Bagaimana semua data opini publik itu disimpan? Kami memeriksa model data jajak pendapat.
Semua orang ingin tahu apa yang dipikirkan publik, dari politisi dan perusahaan hingga individu yang ingin tahu apa yang dipikirkan orang lain tentang topik tertentu. Pekerjaan semacam ini biasanya dilakukan oleh lembaga yang mengkhususkan diri dalam jenis penelitian itu.
Hari ini, kita akan melihat model data yang dapat digunakan agensi semacam itu untuk menyimpan semua data jajak pendapat yang relevan, mulai dari pertanyaan dan jawaban yang telah ditentukan sebelumnya hingga umpan balik yang sebenarnya. Data ini nantinya akan digunakan untuk membuat berbagai laporan. Jadi, mari kita mulai.
Ide
Jajak pendapat dapat dibuat di mana saja. Mereka dapat direncanakan dengan baik dan mencakup sampel yang representatif dari masyarakat (berdasarkan demografi). Atau Anda bisa melakukannya di tempat, mis. jika Anda ingin memprediksi hasil pemilu berdasarkan sampel (seperti exit poll), Anda mungkin akan bertanya kepada orang-orang di TPS bagaimana mereka memilih.
Di sisi lain, jika Anda ingin membuat jajak pendapat yang sama sebelum pemilihan, Anda mungkin akan memilih sampel dan menghubungi individu melalui telepon atau secara langsung. Biasanya, hanya ada beberapa pertanyaan untuk jenis jajak pendapat ini – beberapa untuk membahas demografi, dan lainnya untuk membahas apa yang benar-benar kami minati.
Jajak pendapat juga bisa jauh lebih kompleks, mis. jika Anda ingin mengetahui opini publik tentang suatu produk, mulai dari performa hingga pengemasannya.
Dalam artikel ini, saya tidak akan membahas cara memilih kumpulan sampel orang; alih-alih, saya akan fokus pada jajak pendapat itu sendiri, pertanyaannya, dan tanggapannya.
Model Data
Model data lembaga opini publik
Model ini terdiri dari tiga bidang subjek:
PollsQuestions & AnswersResult
Kami akan menjelaskan setiap bidang subjek sesuai urutannya.
Jajak Pendapat
Sebelum kita mulai mengajukan pertanyaan, kita perlu menentukan apa yang kita minati. Kita akan mendefinisikan jajak pendapat dan kuesioner di bagian ini, lalu menambahkan pertanyaan dan jawaban di bagian berikutnya.
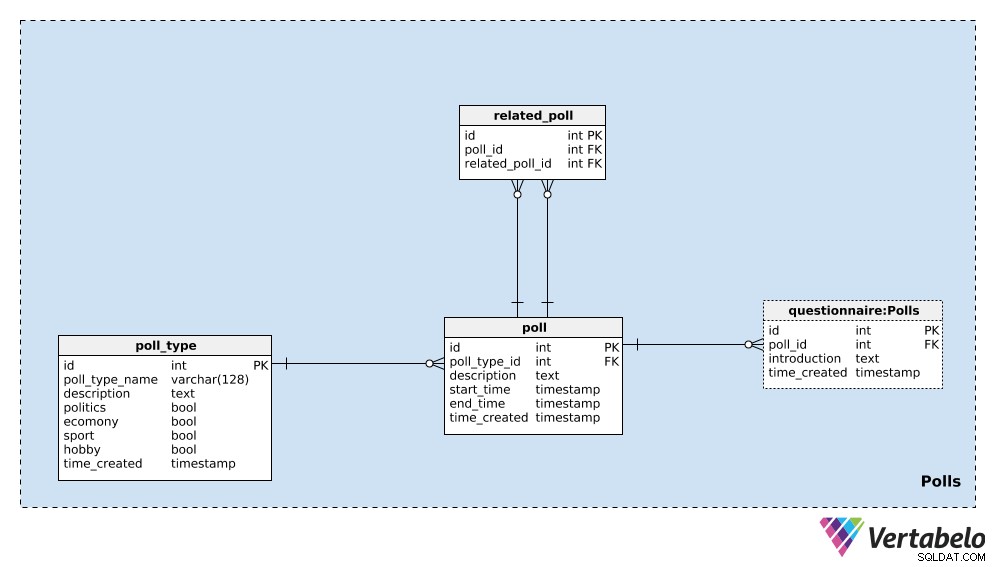
Kita akan mulai dengan poll_type kamus. Kami dapat berharap bahwa kami sebagian besar akan mengulangi jajak pendapat dengan jenis yang sama. Jenis yang paling umum mungkin adalah jajak pendapat pemilu, tetapi kami ingin dapat menambahkan jenis jajak pendapat baru di sepanjang jalan. Untuk setiap jenis polling, kami akan menyimpan poll_type_name UNIK dan gunakan description atribut untuk memberikan detail tambahan.
