Pernahkah Anda menemukan situasi di mana Anda perlu mengelola keadaan entitas yang berubah seiring waktu? Ada banyak contoh di luar sana. Mari kita mulai dengan yang mudah:menggabungkan catatan pelanggan.
Misalkan kita menggabungkan daftar pelanggan dari dua sumber yang berbeda. Kami dapat membuat salah satu dari status berikut muncul:Duplikat Teridentifikasi – sistem telah menemukan dua entitas yang berpotensi duplikat; Duplikat yang Dikonfirmasi – pengguna memvalidasi bahwa dua entitas memang duplikat; atau Dikonfirmasi Unik – pengguna memutuskan kedua entitas itu unik. Dalam salah satu situasi ini, pengguna hanya memiliki keputusan ya-tidak untuk dibuat.
Tapi bagaimana dengan situasi yang lebih kompleks? Apakah ada cara untuk menentukan alur kerja aktual antar negara? Baca terus…
Bagaimana Hal Dapat Dengan Mudah Salah
Banyak organisasi perlu mengelola lamaran pekerjaan. Dalam model sederhana, Anda dapat memiliki tabel bernama JOB_APPLICATION , dan Anda dapat melacak status aplikasi menggunakan tabel data referensi yang berisi nilai seperti ini:
| Status Aplikasi |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Nilai-nilai ini dapat dipilih dalam urutan apa pun kapan saja. Itu bergantung pada pengguna akhir untuk memastikan bahwa pilihan yang logis dan benar dibuat pada setiap tahap. Tidak ada yang melarang urutan negara yang tidak logis.
Misalnya, katakanlah aplikasi telah ditolak. Status saat ini jelas adalah APPLICATION_REJECTED . Tidak ada yang dapat dilakukan di tingkat aplikasi untuk mencegah pengguna yang tidak berpengalaman kemudian memilih INVITED_TO_INTERVIEW atau keadaan tidak logis lainnya.
Yang dibutuhkan adalah sesuatu untuk memandu pengguna memilih status logis berikutnya, sesuatu yang mendefinisikan alur kerja logis .
Dan bagaimana jika Anda memiliki persyaratan yang berbeda untuk berbagai jenis lamaran pekerjaan? Misalnya, beberapa pekerjaan mungkin mengharuskan pelamar untuk mengikuti tes bakat. Tentu, Anda dapat menambahkan lebih banyak nilai ke daftar untuk menutupi ini, tetapi tidak ada dalam desain saat ini yang mencegah pengguna akhir membuat pilihan yang salah untuk jenis aplikasi yang dimaksud. Kenyataannya adalah ada alur kerja yang berbeda untuk konteks yang berbeda .
Hal lain yang perlu dipikirkan:apakah opsi yang tercantum benar-benar semua status ? Atau beberapa sebenarnya hasil ? Misalnya, tawaran pekerjaan dapat diterima atau ditolak oleh pelamar. Oleh karena itu, JOB_OFFER_MADE benar-benar memiliki dua hasil:JOB_OFFER_ACCEPTED dan JOB_OFFER_DECLINED .
Hasil lain bisa jadi tawaran pekerjaan ditarik. Anda mungkin ingin mencatat alasan penarikannya menggunakan kualifikasi. Jika Anda hanya menambahkan alasan ini ke daftar di atas, tidak ada yang memandu pengguna akhir untuk membuat pilihan logis.
Jadi, semakin kompleks status, hasil, dan kualifikasi, semakin Anda perlu mendefinisikan alur kerja dari sebuah proses .
Mengatur Proses, Status, dan Hasil
Penting untuk memahami apa yang terjadi dengan data Anda sebelum Anda mencoba memodelkannya. Anda mungkin pada awalnya cenderung berpikir bahwa ada hierarki tipe yang ketat di sini:
Ketika kita melihat lebih dekat pada contoh di atas, kita melihat bahwa INVITED_TO_INTERVIEW dan JOB_OFFER_MADE negara bagian memiliki kemungkinan hasil yang sama, yaitu ACCEPTED dan DECLINED . Ini memberi tahu kita bahwa ada hubungan banyak-ke-banyak antara negara dan hasil. Hal ini sering berlaku untuk negara bagian, hasil, dan kualifikasi lainnya.
