Salah satu kasus penggunaan indeks yang difilter yang disebutkan dalam Books Online menyangkut kolom yang sebagian besar berisi NULLs nilai-nilai. Idenya adalah untuk membuat indeks yang difilter yang mengecualikan NULLs , menghasilkan indeks nonclustered yang lebih kecil yang membutuhkan lebih sedikit perawatan daripada indeks tanpa filter yang setara. Penggunaan lain yang populer dari indeks yang difilter adalah untuk memfilter NULLs dari UNIQUE index, memberikan perilaku yang mungkin diharapkan oleh pengguna mesin database lain dari UNIQUE default indeks atau batasan:keunikan diberlakukan hanya untuk non-NULLs nilai.
Sayangnya, pengoptimal kueri memiliki batasan terkait indeks yang difilter. Postingan ini membahas beberapa contoh yang kurang terkenal.
Tabel Contoh
Kami akan menggunakan dua tabel (A &B) yang memiliki struktur yang sama:kunci primer berkerumun pengganti, sebagian besar-NULLs kolom yang unik (mengabaikan NULLs ), dan kolom pengisi yang mewakili kolom lain yang mungkin ada di tabel nyata.
Kolom yang diminati sebagian besar-NULLs satu, yang saya nyatakan sebagai SPARSE . Opsi sparse tidak diperlukan, saya hanya memasukkannya karena saya tidak mendapatkan banyak kesempatan untuk menggunakannya. Bagaimanapun, SPARSE mungkin masuk akal dalam banyak skenario di mana data kolom diharapkan sebagian besar NULLs . Jangan ragu untuk menghapus atribut sparse dari contoh jika Anda mau.
CREATE TABLE dbo.TableA( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x); CREATE TABLE dbo.TableB( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x);
Setiap tabel berisi angka dari 1 hingga 2.000 di kolom data dengan tambahan 40.000 baris dengan kolom data NULLs :
-- Angka 1 - 2.000INSERT dbo.TableA WITH (TABLOCKX) (data)SELECT TOP (2000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))FROM sys.columns AS cCROSS JOIN sys.columns AS c2ORDER BY ROW_NUMBER() LEBIH (ORDER BY (SELECT NULL)); -- NULLsINSERT TOP (40000) dbo.TableA WITH (TABLOCKX) (data)SELECT CONVERT(bigint, NULL)FROM sys.columns AS cCROSS JOIN sys.columns AS c2; -- Salin ke dalam TableBINSERT dbo.TableB WITH (TABLOCKX) (data)SELECT ta.dataFROM dbo.TableA AS ta;
Kedua tabel mendapatkan UNIQUE indeks yang difilter untuk 2.000 non-NULLs nilai data:
BUAT INDEKS NONCLUSTERED UNIK uqAON dbo.TableA (data) DI MANA data TIDAK NULL; BUAT INDEKS NONCLUSTERED UNIK uqBON dbo.TableB (data) DI MANA data TIDAK NULL;
Output dari DBCC SHOW_STATISTICS merangkum situasinya:
DBCC SHOW_STATISTICS (TableA, uqA) WITH STAT_HEADER;DBCC SHOW_STATISTICS (TableB, uqB) WITH STAT_HEADER;

Contoh Kueri
Kueri di bawah ini melakukan gabungan sederhana dari dua tabel – bayangkan tabel berada dalam semacam hubungan induk-anak dan banyak kunci asing adalah NULL. Sesuatu di sepanjang garis itu.
PILIH ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data;
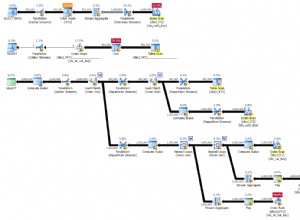
Rencana eksekusi default
Dengan SQL Server dalam konfigurasi defaultnya, pengoptimal memilih rencana eksekusi yang menampilkan gabungan loop bersarang paralel:
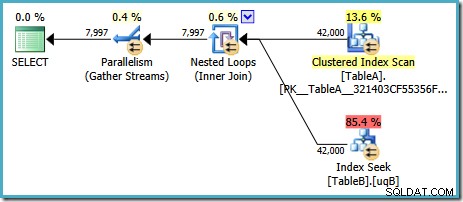
Paket ini memiliki perkiraan biaya 7,7768 unit pengoptimal ajaib™.
