Untuk database baru yang dibuat di SQL Server, nilai default untuk opsi Statistik Pembaruan Otomatis adalah diaktifkan . Saya menduga bahwa sebagian besar DBA membiarkan opsi diaktifkan, karena memungkinkan pengoptimal untuk memperbarui statistik secara otomatis ketika mereka tidak valid, dan umumnya disarankan untuk membiarkannya diaktifkan. Statistik juga diperbarui ketika indeks dibangun kembali, dan meskipun tidak jarang statistik dikelola dengan baik melalui opsi statistik pembaruan otomatis dan melalui pembangunan kembali indeks, dari waktu ke waktu DBA mungkin perlu menyiapkan pekerjaan reguler untuk memperbarui statistik, atau kumpulan statistik.
Manajemen statistik kustom sering kali melibatkan perintah UPDATE STATISTICS, yang tampaknya cukup jinak. Ini dapat dijalankan untuk semua statistik untuk tabel atau tampilan yang diindeks, atau untuk statistik tertentu. Sampel default dapat digunakan, laju sampel tertentu atau jumlah baris untuk sampel dapat ditentukan, atau Anda dapat menggunakan nilai sampel yang sama yang digunakan sebelumnya. Jika statistik diperbarui untuk tabel atau tampilan terindeks, Anda dapat memilih untuk memperbarui semua statistik, hanya statistik indeks, atau hanya statistik kolom. Dan terakhir, Anda dapat menonaktifkan opsi statistik pembaruan otomatis untuk statistik.
Untuk sebagian besar DBA, pertimbangan terbesar mungkin kapan untuk menjalankan pernyataan UPDATE STATISTICS. Tetapi DBA juga memutuskan, secara sadar atau tidak, ukuran sampel untuk pembaruan. Ukuran sampel yang dipilih dapat memengaruhi kinerja pembaruan aktual, serta kinerja kueri.
Memahami Pengaruh Ukuran Sampel
Ukuran sampel default untuk STATISTIKA PEMBARUAN berasal dari algoritme non-linier, dan ukuran sampel menurun seiring ukuran tabel yang semakin besar, seperti yang ditunjukkan Joe Sack dalam postingannya, Uji Pengambilan Sampel Default Statistik Pembaruan Otomatis. Dalam beberapa kasus, ukuran sampel mungkin tidak cukup besar untuk menangkap informasi yang cukup menarik, atau kanan informasi, untuk histogram statistik, seperti yang dicatat oleh Conor Cunningham dalam posting Statistik Sample Rates-nya. Jika sampel default tidak membuat histogram yang baik, DBA dapat memilih untuk memperbarui statistik dengan laju pengambilan sampel yang lebih tinggi, hingga FULLSCAN (memindai semua baris dalam tabel atau tampilan terindeks). Tetapi seperti yang disebutkan Conor dalam postingnya, memindai lebih banyak baris membutuhkan biaya, dan DBA ditantang untuk memutuskan apakah akan menjalankan FULLSCAN untuk mencoba dan membuat histogram "terbaik", atau sampel persentase yang lebih kecil untuk meminimalkan dampak kinerja pembaruan.