Pada tingkat konseptual, inilah yang sebenarnya terjadi dengan metadata kami:
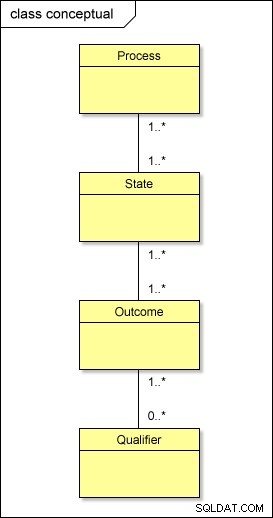
Jika Anda mengubah model ini ke dunia fisik menggunakan pendekatan standar, Anda akan memiliki tabel yang disebut PROCESS , STATE , OUTCOME , dan QUALIFIER; Anda juga perlu memiliki tabel perantara di antara mereka – PROCESS_STATE , STATE_OUTCOME , dan OUTCOME_QUALIFIER – untuk menyelesaikan hubungan banyak-ke-banyak . Ini memperumit desain.
Meskipun hierarki logis level (proses → status → hasil → kualifikasi) harus dipertahankan, ada cara yang lebih sederhana untuk mengatur metadata kami secara fisik.
Pola Alur Kerja
Diagram di bawah mendefinisikan komponen utama dari model database alur kerja:
Tabel kuning di sebelah kiri berisi metadata alur kerja, dan tabel biru di sebelah kanan berisi data bisnis.
Hal pertama yang harus ditunjukkan adalah bahwa entitas apa pun dapat dikelola tanpa memerlukan perubahan besar pada model ini. YOUR_ENTITIY_TO_MANAGE tabel adalah yang di bawah manajemen alur kerja. Dalam contoh kita, ini akan menjadi JOB_APPLICATION meja.
Selanjutnya, kita hanya perlu menambahkan wf_state_type_process_id kolom ke tabel apa pun yang ingin kita kelola. Kolom ini menunjuk ke proses alur kerja yang sebenarnya digunakan untuk mengelola entitas. Ini tidak sepenuhnya merupakan kolom kunci asing, tetapi memungkinkan kita untuk dengan cepat menanyakan WORKFLOW_STATE_TYPE untuk proses yang benar. Tabel yang akan berisi riwayat negara bagian adalah MANAGED_ENTITY_STATE . Sekali lagi, Anda akan memilih nama tabel spesifik Anda sendiri di sini dan memodifikasinya untuk kebutuhan Anda sendiri.
Metadata
Tingkat alur kerja yang berbeda ditentukan dalam WORKFLOW_LEVEL_TYPE . Tabel ini berisi berikut ini:
| Ketik Kunci | Deskripsi |
|---|---|
| PROSES | Proses alur kerja tingkat tinggi. |
| NEGARA | Status dalam proses. |
| HASIL | Bagaimana sebuah negara berakhir, hasilnya. |
| KUALIFIKASI | Sebuah kualifikasi opsional yang lebih mendetail untuk sebuah hasil. |
WORKFLOW_STATE_TYPE dan WORKFLOW_STATE_HIERARCHY membentuk struktur Bill of Material (BOM) klasik . Struktur ini, yang sangat deskriptif dari tagihan bahan manufaktur yang sebenarnya, cukup umum dalam pemodelan data. Itu dapat mendefinisikan hierarki atau diterapkan pada banyak situasi rekursif. Kami akan menggunakannya di sini untuk menentukan hierarki logis dari proses, status, hasil, dan qualifier opsional.
