Saya sedang dalam proses merapikan rumah saya (terlambat di musim panas untuk mencoba dan menganggapnya sebagai pembersihan musim semi). Anda tahu, membersihkan lemari, memeriksa mainan anak-anak, dan mengatur ruang bawah tanah. Ini adalah proses yang menyakitkan. Ketika kami pindah ke rumah kami 10 tahun yang lalu, kami memiliki begitu banyak ruang. Sekarang saya merasa seperti ada barang di mana-mana, dan semakin sulit untuk menemukan apa yang sebenarnya saya cari dan butuh waktu lebih lama untuk membersihkan dan mengaturnya.
Apakah ini terdengar seperti database yang Anda kelola?
Banyak klien yang pernah saya tangani menangani pembersihan data sebagai renungan. Pada saat pelaksanaan, semua orang ingin menyelamatkan semuanya. “Kita tidak pernah tahu kapan kita mungkin membutuhkannya.” Setelah satu atau dua tahun seseorang menyadari ada banyak hal tambahan dalam database, tetapi sekarang orang takut untuk membuangnya. “Kami perlu memeriksa dengan Bagian Hukum untuk melihat apakah kami dapat menghapusnya.” Tetapi tidak ada yang memeriksa dengan Bagian Hukum, atau jika seseorang melakukannya, Bagian Hukum kembali ke pemilik bisnis untuk menanyakan apa yang harus disimpan, dan kemudian proyek terhenti. “Kami tidak bisa mencapai konsensus tentang apa yang bisa dihapus.” Proyek dilupakan, dan kemudian dua atau empat tahun kemudian, database tiba-tiba menjadi satu terabyte, sulit untuk dikelola, dan orang-orang menyalahkan semua masalah kinerja pada ukuran database. Anda mendengar kata-kata "partisi" dan "database arsip" dilemparkan, dan terkadang Anda hanya menghapus banyak data, yang memiliki masalah sendiri.
Idealnya Anda harus memutuskan strategi pembersihan Anda sebelum penerapan, atau dalam enam hingga dua belas bulan pertama setelah ditayangkan. Tapi karena kita sudah melewati tahap itu, mari kita lihat apa dampak data tambahan ini.
Metodologi Pengujian
Untuk mengatur panggung, saya mengambil salinan database Kredit dan mengembalikannya ke contoh SQL Server 2012 saya. Saya menjatuhkan tiga indeks nonclustered yang ada dan menambahkan dua indeks saya sendiri:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Saya kemudian menambah jumlah baris dalam tabel menjadi 14,4 juta, dengan memasukkan kembali kumpulan baris asli beberapa kali, sedikit mengubah tanggal:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Akhirnya, saya menyiapkan test harness untuk mengeksekusi serangkaian pernyataan terhadap database masing-masing empat kali. Pernyataan di bawah ini:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Sebelum setiap pernyataan saya mengeksekusi
DBCC DROPCLEANBUFFERS; GO
untuk membersihkan kolam penyangga. Jelas ini bukan sesuatu untuk dieksekusi terhadap lingkungan produksi. Saya melakukannya di sini untuk memberikan titik awal yang konsisten untuk setiap tes.
Setelah setiap eksekusi, saya meningkatkan ukuran tabel dbo.charge dengan memasukkan 14,4 juta baris yang saya mulai, tetapi saya meningkatkan charge_dt satu tahun untuk setiap eksekusi. Misalnya:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Setelah penambahan 14,4 juta baris, saya menjalankan kembali test harness. Saya mengulangi ini enam kali, pada dasarnya menambahkan enam "tahun" data. Tabel dbo.charge dimulai dengan data dari 1999, dan setelah penyisipan berulang berisi data hingga 2005.
