SQL Server menawarkan dua metode pengumpulan data diagnostik dan pemecahan masalah tentang beban kerja yang dijalankan terhadap server:SQL Trace dan Extended Events. Mulai dari SQL Server 2012, implementasi Extended Events menyediakan kemampuan pengumpulan data yang sebanding dengan SQL Trace dan dapat digunakan untuk perbandingan overhead yang ditimbulkan oleh dua fitur ini. Dalam artikel ini kita akan melihat membandingkan "overhead pengamat" yang terjadi saat menggunakan SQL Trace dan Extended Events dalam berbagai konfigurasi untuk menentukan dampak kinerja yang mungkin dimiliki pengumpulan data pada beban kerja kami melalui penggunaan beban kerja replay tangkap dan Putar Ulang Terdistribusi.
Lingkungan pengujian
Lingkungan pengujian terdiri dari enam mesin virtual, satu pengontrol domain, satu server edisi SQL Server 2012 Enterprise, dan empat server klien dengan layanan klien Putar Ulang Terdistribusi yang diinstal di dalamnya. Konfigurasi host yang berbeda diuji untuk artikel ini dan hasil serupa dihasilkan dari tiga konfigurasi berbeda yang diuji berdasarkan rasio dampak. Server edisi SQL Server Enterprise dikonfigurasi dengan 4 vCPU dan RAM 4 GB. Lima server yang tersisa dikonfigurasi dengan 1 vCPU dan RAM 1GB. Layanan pengontrol Pemutaran Ulang Terdistribusi dijalankan di server edisi SQL Server 2012 Enterprise karena memerlukan lisensi Perusahaan untuk menggunakan lebih dari satu klien untuk pemutaran ulang.
Uji beban kerja
Beban kerja pengujian yang digunakan untuk pengambilan replay adalah beban kerja AdventureWorks Books Online yang saya buat tahun lalu untuk menghasilkan beban kerja tiruan terhadap SQL Server. Beban kerja ini menggunakan kueri contoh dari Books Online terhadap keluarga database AdventureWorks dan didorong oleh PowerShell. Beban kerja diatur pada masing-masing dari empat klien replay dan dijalankan dengan empat koneksi total ke SQL Server dari masing-masing server klien untuk menghasilkan rekaman jejak replay 1GB. Jejak replay dibuat menggunakan template TSQL_Replay dari SQL Server Profiler, diekspor ke skrip dan dikonfigurasi sebagai pelacakan sisi server ke file. Setelah file pelacakan replay ditangkap, file tersebut diproses sebelumnya untuk digunakan dengan Distributed Replay dan kemudian data replay digunakan sebagai beban kerja replay untuk semua pengujian.
Konfigurasi ulang
Operasi replay dikonfigurasi untuk menggunakan konfigurasi mode stres untuk mendorong jumlah maksimum beban terhadap contoh uji SQL Server. Selain itu, konfigurasi menggunakan skala waktu berpikir dan menghubungkan yang dikurangi, yang menyesuaikan rasio waktu antara awal pelacakan replay dan ketika suatu peristiwa benar-benar terjadi ketika itu diputar ulang selama operasi replay, untuk memungkinkan acara diputar ulang di skala maksimum. Skala stres untuk replay juga dikonfigurasi per spid. Rincian file konfigurasi untuk operasi replay adalah sebagai berikut:
<?xml version="1.0" encoding="utf-8"?>
<Options>
<ReplayOptions>
<Server>SQL2K12-SVR1</Server>
<SequencingMode>stress</SequencingMode>
<ConnectTimeScale>1</ConnectTimeScale>
<ThinkTimeScale>1</ThinkTimeScale>
<HealthmonInterval>60</HealthmonInterval>
<QueryTimeout>3600</QueryTimeout>
<ThreadsPerClient>255</ThreadsPerClient>
<EnableConnectionPooling>Yes</EnableConnectionPooling>
<StressScaleGranularity>spid</StressScaleGranularity>
</ReplayOptions>
<OutputOptions>
<ResultTrace>
<RecordRowCount>No</RecordRowCount>
<RecordResultSet>No</RecordResultSet>
</ResultTrace>
</OutputOptions>
</Options> Selama setiap operasi replay, penghitung kinerja dikumpulkan dalam interval lima detik untuk penghitung berikut:
- Prosesor\% Waktu Prosesor\_Total
- SQL Server\SQL Statistics\Batch Requests/sec
Penghitung ini akan digunakan untuk mengukur beban server secara keseluruhan, dan karakteristik throughput dari setiap pengujian untuk perbandingan.