Empat bendera – politics , economy , sport , dan hobby – digunakan untuk menunjukkan jenis polling. Jajak pendapat dapat mencakup satu atau lebih topik tersebut; jika diperlukan, kami dapat membagi kategori ini ke dalam kamus terpisah dan memiliki hubungan banyak-ke-banyak antara kamus itu dan poll_type tabel.
Atribut terakhir dalam tabel ini adalah time_created . Ini menunjukkan saat ketika sebuah baris dimasukkan ke dalam tabel ini.
Hal berikutnya yang perlu kita lakukan adalah mendefinisikan satu poll . Ini adalah contoh tunggal, mis. “Pemilihan presiden Amerika Serikat 2020 – jajak pendapat April 2020” . Untuk setiap polling, kami akan menyimpan detail berikut:
poll_type_id– Referensi kepoll_type.description– Semua detail terkait jajak pendapat ini, dalam format tekstual.start_timedanend_time– Waktu mulai dan berakhir yang ditentukan, selama polling ini dilakukan.time_created– Momen sebenarnya saat polling ini dibuat.
Jajak pendapat dapat terkait satu sama lain. Dalam contoh “Pemilu presiden Amerika Serikat 2020 – jajak pendapat April 2020” , kita bisa melakukan polling yang sama bulan depan untuk melihat opini terbaru. Kami akan menyebutnya “Pemilu presiden Amerika Serikat 2020 – jajak pendapat Mei 2020” . Kedua jajak pendapat ini terkait karena hasilnya menunjukkan tren. Untuk membangun hubungan itu, kita akan menggunakan related_poll tabel dalam model kami. Ini hanya berisi pasangan UNIK poll_id – related_poll_id , yang menunjukkan jajak pendapat dan pendahulunya.
Perhatikan bahwa kita dapat menggunakan tabel ini untuk menyimpan semua polling yang terkait dengan cara apa pun, bukan hanya pendahulu/penerus. Jika kita ingin mendefinisikan hubungan yang berbeda, kita perlu menambahkan kamus lain – tetapi kita tidak akan melakukannya di artikel ini.
Tabel terakhir di bidang subjek ini adalah questionnaire meja. Dalam kebanyakan kasus, setiap jajak pendapat akan memiliki tepat satu kuesioner, tetapi saya ingin membiarkan opsi bahwa kita dapat memiliki lebih dari satu jika diperlukan. Oleh karena itu, saya telah menggunakan tabel terpisah. Di tabel ini, kami hanya akan menyimpan ID polling terkait (poll_id ), sebuah introduction menjelaskan kuesioner itu, dan stempel waktu saat catatan dimasukkan (time_created ).
Pertanyaan &Jawaban
Sekarang kami siap untuk membuat semua detail kuesioner. Kami juga dapat membuat daftar semua pertanyaan yang ingin kami ajukan serta semua jawaban yang telah ditentukan sebelumnya.