Untuk mencoba dan memahami pada titik mana sampel membutuhkan waktu lebih lama daripada FULLSCAN, saya menjalankan pernyataan berikut terhadap salinan tabel SalesOrderDetail yang diperbesar menggunakan skrip Jonathan Kehayias:
| ID pernyataan | PERBARUI pernyataan STATISTIK |
|---|---|
| 1 | PERBARUI STATISTIK [Penjualan].[SalesOrderDetailEnlarged] WITH FULLSCAN; |
| 2 | PERBARUI STATISTIK [Penjualan].[SalesOrderDetailEnlarged]; |
| 3 | PERBARUI STATISTIK [Penjualan].[SalesOrderDetailEnlarged] DENGAN SAMPEL 10 PERSEN; |
| 4 | PERBARUI STATISTIK [Penjualan].[SalesOrderDetailEnlarged] DENGAN SAMPEL 25 PERSEN; |
| 5 | PERBARUI STATISTIK [Penjualan].[SalesOrderDetailEnlarged] DENGAN SAMPEL 50 PERSEN; |
| 6 | PERBARUI STATISTIK [Penjualan].[SalesOrderDetailEnlarged] DENGAN SAMPEL 75 PERSEN; |
Saya memiliki tiga salinan tabel SalesOrderDetailEnlarged, dengan karakteristik berikut*:
| Jumlah Baris | Jumlah Halaman | MAXDOP | Memori Maks | Penyimpanan | Mesin |
|---|---|---|---|---|---|
| 23.899.449 | 363.284 | 4 | 8 GB | SSD_1 | Laptop |
| 607.312.902 | 7,757,200 | 16 | 54GB | SSD_2 | Server Uji |
| 607.312.902 | 7,757,200 | 16 | 54GB | 15rb | Server Uji |
*Detail tambahan tentang perangkat keras ada di akhir posting ini.
Semua salinan tabel memiliki statistik berikut, dan tidak satu pun dari tiga statistik indeks yang menyertakan kolom:
| Statistik | Jenis | Kolom di Kunci |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Indeks | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Indeks | panduan baris |
| IX_SalesOrderDetailEnlarged_ProductID | Indeks | Id Produk |
| user_CarrierTrackingNumber | Kolom | CarrierTrackingNumber |
Saya menjalankan pernyataan STATISTIKA PEMBARUAN di atas masing-masing empat kali terhadap tabel SalesOrderDetailEnlarged di laptop saya, dan masing-masing dua kali terhadap tabel SalesOrderDetailEnlarged di TestServer. Pernyataan dijalankan dalam urutan acak setiap kali, dan cache prosedur dan cache buffer dihapus sebelum setiap pernyataan pembaruan. Durasi dan penggunaan tempdb untuk setiap set pernyataan (rata-rata) ada dalam grafik di bawah ini:
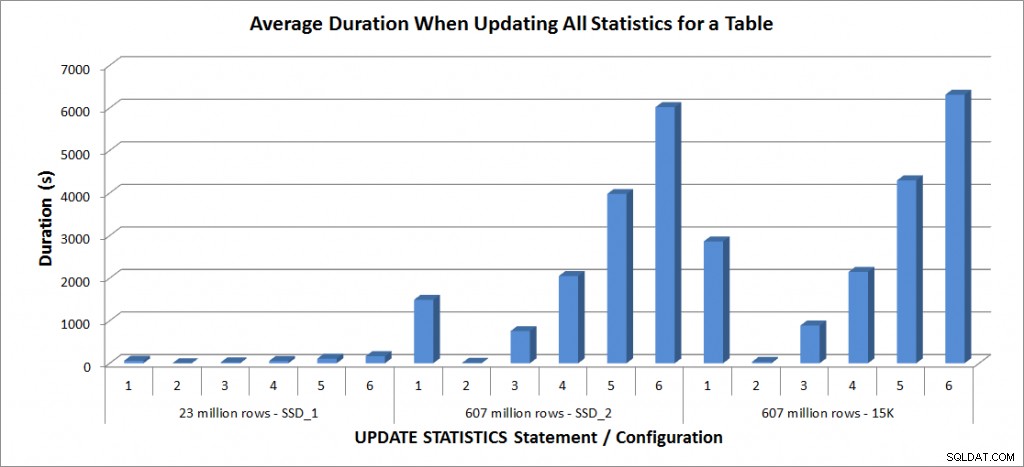
Durasi Rata-Rata – Perbarui Semua Statistik untuk SalesOrderDetailEnlarged
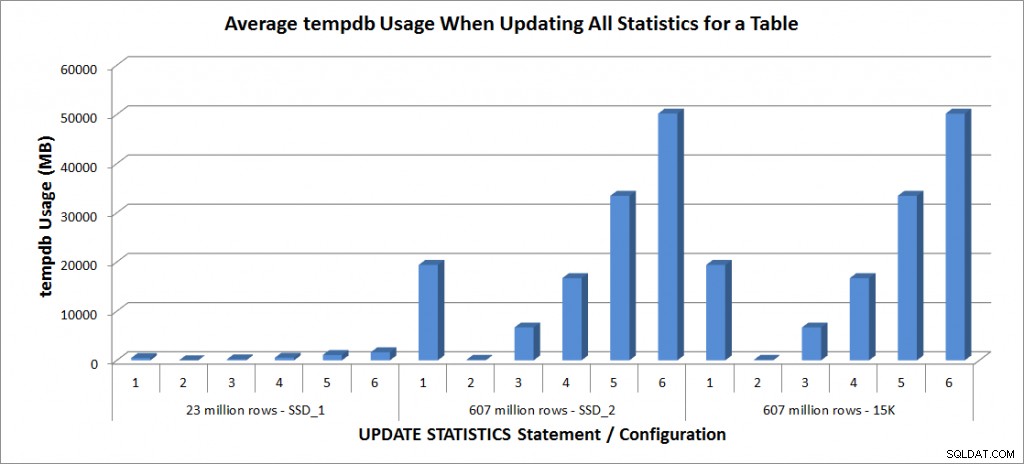
Penggunaan tempdb – Perbarui Semua Statistik untuk SalesOrderDetailEnlarged
Durasi untuk tabel 23 juta baris semuanya kurang dari tiga menit, dan dijelaskan secara lebih rinci di bagian selanjutnya. Untuk tabel pada disk SSD_2, pernyataan FULLSCAN membutuhkan waktu 1492 detik (hampir 25 menit) dan pembaruan dengan sampel 25% membutuhkan waktu 2051 detik (lebih dari 34 menit). Sebaliknya, pada disk 15K, pernyataan FULLSCAN membutuhkan waktu 2864 detik (lebih dari 47 menit) dan pembaruan dengan sampel 25% membutuhkan waktu 2147 detik (hampir 36 menit) – kurang dari waktu FULLSCAN. Namun, pembaruan dengan sampel 50% membutuhkan waktu 4296 detik (lebih dari 71 menit).
Penggunaan tempdb jauh lebih konsisten, menunjukkan peningkatan yang stabil seiring bertambahnya ukuran sampel, dan menggunakan lebih banyak ruang tempdb daripada FULLSCAN di suatu tempat antara 25% dan 50%. Yang penting di sini adalah STATISTIK PEMBARUAN berhasil gunakan tempdb, yang penting untuk diingat saat Anda mengukur tempdb untuk lingkungan SQL Server. Penggunaan Tempdb disebutkan dalam entri UPDATE STATISTICS BOL:
STATISTIK PEMBARUAN dapat menggunakan tempdb untuk mengurutkan sampel baris untuk membangun statistik.”
Dan efeknya didokumentasikan di pos Linchi Shea, Dampak kinerja:tempdb dan statistik pembaruan. Namun, itu bukan sesuatu yang selalu disebutkan selama diskusi ukuran tempdb. Jika Anda memiliki tabel besar dan melakukan pembaruan dengan FULLSCAN atau nilai sampel tinggi, perhatikan penggunaan tempdb.