Namun, ada beberapa hal aneh tentang rencana ini. Pencarian Indeks menggunakan indeks terfilter kami pada tabel B, tetapi kueri didorong oleh Pemindaian Indeks Terkelompok tabel A. Predikat gabungan adalah uji kesetaraan pada kolom data, yang akan menolak NULLs (terlepas dari ANSI_NULLS pengaturan). Kami mungkin berharap pengoptimal akan melakukan beberapa penalaran lanjutan berdasarkan pengamatan itu, tetapi tidak. Paket ini membaca setiap baris dari tabel A (termasuk 40.000 NULLs ), melakukan pencarian ke indeks yang difilter pada tabel B untuk masing-masing indeks, mengandalkan fakta bahwa NULLs tidak akan cocok dengan NULLs dalam pencarian itu. Ini adalah usaha yang sia-sia.
Yang aneh adalah pengoptimal harus menyadari bahwa gabungan menolak NULLs untuk memilih indeks yang difilter untuk pencarian tabel B, tetapi tidak berpikir untuk memfilter NULLs dari tabel A terlebih dahulu – atau lebih baik lagi, cukup pindai NULLs -free filtered index pada tabel A. Anda mungkin bertanya-tanya apakah ini keputusan berbasis biaya, mungkin statistiknya tidak terlalu bagus? Mungkin kita harus memaksakan penggunaan indeks yang difilter dengan petunjuk? Mengindikasikan indeks yang difilter pada tabel A hanya menghasilkan rencana yang sama dengan peran terbalik – memindai tabel B dan mencari ke tabel A. Memaksa indeks yang difilter untuk kedua tabel menghasilkan kesalahan 8622 :pemroses kueri tidak dapat menghasilkan rencana kueri.
Menambahkan predikat NOT NULL
Mencurigai penyebabnya ada hubungannya dengan NULLs yang tersirat -penolakan predikat join, kita tambahkan eksplisit NOT NULL predikat untuk ON klausa (atau WHERE klausa jika Anda suka, itu datang ke hal yang sama di sini):
PILIH ta.data, tb.dataFROM dbo.TableA SEBAGAI taJOIN dbo.TableB AS tb ON ta.data =tb.data DAN ta.data BUKAN NULL;
Kami menambahkan NOT NULL periksa ke kolom tabel A karena rencana awal memindai indeks berkerumun tabel itu daripada menggunakan indeks terfilter kami (pencarian ke tabel B baik-baik saja – itu memang menggunakan indeks yang difilter). Kueri baru secara semantik persis sama dengan yang sebelumnya, tetapi rencana eksekusinya berbeda:
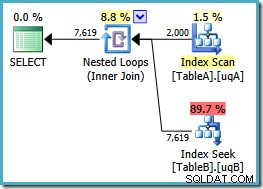
Sekarang kami memiliki pemindaian indeks terfilter yang diharapkan pada tabel A, menghasilkan 2.000 non-NULLs baris untuk mengarahkan pencarian loop bersarang ke tabel B. Kedua tabel menggunakan indeks terfilter kami tampaknya secara optimal sekarang:biaya paket baru hanya 0,362835 unit (turun dari 7.7768). Namun, kami dapat melakukan yang lebih baik.
Menambahkan dua predikat NOT NULL
NOT NULL yang berlebihan predikat untuk tabel A work wonders; apa yang terjadi jika kita menambahkan satu untuk tabel B juga?
PILIH ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data NOT NULL AND tb.data NOT NULL;
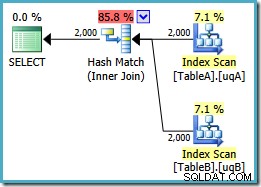
Kueri ini secara logika masih sama dengan dua upaya sebelumnya, tetapi rencana eksekusinya berbeda lagi:
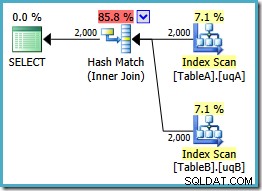
Rencana ini membuat tabel hash untuk 2.000 baris dari tabel A, lalu memeriksa kecocokan menggunakan 2.000 baris dari tabel B. Perkiraan jumlah baris yang dikembalikan jauh lebih baik daripada rencana sebelumnya (apakah Anda melihat perkiraan 7.619 di sana?) dan perkiraan biaya pelaksanaan telah turun lagi, dari 0,362835 menjadi 0,0772056 .