Uji konfigurasi
Total tujuh konfigurasi berbeda diuji dengan Replay Terdistribusi:
- Dasar
- Pelacakan Sisi Server
- Profiler di server
- Profil dari jarak jauh
- Acara Diperpanjang ke event_file
- Acara Diperpanjang ke ring_buffer
- Acara Diperpanjang ke event_stream
Setiap tes diulang tiga kali untuk memastikan bahwa hasilnya konsisten di seluruh tes yang berbeda dan untuk memberikan serangkaian hasil rata-rata untuk perbandingan. Untuk tes dasar awal, tidak ada pengumpulan data tambahan yang dikonfigurasi untuk contoh SQL Server, tetapi kumpulan data default yang dikirimkan dengan SQL Server 2012 dibiarkan diaktifkan:jejak default dan sesi acara system_health. Ini mencerminkan konfigurasi umum sebagian besar SQL Server, karena secara umum tidak disarankan agar pelacakan default atau sesi system_health dinonaktifkan karena manfaat yang mereka berikan kepada administrator basis data. Tes ini digunakan untuk menentukan dasar keseluruhan untuk perbandingan dengan tes di mana pengumpulan data tambahan sedang dilakukan. Pengujian yang tersisa didasarkan pada template TSQL_SPs yang dikirimkan bersama SQL Server Profiler dan mengumpulkan kejadian berikut:
- Audit Keamanan\Masuk Audit
- Audit Keamanan\Keluar Audit
- Sessions\ExistingConnection
- Prosedur Tersimpan\RPC:Memulai
- Prosedur Tersimpan\SP:Selesai
- Prosedur Tersimpan\SP:Memulai
- Prosedur Tersimpan\SP:StmtStarting
- TSQL\SQL:BatchStarting
Template ini dipilih berdasarkan beban kerja yang digunakan untuk pengujian, terutama kumpulan SQL yang ditangkap oleh SQL:BatchStarting event, dan kemudian sejumlah event menggunakan berbagai metode hierarchyid , yang ditangkap oleh SP:Starting , SP:StmtStarting , dan SP:Completed acara. Skrip pelacakan sisi server dibuat dari template menggunakan fungsi ekspor di SQL Server Profiler, dan satu-satunya perubahan yang dibuat pada skrip adalah menyetel maxfilesize parameter ke 500MB, aktifkan rollover file jejak, dan berikan nama file tempat jejak itu ditulis.
Pengujian ketiga dan keempat menggunakan SQL Server Profiler untuk mengumpulkan kejadian yang sama seperti pelacakan sisi server untuk mengukur kinerja overhead pelacakan menggunakan aplikasi Profiler. Pengujian ini dijalankan menggunakan SQL Profiler secara lokal di SQL Server dan dari jarak jauh dari klien terpisah untuk memastikan apakah ada perbedaan overhead dengan menjalankan Profiler secara lokal atau jarak jauh.
Pengujian terakhir menggunakan Peristiwa yang Diperpanjang mengumpulkan peristiwa yang sama, dan kolom yang sama berdasarkan sesi peristiwa yang dibuat menggunakan skrip konversi Trace to Extended Events saya untuk SQL Server 2012. Pengujian termasuk mengevaluasi event_file, ring_buffer, dan penyedia streaming baru di SQL Server 2012 secara terpisah untuk menentukan overhead yang mungkin dikenakan oleh setiap target pada kinerja server. Selain itu, sesi acara dikonfigurasi dengan opsi buffer memori default, tetapi diubah untuk menentukan NO_EVENT_LOSS untuk EVENT_RETENTION_MODE opsi untuk pengujian event_file dan ring_buffer agar sesuai dengan perilaku Trace sisi server ke file, yang juga menjamin tidak ada peristiwa yang hilang.