Kinerja Pembaruan Selektif
Saya selanjutnya memutuskan untuk menguji pernyataan STATISTIKA PEMBARUAN untuk statistik lain di atas meja, tetapi membatasi pengujian saya pada salinan tabel dengan 23 juta baris. Enam variasi di atas dari pernyataan STATISTIK PEMBARUAN diulang empat kali masing-masing untuk statistik individu berikut dan kemudian dibandingkan dengan pembaruan untuk seluruh tabel:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Semua tes dijalankan dengan konfigurasi yang disebutkan di laptop saya, dan hasilnya ada di grafik di bawah ini:
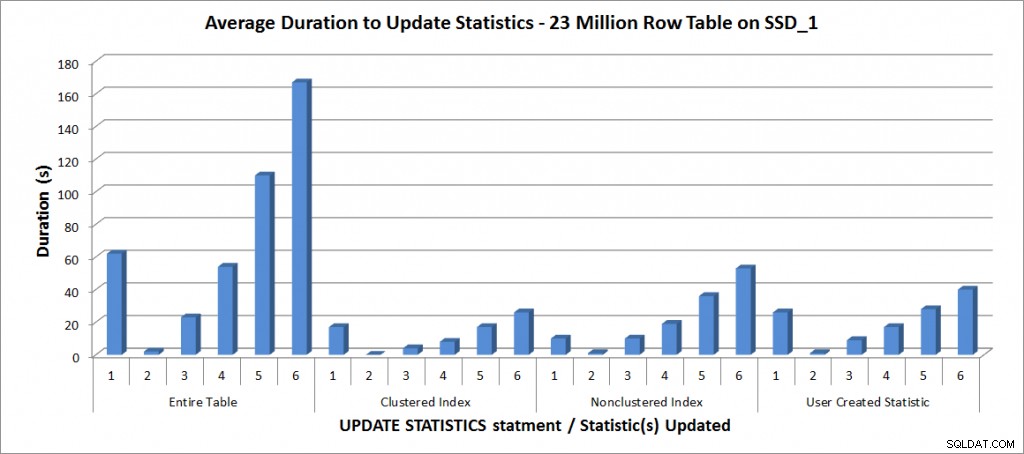
Durasi Rata-Rata untuk STATISTIK PEMBARUAN – Semua Statistik vs. Terpilih
Seperti yang diharapkan, pembaruan statistik individu membutuhkan waktu lebih sedikit daripada saat memperbarui semua statistik untuk tabel. Nilai di mana sampel diperbarui membutuhkan waktu lebih lama dari FULLSCAN bervariasi:
| PERBARUI pernyataan | durasi FULLSCAN | UPDATE pertama yang memakan waktu lebih lama |
|---|---|---|
| Seluruh Tabel | 62 | 50% – 110 detik |
| Indeks Tergugus | 17 | 75% – 26 detik |
| Indeks Tanpa Gugus | 10 | 25% – 19 detik |
| Statistik Buatan Pengguna | 26 | 50% – 28 detik |
Kesimpulan
Berdasarkan data ini, dan data FULLSCAN dari 607 juta tabel baris, tidak ada spesifik titik kritis di mana pembaruan sampel membutuhkan waktu lebih lama dari FULLSCAN; titik itu tergantung pada ukuran tabel dan sumber daya yang tersedia. Tapi datanya tetap berharga karena menunjukkan bahwa ada titik di mana sampel yang dinilai bisa memakan waktu lebih lama untuk ditangkap daripada FULLSCAN. Sekali lagi turun untuk mengetahui data Anda. Ini penting untuk tidak hanya memahami apakah tabel memerlukan pengelolaan statistik khusus, tetapi juga untuk memahami ukuran sampel yang ideal untuk membuat histogram yang berguna dan juga mengoptimalkan penggunaan sumber daya.
Spesifikasi
Spesifikasi laptop:Dell M6500, 1 Intel i7 (2.13GHz 4 core dan HT diaktifkan sehingga 8 core logis), memori 32 GB, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), file database yang disimpan di SSD Samsung 265GB PM810Spesifikasi Server Uji:Dell R720, 2 Intel E5-2670 (2.6GHz 8 core dan HT diaktifkan sehingga 16 core logis per soket), memori 64 GB, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), file database untuk satu tabel berada di dua kartu MLC Fusion-io Duo 640GB, file database untuk tabel lainnya ada di sembilan disk 15K RPM dalam larik RAID5