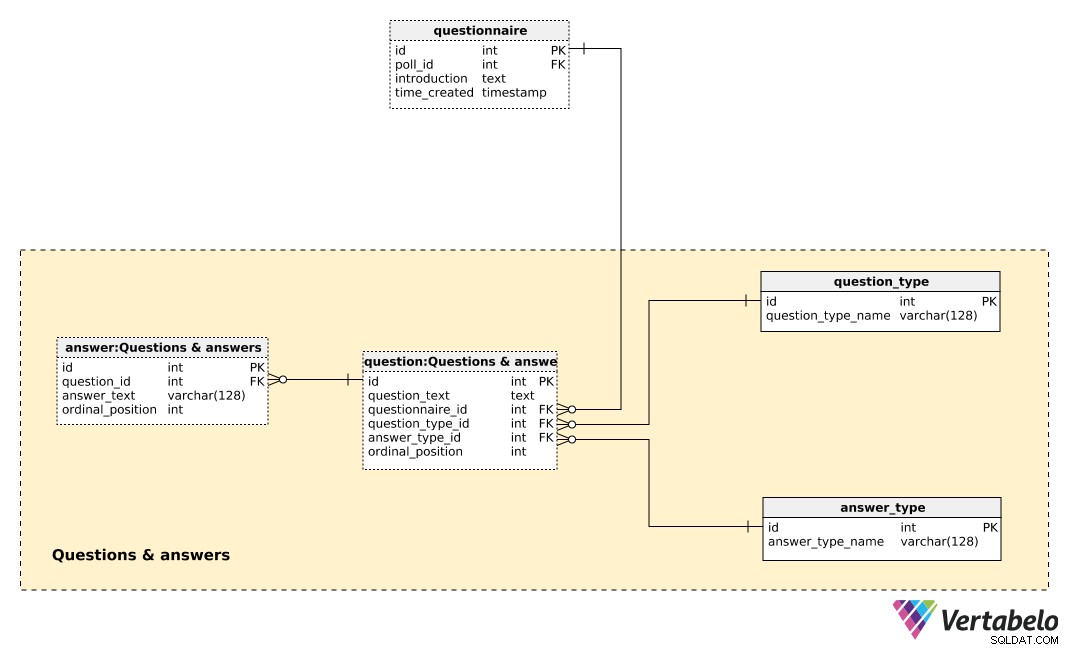
Tabel pusat di area subjek ini adalah question meja. Setiap pertanyaan ditentukan oleh detail berikut:
question_text– Sebuah teks yang akan ditampilkan kepada setiap individu yang disurvei.questionnaire_id– Referensi yang menunjukkan kuesioner pertanyaan ini.question_type_id– Referensi yang menunjukkanquestion_type, yang secara UNIK dilambangkan denganquestion_type_name. Ini pada dasarnya adalah kategori, mis. “demografi”, “opini”, “kontrol”, dll. Ini akan memungkinkan kita untuk memisahkan pertanyaan demografis dan opini dan menemukan korelasi di antara keduanya.answer_type_id– Referensi untuk jenis jawaban yang akan digunakan untuk pertanyaan ini. Setiapanswer_typesecara UNIK ditentukan olehanswer_type_namedan menunjukkan bagaimana jawabannya ditampilkan. Beberapa jenis yang diharapkan adalah “terbuka”, “daftar”, “kotak centang”, dan “banyak”.ordinal_position– Nilai ini menunjukkan posisi pertanyaan ini dalam kuesioner. Bersama denganquestionnaire_id, itu membentuk kunci alternatif dari tabel ini.
Daftar semua jawaban yang telah ditentukan sebelumnya disimpan di answer meja. Jika jenis pertanyaan tidak terbuka (yaitu teks tidak akan dimasukkan oleh individu), kami akan memiliki serangkaian jawaban yang telah ditentukan sebelumnya. Untuk setiap jawaban, kami akan menentukan pertanyaan yang menjadi miliknya (question_id ), answer_text , dan ordinal_position dari jawaban itu di dalam pertanyaan itu. Sekali lagi, sepasang UNIK – kali ini question_id – ordinal_position – membentuk kunci alternatif dari tabel ini.