Hasil
Dengan satu pengecualian, hasil tes tidak mengejutkan. Tes dasar mampu melakukan beban kerja replay dalam tiga belas menit tiga puluh lima detik, dan rata-rata 2.345 permintaan batch per detik selama tes. Dengan Trace sisi server berjalan, operasi replay selesai dalam 16 menit dan 40 detik, yang merupakan penurunan kinerja sebesar 18,1%. Jejak Profiler memiliki kinerja terburuk secara keseluruhan, dan membutuhkan 149 menit ketika Profiler dijalankan secara lokal di server, dan 123 menit dan 20 detik ketika Profiler dijalankan dari jarak jauh, menghasilkan penurunan kinerja masing-masing 90,8% dan 87,6%. Pengujian Peristiwa yang Diperpanjang adalah yang berkinerja terbaik, membutuhkan waktu 15 menit dan 15 detik untuk event_file dan 15 menit dan 40 detik untuk target ring_buffer, menghasilkan penurunan kinerja 10,4% dan 11,6%. Hasil rata-rata untuk semua tes ditampilkan pada Tabel 1 dan dipetakan pada Gambar 2:
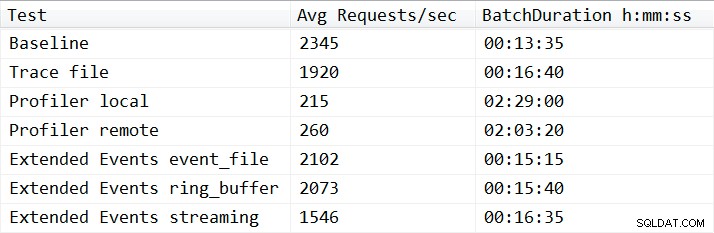
Tabel 1 – Hasil rata-rata dari semua pengujian
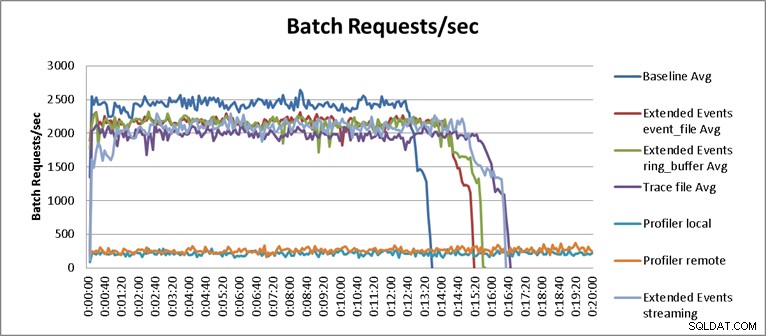
Gambar 2 – Bagan hasil
Tes streaming Acara yang Diperpanjang bukanlah hasil yang cukup adil dalam konteks tes yang dijalankan dan memerlukan sedikit penjelasan lebih lanjut untuk memahami hasilnya. Dari hasil tabel, kita dapat melihat bahwa pengujian streaming untuk Acara yang Diperpanjang selesai dalam enam belas menit tiga puluh lima detik, setara dengan penurunan kinerja 34,1%. Namun, jika kita memperbesar bagan dan mengubah skalanya, seperti yang ditunjukkan pada Gambar 3, kita akan melihat bahwa streaming memiliki dampak yang jauh lebih besar pada kinerja pada awalnya dan kemudian mulai tampil dengan cara yang mirip dengan pengujian Peristiwa yang Diperpanjang lainnya. :
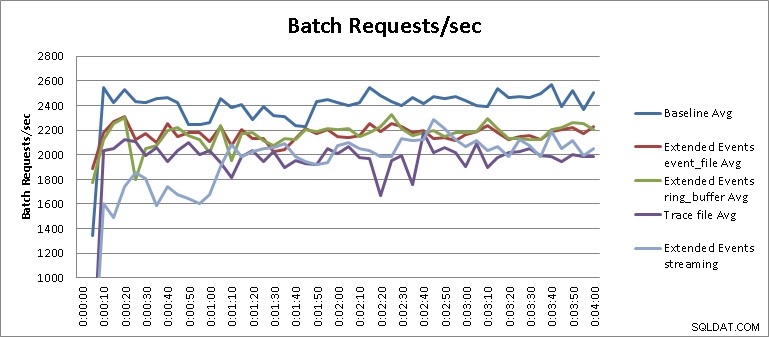
Gambar 3 – Hasil yang diperbesar
Penjelasan untuk ini ditemukan dalam desain target streaming Peristiwa yang Diperpanjang baru di SQL Server 2012. Jika buffer memori internal untuk event_stream terisi dan tidak digunakan oleh aplikasi klien dengan cukup cepat, Mesin Basis Data akan memaksa pemutusan sambungan event_stream untuk mencegah dampak parah pada kinerja server. Ini menghasilkan kesalahan yang muncul di SQL Server 2012 Management Studio yang mirip dengan kesalahan pada Gambar 4:
Gambar 4 – event_stream terputus oleh server