Anda dapat mencoba memaksa penggabungan hash menggunakan petunjuk pada kode asli atau tunggal-NOT NULL kueri, tetapi Anda tidak akan mendapatkan paket berbiaya rendah yang ditunjukkan di atas. Pengoptimal tidak memiliki kemampuan untuk sepenuhnya menjelaskan tentang NULLs -menolak perilaku gabungan karena berlaku untuk indeks terfilter kami tanpa kedua predikat yang berlebihan.
Anda boleh terkejut dengan hal ini – meskipun hanya gagasan bahwa satu predikat yang berlebihan tidak cukup (tentu saja jika ta.data adalah NOT NULL dan ta.data = tb.data , maka tb.data juga NOT NULL , kan?)
Masih belum sempurna
Agak mengejutkan melihat hash bergabung di sana. Jika Anda mengetahui perbedaan utama antara ketiga operator gabungan fisik, Anda mungkin tahu bahwa hash join adalah kandidat teratas di mana:
- Input yang telah diurutkan sebelumnya tidak tersedia
- Input hash build lebih kecil dari input probe
- Input probe cukup besar
Tidak satu pun dari hal ini benar di sini. Harapan kami adalah bahwa rencana terbaik untuk kueri dan kumpulan data ini adalah gabungan gabungan, mengeksploitasi input terurut yang tersedia dari dua indeks terfilter kami. Kami dapat mencoba mengisyaratkan penggabungan gabungan, mempertahankan dua tambahan ON predikat klausa:
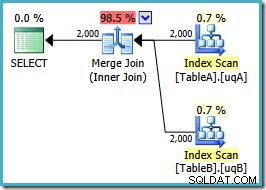
PILIH ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data NOT NULL AND tb.data NOT NULLOPTION (MERGE JOIN);Bentuk denah seperti yang kita harapkan:
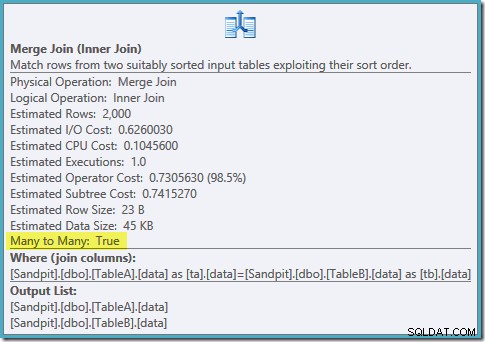
Pemindaian berurutan dari kedua indeks yang difilter, perkiraan kardinalitas yang bagus, fantastis. Hanya satu masalah kecil:rencana eksekusi ini jauh lebih buruk; perkiraan biaya telah melonjak dari 0,0772056 menjadi 0,741527 . Alasan lonjakan perkiraan biaya terungkap dengan memeriksa properti operator gabungan gabungan:
Ini adalah gabungan banyak-ke-banyak yang mahal, di mana mesin eksekusi harus melacak duplikat dari input luar di meja kerja, dan mundur seperlunya. Duplikat? Kami sedang memindai indeks unik! Ternyata pengoptimal tidak mengetahui bahwa indeks unik yang difilter menghasilkan nilai unik (hubungkan item di sini). Sebenarnya ini adalah satu-ke-satu bergabung, tetapi pengoptimal biaya seolah-olah banyak-ke-banyak, menjelaskan mengapa ia lebih memilih rencana bergabung hash.
Strategi Alternatif
Sepertinya kami terus menghadapi batasan pengoptimal saat menggunakan indeks yang difilter di sini (meskipun ini merupakan kasus penggunaan yang disorot di Buku Daring). Apa yang terjadi jika kita mencoba menggunakan tampilan?