Hasil
Di dua bidang subjek sebelumnya, kami telah mendefinisikan semua yang kami butuhkan untuk membuat polling dan mulai mengajukan pertanyaan. Sekarang kita perlu mendefinisikan struktur data untuk menyimpan jawaban yang sebenarnya.
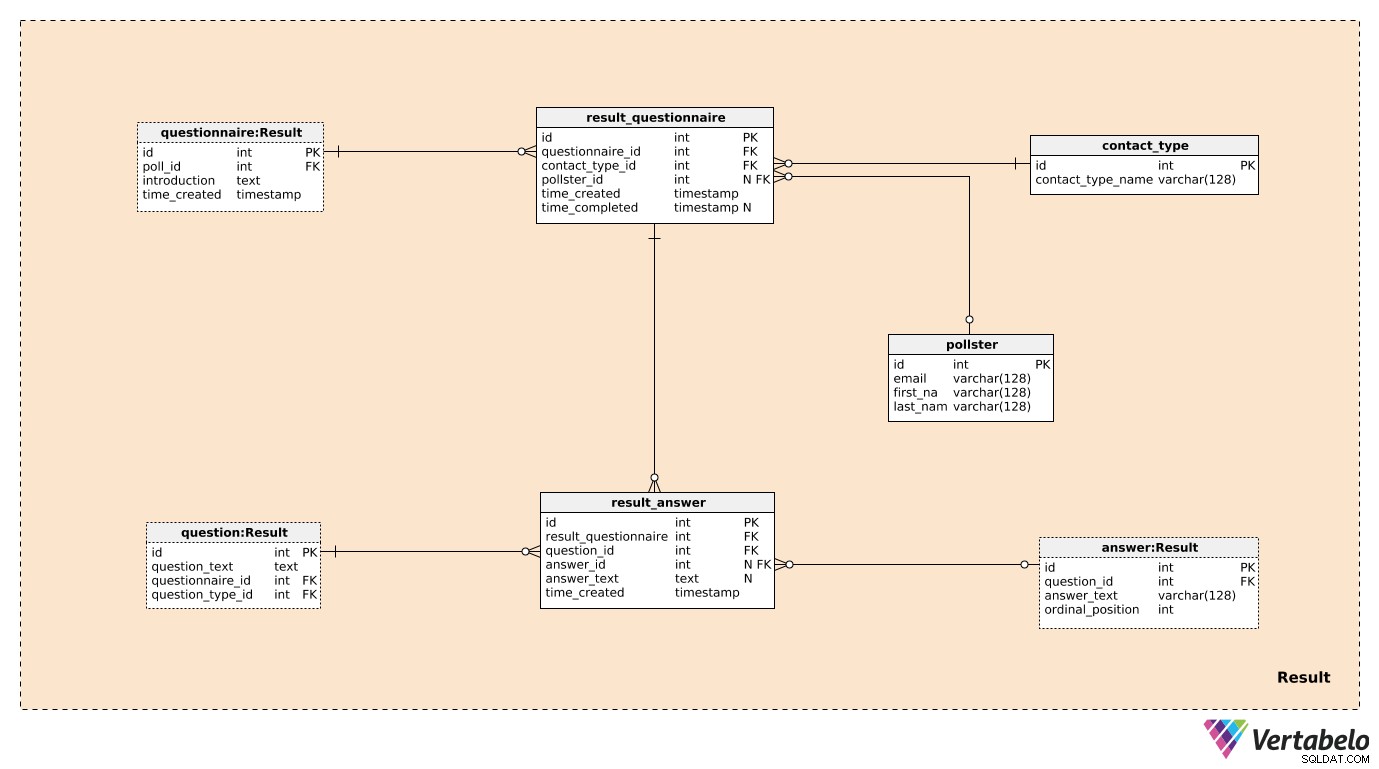
Tiga dari tujuh tabel di Result area subjek sebelumnya disebutkan dan dijelaskan. Ini adalah questionnaire , question , dan answer . Empat tabel yang tersisa digunakan untuk menyimpan apa yang benar-benar kita minati.