(Microsoft.SqlServer.XEvent.Linq)
Kesalahan 25726, tingkat keparahan 17, status 0 dinaikkan, tetapi tidak ada pesan dengan nomor kesalahan yang ditemukan di sys.messages. Jika kesalahan lebih besar dari 50000, pastikan pesan yang ditentukan pengguna ditambahkan menggunakan sp_addmessage.
(Microsoft SQL Server, Kesalahan:18054)
Kesimpulan
Semua metode pengumpulan data diagnostik dari SQL Server memiliki "overhead pengamat" yang terkait dengannya dan dapat memengaruhi kinerja beban kerja di bawah beban berat. Untuk sistem yang berjalan di SQL Server 2012, Peristiwa yang Diperpanjang menyediakan jumlah overhead yang paling sedikit dan menyediakan kemampuan yang serupa untuk peristiwa dan kolom sebagai SQL Trace (beberapa peristiwa di SQL Trace digabungkan ke dalam peristiwa lain di Peristiwa yang Diperpanjang). Jika SQL Trace diperlukan untuk menangkap data peristiwa – yang mungkin terjadi hingga alat pihak ketiga dikodekan ulang untuk memanfaatkan data Peristiwa yang Diperpanjang – Pelacakan sisi server ke file akan menghasilkan overhead kinerja paling sedikit. SQL Server Profiler adalah alat yang harus dihindari pada server produksi yang sibuk, seperti yang ditunjukkan oleh peningkatan sepuluh kali lipat dalam durasi dan pengurangan throughput yang signifikan untuk pemutaran ulang.
Sementara hasilnya tampaknya mendukung menjalankan SQL Server Profiler dari jarak jauh ketika Profiler harus digunakan, kesimpulan ini tidak dapat ditarik secara definitif berdasarkan pengujian spesifik yang dijalankan dalam skenario ini. Pengujian tambahan dan pengumpulan data harus dilakukan untuk menentukan apakah hasil Profiler jarak jauh adalah hasil dari pengalihan konteks yang lebih rendah pada contoh SQL Server, atau jika jaringan antara VM memainkan faktor dalam dampak kinerja yang lebih rendah pada pengumpulan jarak jauh. Inti dari pengujian ini adalah untuk menunjukkan overhead signifikan yang dikeluarkan Profiler, di mana pun Profiler dijalankan. Terakhir, streaming acara langsung di Acara yang Diperpanjang juga memiliki overhead yang tinggi ketika benar-benar terhubung dalam mengumpulkan data, tetapi seperti yang ditunjukkan dalam pengujian, Mesin Basis Data akan memutuskan streaming langsung jika ketinggalan acara untuk mencegah dampak yang parah pada kinerja server.