Hasil
Hasil dari eksekusi dapat dilihat di sini:
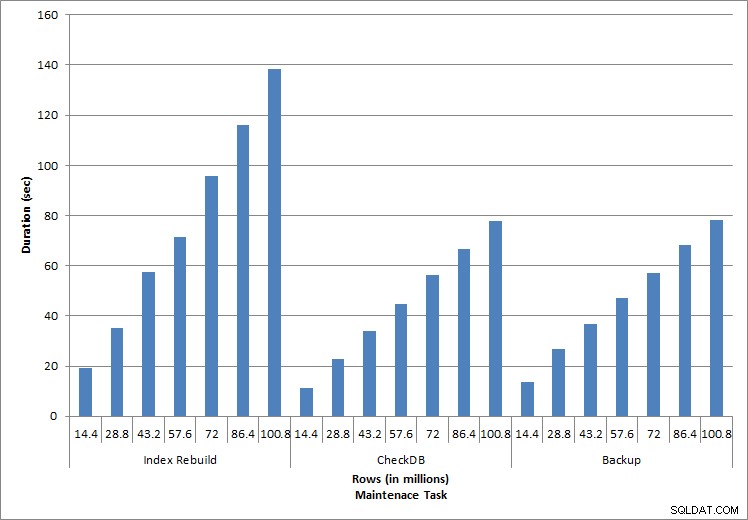
Durasi untuk Tugas Pemeliharaan
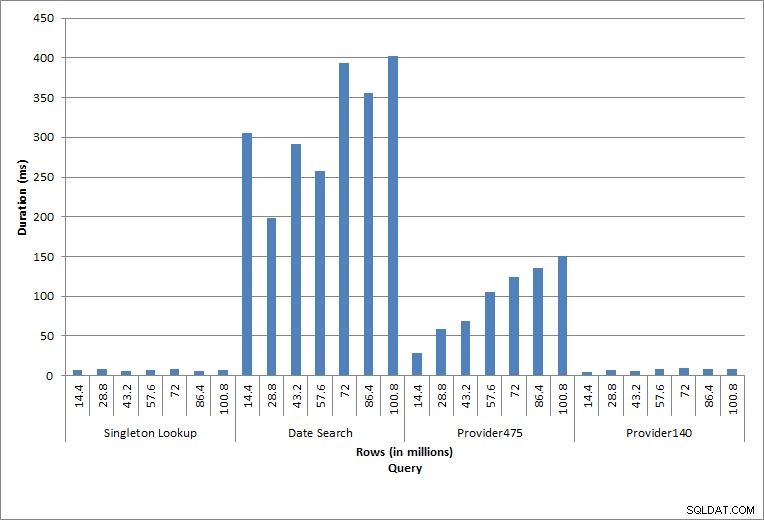
Durasi untuk Kueri
Pernyataan individu yang dieksekusi mencerminkan aktivitas basis data yang khas. Pembuatan ulang indeks, pemeriksaan integritas, dan pencadangan adalah bagian dari pemeliharaan basis data rutin. Kueri terhadap tabel biaya mewakili pencarian tunggal serta tiga variasi pemindaian rentang khusus untuk data dalam tabel.
Pembuatan Ulang Indeks, CHECKDB, dan Pencadangan
Seperti yang diharapkan untuk tugas pemeliharaan, durasi dan nilai IO meningkat karena lebih banyak baris ditambahkan ke database. Ukuran database meningkat dengan faktor 10, dan sementara durasi tidak meningkat pada tingkat yang sama, peningkatan yang konsisten terlihat. Setiap tugas pemeliharaan awalnya membutuhkan waktu kurang dari 20 detik untuk diselesaikan, tetapi karena lebih banyak baris ditambahkan, durasi tugas meningkat menjadi hampir 1 menit dan 20 detik untuk 100 juta baris (dan menjadi lebih dari 2 menit untuk pembangunan kembali indeks). Ini mencerminkan waktu tambahan yang diperlukan SQL Server untuk menyelesaikan tugas karena data tambahan.
Pencarian Tunggal
Kueri terhadap dbo.charge untuk charge_no tertentu selalu menghasilkan satu baris – dan akan menghasilkan satu baris terlepas dari nilai yang digunakan, karena charge_no adalah identitas unik. Ada variasi minimal untuk pencarian ini. Karena baris terus ditambahkan ke tabel, indeks dapat meningkat secara mendalam satu atau dua tingkat (lebih banyak saat tabel semakin lebar), oleh karena itu menambahkan beberapa IO, tetapi ini adalah pencarian tunggal dengan sangat sedikit IO.
Pemindaian Rentang
Kueri untuk rentang tanggal (charge_dt) diubah setelah setiap penyisipan untuk mencari data tahun terbaru untuk bulan Juli (mis. '2005-07-01' hingga '2005-07-01' untuk rangkaian pengujian terakhir), tetapi dikembalikan lebih dari 1,2 juta baris setiap kali. Dalam skenario dunia nyata, kami tidak mengharapkan jumlah baris yang sama dikembalikan untuk bulan yang sama, tahun demi tahun, kami juga tidak mengharapkan jumlah baris yang sama dikembalikan untuk setiap bulan dalam setahun. Tetapi jumlah baris dapat tetap dalam kisaran yang sama antara bulan, dengan sedikit peningkatan dari waktu ke waktu. Terdapat fluktuasi dalam durasi untuk kueri ini, tetapi tinjauan data IO yang diambil dari sys.dm_io_virtual_file_stats menunjukkan konsistensi dalam jumlah pembacaan.