Kami akan membuat satu catatan di result_questionnaire tabel untuk setiap individu yang mengambil bagian dalam jajak pendapat. questionnaire_id berikan esus semua informasi tentang jajak pendapat yang relevan. contact_type_id adalah referensi ke contact_type kamus. Nilai dalam tabel ini menjelaskan cara kita berinteraksi dengan orang ini. Nilai-nilai ini secara UNIK ditentukan oleh contact_type_name nilai dan dapat berupa sesuatu seperti “telepon”, “secara langsung”, “email”, “formulir web”, dll.
pollster_id atribut adalah referensi ke poll tabel, yang memberikan info tentang siapa yang melakukan jajak pendapat yang sebenarnya. Untuk setiap poll , kami hanya akan menyimpan email UNIK dan first_name mereka dan last_name . time_created atribut menunjukkan waktu sebenarnya ketika catatan ini dibuat, sedangkan time_completed akan ditetapkan pada saat survei ini selesai. (Sampai saat itu, itu akan menjadi NULL).
Tabel terakhir dalam model adalah result_answer meja. Seperti namanya, di sinilah kami akan menyimpan tanggapan aktual yang kami dapatkan dari pengambil survei. Untuk setiap record dalam tabel ini, kita akan memiliki:
result_questionnaire_id– Referensi ke kuesioner yang relevan.question_id– Referensi yang menunjukkan pertanyaan yang dijawab oleh respons ini.answer_id– Referensi ke jawaban yang digunakan untuk menjawab pertanyaan ini. Atribut ini akan berisi nilai NULL saat pertanyaan bertipe “terbuka” (karena tidak ada jawaban yang telah ditentukan untuk dipilih).answer_text– Teks yang disisipkan untuk menjawab pertanyaan ini. Atribut ini akan berisi nilai saat pertanyaan "terbuka"; dalam semua kasus lain, itu akan menjadi NULL.time_created– Waktu sebenarnya saat jawaban ini dimasukkan ke dalam sistem kami.
Kemungkinan Peningkatan
Sejauh ini, kami telah membahas bagaimana kami dapat menyimpan data polling. Kami belum membahas apa yang akan kami lakukan dengan data setelah jajak pendapat ditutup. Kami dapat berharap bahwa kami tidak akan membutuhkan data lama di masa depan, setidaknya tidak dalam database operasional kami. Oleh karena itu, kita dapat melakukan dua hal:
- Simpan ringkasan polling dalam tabel terpisah di database operasional. Ini akan membuat informasi tersebut tetap tersedia jika kami ingin melihat apa yang terjadi dengan jajak pendapat serupa.
- Simpan semua data polling dalam database cadangan yang memiliki struktur yang sama dengan database operasional. Ini akan memungkinkan kami mengakses detail saat kami membutuhkannya.
Kami juga dapat membuat gudang data untuk menyimpan hasil polling, tetapi itu tidak akan diperlukan jika kami telah melakukan tugas yang dijelaskan dalam dua butir poin.
Bagaimana Pendapat Anda tentang Model Data Jajak Pendapat Kami?
Kami ingin mendengar pendapat Anda tentang apa yang dapat kami ubah untuk meningkatkan model data jajak pendapat. Apakah Anda memiliki pengalaman industri? Apakah Anda pikir kami melewatkan sesuatu? Apakah Anda akan menambahkan atau menghapus sesuatu? Menantikan untuk mendengar pendapat Anda.