Sebelum kita dapat mendefinisikan hierarki, kita perlu mendefinisikan komponen individu. Ini adalah blok bangunan dasar kami. Saya hanya akan merujuk ini dengan TYPE_KEY (yang unik) demi singkatnya. Untuk contoh kami, kami memiliki:
| Jenis Tingkat Alur Kerja | Jenis Status Alur Kerja.Ketik Kunci |
|---|---|
| HASIL | LULUS |
| HASIL | GAGAL |
| HASIL | DITERIMA |
| HASIL | DITOLAK |
| HASIL | CANDIDATE_CANCELLED |
| HASIL | EMPLOYER_CANCELLED |
| HASIL | DITOLAK |
| HASIL | EMPLOYER_WITHDRAWN |
| HASIL | NO_SHOW |
| HASIL | DIPEKERJAKAN |
| HASIL | TIDAK_DIPERCAYA |
| NEGARA | APPLICATION_RECEIVED |
| NEGARA | APPLICATION_REVIEW |
| NEGARA | INVITED_TO_INTERVIEW |
| NEGARA | WAWANCARA |
| NEGARA | TEST_APTITUDE |
| NEGARA | SEEK_REFERENCES |
| NEGARA | BUAT_TAWARKAN |
| NEGARA | APPLICATION_CLOSED |
| PROSES | STANDARD_JOB_APPLICATION |
| PROSES | TECHNICAL_JOB_APPLICATION |
Sekarang kita dapat mulai mendefinisikan hierarki kita. Di sinilah kami mengambil blok bangunan kami dan menentukan struktur kami. Untuk setiap negara bagian, kami menentukan hasil yang mungkin. Faktanya, ini adalah aturan sistem alur kerja bahwa setiap status harus diakhiri dengan hasil:
| Jenis Induk – NEGARA | Tipe Anak – HASIL |
|---|---|
| APPLICATION_RECEIVED | DITERIMA |
| APPLICATION_RECEIVED | DITOLAK |
| APPLICATION_REVIEW | LULUS |
| APPLICATION_REVIEW | GAGAL |
| INVITED_TO_INTERVIEW | DITERIMA |
| INVITED_TO_INTERVIEW | DITOLAK |
| WAWANCARA | LULUS |
| WAWANCARA | GAGAL |
| WAWANCARA | CANDIDATE_CANCELLED |
| WAWANCARA | NO_SHOW |
| MAKE_OFFER | DITERIMA |
| MAKE_OFFER | DITOLAK |
| SEEK_REFERENCES | LULUS |
| SEEK_REFERENCES | GAGAL |
| APPLICATION_CLOSED | DIPEKERJAKAN |
| APPLICATION_CLOSED | TIDAK_DIPERCAYA |
| TEST_APTITUDE | LULUS |
| TEST_APTITUDE | GAGAL |
Proses kami hanyalah seperangkat keadaan yang masing-masing ada untuk jangka waktu tertentu. Pada tabel di bawah ini disajikan dalam urutan logis, tetapi ini tidak menentukan urutan pemrosesan yang sebenarnya.
| Jenis Induk – PROSES | Tipe Anak – STATES |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | WAWANCARA |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | WAWANCARA |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_CLOSED |
Ada poin penting yang harus dibuat mengenai hierarki BOM. Sama seperti bill of material fisik mendefinisikan rakitan dan sub-rakitan hingga komponen terkecil, kami memiliki pengaturan serupa dalam hierarki kami. Artinya, kita dapat menggunakan kembali 'rakitan' dan 'sub-rakitan'.
Sebagai contoh:Kedua STANDARD_JOB_APPLICATION dan TECHNICAL_JOB_APPLICATION proses memiliki INTERVIEW negara bagian . Selanjutnya, INTERVIEW negara bagian memiliki PASSED , FAILED , CANDIDATE_CANCELLED , dan NO_SHOW hasil ditentukan untuk itu.
Saat Anda menggunakan status dalam suatu proses, Anda secara otomatis mendapatkan hasil turunannya karena status tersebut sudah merupakan rakitan. Ini berarti bahwa hasil yang sama ada untuk kedua jenis lamaran pekerjaan di INTERVIEW panggung. Jika Anda menginginkan hasil wawancara yang berbeda untuk berbagai jenis lamaran pekerjaan, Anda perlu mendefinisikan, misalnya, TECHNICAL_INTERVIEW dan STANDARD_INTERVIEW menyatakan bahwa masing-masing memiliki hasil spesifiknya sendiri.
Dalam contoh ini, satu-satunya perbedaan antara kedua jenis lamaran pekerjaan adalah bahwa lamaran pekerjaan teknis mencakup tes bakat.
Sebelum Anda Pergi
Bagian 1 dari artikel dua bagian ini telah memperkenalkan pola database alur kerja. Ini telah menunjukkan bagaimana Anda dapat menggabungkannya untuk mengelola siklus hidup entitas apa pun di database Anda.
Bagian 2 akan menunjukkan kepada Anda cara mendefinisikan alur kerja yang sebenarnya menggunakan tabel konfigurasi tambahan. Di sinilah pengguna akan disajikan dengan langkah selanjutnya yang diizinkan. Kami juga akan mendemonstrasikan teknik untuk menyiasati penggunaan kembali 'rakitan' dan 'sub-rakitan' yang ketat di BOM.