Catatan:Artikel ini menampilkan migrasi model database relasional (RDB) ke skema bintang menggunakan Eclipse IDE for Voracity (dan produk yang disertakan), IRI Workbench, setelah pengenalan kedua arsitektur. Jika Anda tertarik untuk memigrasikan RDB atau data Anda ke model Data Vault 2.0, wizard Workbench baru akan debut di World Wide Data Vault Consortium pada Mei 2019; berlangganan blog IRI untuk mendapatkan petunjuk langkah demi langkah tersebut segera setelah dipublikasikan!
Data warehouse (DW) adalah kumpulan data yang diambil dari sistem operasional atau transaksional dalam bisnis, diubah untuk membersihkan inkonsistensi, dan kemudian diatur untuk mendukung analisis dan/atau pelaporan yang cepat. DW memerlukan skema, atau deskripsi logis dan representasi grafis dari database operasionalnya. Artikel ini menyentuh topik tersebut sambil memberikan panduan cara berpindah dari skema database relasional konvensional ke skema DW populer yang disebut skema bintang.
Skema Bintang vs. Relasional
Kebanyakan struktur data relasional diilustrasikan dalam diagram entity-relationship (ER). Diagram ER digunakan dalam pengembangan model konseptual untuk sistem manajemen database pemrosesan transaksi online (OLTP). Ini adalah sumber dari mana struktur tabel diterjemahkan.
Skema bintang, bagaimanapun, adalah standar yang diterima secara luas untuk struktur tabel yang mendasari gudang data. Bentuk bintangnya yang sederhana (ketika ER-diagramed) menunjukkan tabel fakta (berisi nilai transaksi atau ukuran) di tengah, dan tabel dimensi (berisi nilai deskriptif atau atributif) memancar darinya. Biasanya, tabel fakta dalam bentuk normal ketiga (3NF), sementara tabel dimensi didenormalisasi.
Perbedaan mendasar antara model entity-relational (ER) dan model bintang adalah bahwa:
- Model ER menggunakan struktur logika dan fisik untuk desain database yang dinormalisasi
- Model dimensi menggunakan struktur fisik untuk desain database yang didenormalisasi
Untuk melihat bagaimana perangkat lunak IRI dapat mende/menormalkan data melalui pivot baris-kolom, klik di sini.
Latar Belakang Proses Konversi
Dalam artikel ini, saya mendemonstrasikan cara mengonversi data dari model relasional menjadi bintang menggunakan pekerjaan yang harus Anda definisikan kurang lebih secara manual, tetapi dapat dibuat dan dijalankan secara otomatis, dan dimodifikasi dengan mudah.
Apa yang akan Anda lihat di sini adalah data 4GL IRI dan spesifikasi pekerjaan — dinyatakan dalam skrip “SortCL” [1] — yang memetakan data ke dalam tabel dimensi, dan menggabungkan data ke dalam tabel fakta pusat. SortCL adalah program pemetaan dan manipulasi data inti dalam platform ETL pengelolaan data dan pengelolaan data Voracity IRI. Namun, memahami metodologi dan pemetaan dalam tugas SortCL saya adalah kuncinya di sini, bukan sintaks skrip.
Eclipse GUI gratis, IRI Workbench, menyediakan editor SortCL yang sadar sintaks, serta garis besar dan dialog grafis, diagram alur kerja dan pemetaan, dan wizard pekerjaan intuitif, untuk membuat atau memodifikasi skrip ini secara otomatis jika Anda tidak ingin melakukannya dengan tangan. Untuk diketahui, IRI menggunakan metadata dan GUI yang sama untuk membuat profil dan membuat diagram DB, menghasilkan data pengujian, menjalankan ETL, memformat laporan, menutupi PII, menangkap data yang diubah, memigrasikan dan mereplikasi data, membersihkan dan memvalidasi data, dll.
Workbench menggunakan versi yang disempurnakan dari plugin Data Tools Platform (DTP) untuk Eclipse agar dapat terhubung ke database melalui JDBC, dan untuk mengaktifkan operasi SQL dan pertukaran metadata IRI dalam tampilan Data Source Explorer (DSE). Dalam hal ini, Workbench mendukung:
- pembuatan dan populasi tabel pengujian (sumber) Oracle yang dibatasi melalui SortCL (atau pekerjaan IRI RowGen , per artikel ini)
- pemetaan data tabel entitas ke dalam tabel Dimensi melalui SortCL
- pemetaan elemen fakta sebagai relasi n-ary untuk mengasosiasikan tabel dimensi prinsip; yaitu melakukan penggabungan multi-tabel di SortCL untuk membuat tabel Fakta
- populasi semua tabel target (skema bintang)
- Diagram ER dari skema sumber dan target
Tipe entitas dalam model relasional asli saya adalah:Dept, Emp, Project, Category, Item, Item_Use, dan Sale:
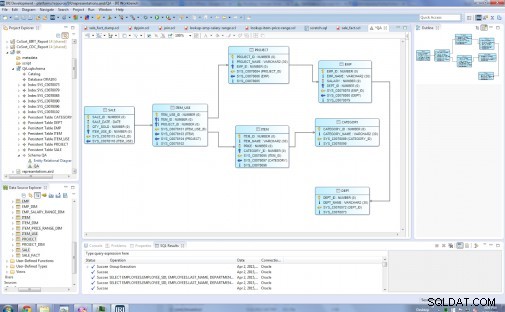
Sebelum …
Diagram berikutnya menunjukkan model Bintang akhir dengan delapan tabel dimensi dan satu tabel fakta. Tabel dimensi adalah: Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. Tabel fakta di tengah adalah Sale_Fact, yang berisi kunci untuk semua tabel dimensi.

