ROW_OVERFLOW_DATA menjadi nol setelah memperbarui 100 baris dengan data yang lebih kecil. Sekarang kita tahu bahwa perpindahan data dari ROW_OVERFLOW_DATA ke IN_ROW_DATA terjadi ketika baris besar diciutkan. Bayangkan jika ini terjadi banyak untuk ribuan atau bahkan jutaan catatan. Gila, bukan?
Pada Gambar 8, kami melihat 100 pembacaan logis lob. Sekarang, lihat Gambar 10 setelah menjalankan ulang kueri:

Itu menjadi nol!
Hal Terburuk yang Bisa Terjadi
Performa kueri yang lambat adalah produk sampingan dari data limpahan baris. Pertimbangkan untuk memindahkan kolom berukuran besar ke tabel lain untuk menghindarinya. Atau, jika ada, kurangi ukuran varchar atau nvarchar kolom.
3. Secara membabi buta Menggunakan Konversi Implisit
SQL tidak mengizinkan kita untuk menggunakan data tanpa menentukan jenisnya. Tapi itu memaafkan jika kita membuat pilihan yang salah. Ia mencoba mengonversi nilai ke jenis yang diharapkannya, tetapi dengan penalti. Ini dapat terjadi dalam klausa WHERE atau JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Nomor Kartu kolom bukan tipe numerik. Ini nvarchar . Jadi, SELECT pertama akan menyebabkan konversi implisit. Namun, keduanya akan berjalan dengan baik dan menghasilkan kumpulan hasil yang sama.
Mari kita periksa rencana eksekusi pada Gambar 11.
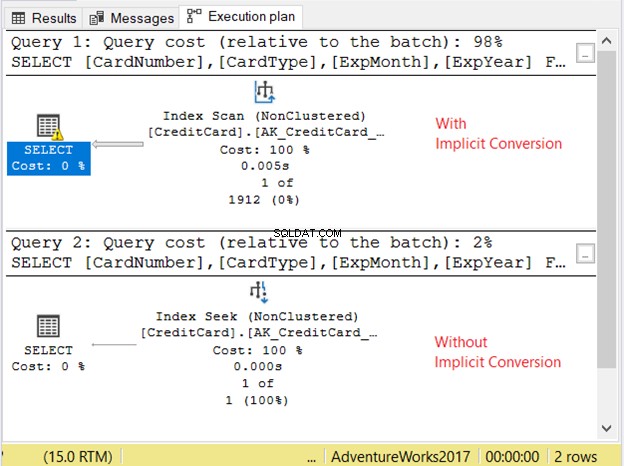
2 pertanyaan berjalan sangat cepat. Pada Gambar 11, ini adalah nol detik. Tapi lihat 2 rencana. Yang dengan konversi implisit memiliki pemindaian indeks. Ada juga ikon peringatan dan panah gemuk yang menunjuk ke operator SELECT. Ini memberi tahu kita bahwa itu buruk.
Tapi itu tidak berakhir di sana. Jika Anda mengarahkan mouse ke operator SELECT, Anda akan melihat sesuatu yang lain:

Ikon peringatan di operator SELECT adalah tentang konversi implisit. Tapi seberapa besar dampaknya? Mari kita periksa pembacaan logisnya.
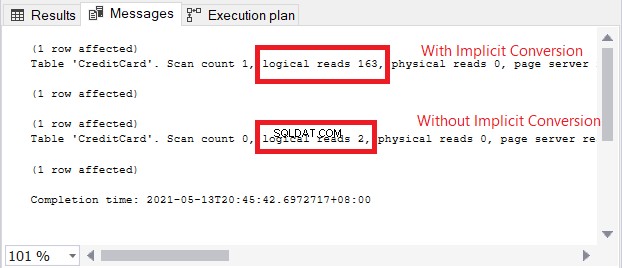
Perbandingan pembacaan logis pada Gambar 13 seperti langit dan bumi. Dalam kueri informasi kartu kredit, konversi implisit menyebabkan lebih dari seratus kali pembacaan logis. Sangat buruk!
Hal Terburuk yang Bisa Terjadi
Jika konversi implisit menyebabkan pembacaan logis yang tinggi dan rencana yang buruk, harapkan kinerja kueri yang lambat pada kumpulan hasil yang besar. Untuk menghindari hal ini, gunakan tipe data yang tepat dalam klausa WHERE dan JOIN untuk mencocokkan kolom yang Anda bandingkan.