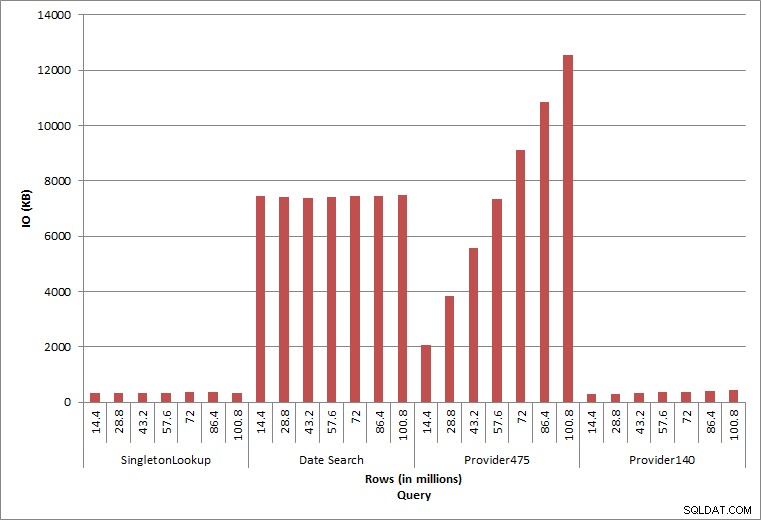
Query IO
Dua kueri terakhir, untuk dua nilai provider_no yang berbeda, menunjukkan efek sebenarnya dari penyimpanan data. Di tabel dbo.charge awal, provider_no 475 memiliki lebih dari 126.000 baris dan provider_no 140 memiliki lebih dari 1700 baris. Untuk setiap 14,4 juta baris yang ditambahkan, kira-kira jumlah baris yang sama untuk setiap provider_no telah ditambahkan. Di lingkungan produksi, jenis distribusi data ini tidak biasa, dan kueri untuk data ini mungkin berkinerja baik di tahun-tahun pertama solusi, tetapi dapat menurun seiring waktu karena lebih banyak baris ditambahkan. Durasi kueri meningkat dengan faktor lima (dari 31 md menjadi 153 md) antara eksekusi awal dan akhir untuk provider_no 475. Meskipun dampak ini mungkin tidak tampak signifikan, perhatikan peningkatan paralel dalam IO (di atas). Jika ini adalah kueri yang dijalankan dengan frekuensi tinggi, dan/atau ada kueri serupa yang dijalankan dengan frekuensi reguler, beban tambahan dapat bertambah dan memengaruhi penggunaan sumber daya secara keseluruhan. Selanjutnya, pertimbangkan dampaknya saat Anda bekerja dengan tabel yang memiliki miliaran baris, dan digunakan dalam kueri dengan gabungan kompleks, dan dampaknya pada tugas pemeliharaan rutin – dan sangat penting – Anda. Terakhir, pertimbangkan waktu pemulihan akun. Rencana pemulihan bencana Anda harus didasarkan pada waktu pemulihan, dan seiring bertambahnya ukuran basis data, basis data akan membutuhkan waktu lebih lama untuk dipulihkan secara keseluruhan. Jika Anda tidak secara teratur menguji dan mengatur waktu pemulihan, pemulihan dari bencana bisa memakan waktu lebih lama dari yang Anda kira.
Ringkasan
Contoh yang ditampilkan di sini adalah ilustrasi sederhana tentang apa yang dapat terjadi ketika strategi pengarsipan data tidak ditentukan selama implementasi basis data, dan ada banyak skenario lain untuk dijelajahi dan diuji. Data lama yang jarang, jika pernah, diakses berdampak lebih dari sekedar ruang pada disk. Ini dapat memengaruhi kinerja kueri dan durasi tugas pemeliharaan. Sebagai DBA yang mengelola beberapa database pada sebuah instans, satu database yang menyimpan data historis dapat memengaruhi kinerja dan tugas pemeliharaan database lain. Lebih lanjut, jika laporan dijalankan dengan data historis, hal ini dapat mendatangkan malapetaka pada lingkungan OLTP yang sudah sibuk.
Sejak awal, sangat penting bahwa umur data dalam database ditentukan, dan rencana tindakan dibuat. Untuk beberapa solusi, diperlukan untuk menyimpan semua data selamanya. Dalam hal ini, gunakan strategi untuk menjaga agar ukuran basis data dapat dikelola, misalnya:mengarsipkan data ke tabel terpisah atau basis data terpisah secara teratur. Jika data tidak perlu disimpan selama bertahun-tahun, terapkan strategi pembersihan yang menghapus data secara teratur. Dengan cara ini, Anda dapat membuang mainan yang tidak lagi dimainkan, pakaian yang tidak muat lagi, dan sampah acak yang tidak Anda gunakan setiap tiga bulan…bukannya sekali dalam 10 tahun.