Menggunakan Tampilan
Dua tampilan berikut hanya memfilter tabel dasar untuk menampilkan baris dengan kolom data
NOT NULL:CREATE VIEW dbo.VAWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableWHERE data IS NOT NULL;GOCREATE VIEW dbo.VBWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableBWHERE data IS NOT NULL;Menulis ulang kueri asli untuk menggunakan tampilan itu sepele:
PILIH v.data, v2.dataFROM dbo.VA SEBAGAI vJOIN dbo.VB AS v2 ON v.data =v2.data;Ingat kueri ini awalnya menghasilkan paket loop bersarang paralel dengan biaya 7,7768 unit. Dengan referensi tampilan, kami mendapatkan rencana eksekusi ini:
Ini persis sama dengan rencana hash join yang harus kami tambahkan
NOT NULLyang berlebihan predikat untuk mendapatkan indeks yang difilter (biayanya 0.0772056 unit seperti sebelumnya). Ini diharapkan, karena semua yang pada dasarnya kita lakukan di sini adalah mendorongNOT NULLtambahan extra predikat dari kueri ke tampilan.Mengindeks tampilan
Kami juga dapat mencoba mewujudkan tampilan dengan membuat indeks berkerumun unik pada kolom pk:
BUAT UNIK CLUSTERED INDEX cuq PADA dbo.VA (pk);BUAT UNIK CLUSTERED INDEX cuq PADA dbo.VB (pk);Sekarang kita dapat menambahkan indeks nonclustered unik pada kolom data yang difilter dalam tampilan yang diindeks:
BUAT INDEKS NONCLUSTERED UNIK ix PADA dbo.VA (data);BUAT INDEKS NONCLUSTERED UNIK ix PADA dbo.VB (data);Perhatikan pemfilteran dilakukan dalam tampilan, indeks nonclustered ini tidak difilter sendiri.
Rencana yang sempurna
Kami sekarang siap menjalankan kueri kami terhadap tampilan, menggunakan
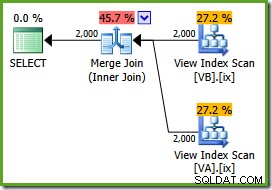
NOEXPANDpetunjuk tabel:PILIH v.data, v2.dataFROM dbo.VA AS v WITH (NOEXPAND)JOIN dbo.VB AS v2 WITH (NOEXPAND) PADA v.data =v2.data;Rencana eksekusi adalah:
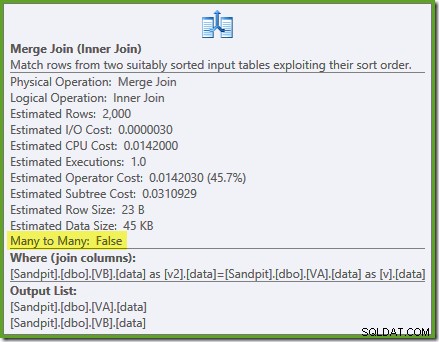
Pengoptimal dapat melihat tanpa filter indeks tampilan nonclustered unik, jadi penggabungan banyak ke banyak tidak diperlukan. Rencana eksekusi akhir ini memiliki perkiraan biaya 0,0310929 unit – bahkan lebih rendah dari rencana hash join (0,0772056 unit). Ini memvalidasi harapan kami bahwa penggabungan gabungan harus memiliki perkiraan biaya terendah untuk kueri ini dan kumpulan data sampel.
NOEXPANDpetunjuk diperlukan bahkan dalam Edisi Perusahaan untuk memastikan jaminan keunikan yang diberikan oleh indeks tampilan digunakan oleh pengoptimal.Ringkasan
Pos ini menyoroti dua batasan pengoptimal penting dengan indeks yang difilter:
- Predikat gabungan yang berlebihan mungkin diperlukan untuk mencocokkan indeks yang difilter
- Indeks unik yang difilter tidak memberikan informasi keunikan kepada pengoptimal
Dalam beberapa kasus, mungkin praktis untuk menambahkan predikat redundan ke setiap kueri. Alternatifnya adalah merangkum predikat tersirat yang diinginkan dalam tampilan yang tidak diindeks. Rencana pencocokan hash dalam posting ini jauh lebih baik daripada rencana default, meskipun pengoptimal harus dapat menemukan rencana penggabungan gabungan yang sedikit lebih baik. Terkadang, Anda mungkin perlu mengindeks tampilan dan menggunakan NOEXPAND petunjuk (tetap diperlukan untuk instans Edisi Standar). Masih dalam keadaan lain, tidak satu pun dari pendekatan ini akan cocok. Maaf soal itu :)