4. Menggunakan Perkiraan Numerik dan Membulatkannya
Perhatikan gambar 2 lagi. Tipe data server SQL yang termasuk dalam perkiraan numerik adalah float dan nyata . Kolom dan variabel yang dibuat darinya menyimpan perkiraan yang mendekati nilai numerik. Jika Anda berencana untuk membulatkan angka-angka ini ke atas atau ke bawah, Anda mungkin mendapatkan kejutan besar. Saya punya artikel yang membahas ini secara rinci di sini. Lihat bagaimana 1 + 1 menghasilkan 3 dan bagaimana Anda dapat menangani angka pembulatan.
Hal Terburuk yang Bisa Terjadi
Membulatkan mengambang atau nyata bisa mendapatkan hasil yang gila. Jika Anda ingin nilai yang tepat setelah pembulatan, gunakan desimal atau numerik sebagai gantinya.
5. Menyetel Tipe Data String Berukuran Tetap ke NULL
Mari kita alihkan perhatian kita ke tipe data ukuran tetap seperti char dan nchar . Selain spasi yang diisi, menyetelnya ke NULL akan tetap memiliki ukuran penyimpanan yang sama dengan ukuran char kolom. Jadi, menyetel char (500) kolom ke NULL akan memiliki ukuran 500, bukan nol atau 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
Pada kode di atas, data dimaksimalkan berdasarkan ukuran char dan varchar kolom. Memeriksa ukuran baris mereka menggunakan DATALENGTH juga akan menunjukkan jumlah ukuran setiap kolom. Sekarang mari kita atur kolom ke NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Selanjutnya, kami mengkueri baris menggunakan DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Menurut Anda, apa ukuran data setiap kolom? Lihat Gambar 14.
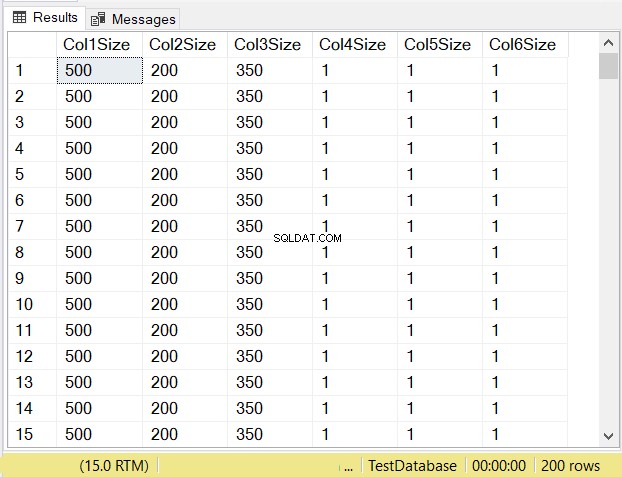
Lihatlah ukuran kolom dari 3 kolom pertama. Kemudian bandingkan dengan kode di atas saat tabel dibuat. Ukuran data kolom NULL sama dengan ukuran kolom. Sementara itu, varchar kolom ketika NULL memiliki ukuran data 1.
Hal Terburuk yang Bisa Terjadi
Selama mendesain tabel, char . yang dapat dibatalkan kolom, ketika disetel ke NULL, akan tetap memiliki ukuran penyimpanan yang sama. Mereka juga akan menggunakan halaman dan RAM yang sama. Jika Anda tidak mengisi seluruh kolom dengan karakter, pertimbangkan untuk menggunakan varchar sebagai gantinya.
Apa Selanjutnya?
Jadi, apakah pilihan Anda dalam tipe data server SQL dan ukurannya penting? Poin yang disajikan di sini harus cukup untuk membuat poin. Jadi, apa yang bisa Anda lakukan sekarang?
- Luangkan waktu untuk meninjau database yang Anda dukung. Mulailah dengan yang termudah jika Anda memiliki beberapa di piring Anda. Dan ya, luangkan waktu, bukan cari waktu. Dalam pekerjaan kami, hampir tidak mungkin menemukan waktu.
- Tinjau tabel, prosedur tersimpan, dan apa pun yang berhubungan dengan tipe data. Perhatikan dampak positifnya saat mengidentifikasi masalah. Anda akan membutuhkannya saat atasan Anda bertanya mengapa Anda harus mengerjakan ini.
- Rencanakan untuk menyerang setiap area bermasalah. Ikuti metodologi atau kebijakan apa pun yang dimiliki perusahaan Anda dalam menangani masalah tersebut.
- Setelah masalah hilang, rayakan.
Kedengarannya mudah, tetapi kita semua tahu itu tidak. Kita juga tahu bahwa ada sisi cerah di akhir perjalanan. Itu sebabnya mereka disebut masalah - karena ada solusinya. Jadi, semangatlah.
Apakah Anda memiliki sesuatu untuk ditambahkan tentang topik ini? Beri tahu kami di bagian Komentar. Dan jika postingan ini memberi Anda ide cemerlang, bagikan di platform media sosial favorit Anda.