… Setelah
Langkah Konversi
- Tentukan dan buat tabel Fakta
Struktur untuk tabel Sale_Fact ditampilkan dalam dokumen ini. Kunci utama adalah sale_id, dan atribut lainnya adalah kunci asing yang diwarisi dari tabel Dimensi. Saya menggunakan database Oracle (meskipun RDB apa pun berfungsi) yang terhubung ke Workbench DSE (melalui JDBC) dan SortCL untuk transformasi dan pemetaan data ( melalui ODBC). Saya membuat tabel saya dalam skrip SQL yang diedit di scrapbook SQL DSE dan dieksekusi di Workbench.
- Tentukan dan buat tabel Dimensi
Gunakan teknik dan metadata yang sama yang ditautkan di atas untuk membuat tabel Dimensi ini yang akan menerima data relasional yang dipetakan dari tugas SortCL pada langkah berikutnya:Category_Dim table, Dept to Dept_Dim, Project to Project_Dim, Item to Item_Dim, dan Emp to Emp_Dim. Anda dapat menjalankan program .SQL dengan semua logika CREATE sekaligus untuk membuat tabel.
- Pindahkan data tabel Entitas asli ke tabel Dimensi
Tentukan dan jalankan tugas SortCL yang ditampilkan di sini untuk memetakan data (pengujian yang dibuat oleh RowGen) dari skema relasional ke dalam tabel Dimensi untuk skema Bintang. Secara khusus, skrip ini memuat data dari tabel Kategori ke tabel Kategori_Dim, Dept ke Dept_Dim, Proyek ke Project_Dim, Item ke Item_Dim, dan Emp ke Emp_Dim.
- Isi Tabel Fakta
Gunakan SortCL untuk menggabungkan data dari tabel entitas Sale, Emp, Project, Item_Use, Item, Category asli untuk menyiapkan data untuk tabel Sale_Fact baru. Gunakan skrip (join job) kedua di sini.
Untuk meningkatkan contoh kami, kami juga akan menggunakan SortCL untuk memperkenalkan data dimensi baru ke dalam skema Bintang yang juga akan diandalkan oleh tabel Fakta saya. Anda dapat melihat tabel tambahan ini dalam diagram Bintang di atas yang tidak ada dalam skema relasional saya:Emp_Salary_Range_Dim dan Item_Price_Range_Dim. Tabel tersebut dibuat dalam file .SQL yang sama untuk tabel Fakta dan tabel Dimensi lainnya.
Tabel Fakta memerlukan data emp_salary_range_id dan item_price_range_id dari tabel ini untuk mewakili rentang nilai dalam tabel Dimensi tersebut. Ketika saya memuat nilai harga dimensi ke dalam gudang data, misalnya, saya ingin menetapkannya ke kisaran harga:
| Item_Price | Rentang_Id | Range_Name | Range_End |
|---|---|---|---|
| 1 | Rendah | 1 | 100 |
| 2 | Sedang | 101 | 500 |
| 3 | Tinggi | 501 | 999 |
Cara termudah untuk menetapkan ID rentang dalam skrip pekerjaan (yaitu menyiapkan data untuk tabel Sale_Fact saya) adalah dengan menggunakan pernyataan IF-THEN-ELSE di bagian output. Lihat artikel ini tentang mengelompokkan nilai untuk latar belakang.
Bagaimanapun, saya membuat seluruh pekerjaan ini dengan CoSort Pekerjaan Gabung Baru wizard di Workbench. Dan begitu saya menjalankannya, tabel fakta saya terisi:
 Tampilan tabel Sale_Fact di IRI Workbench DSE
Tampilan tabel Sale_Fact di IRI Workbench DSE
Kesimpulan
Keuntungan utama dari representasi data dimensional adalah mengurangi kompleksitas struktur database. Ini membuat database lebih mudah bagi orang untuk memahami dan menulis kueri dengan meminimalkan jumlah tabel, dan oleh karena itu, jumlah gabungan yang diperlukan. Seperti disebutkan sebelumnya, model dimensi juga mengoptimalkan kinerja kueri. Namun, ia memiliki kelemahan dan juga kekuatan. Struktur tetap dari Star Schema membatasi kueri. Jadi, karena membuat kueri yang paling umum mudah ditulis, ini juga membatasi cara data dapat dianalisis.
GUI Workbench IRI untuk Voracity memiliki seperangkat alat canggih dan lengkap yang menyederhanakan integrasi data, termasuk pembuatan, pemeliharaan, dan perluasan gudang data. Dengan antarmuka yang intuitif dan mudah digunakan ini, Voracity memfasilitasi pembuatan proses ETL (ekstrak, transformasi, muat) end-to-end yang cepat, fleksibel, yang melibatkan struktur data di berbagai platform.
Dalam operasi ETL, data diekstraksi dari sumber yang berbeda, ditransformasikan secara terpisah, dan dimuat ke Data warehouse dan mungkin target lainnya. Membangun proses ETL, berpotensi, salah satu tugas terbesar membangun gudang; itu rumit dan memakan waktu. Pendekatan ETL IRI mendukung proses ini dengan cara yang sangat efisien, dan tidak bergantung pada database, dengan melakukan semua integrasi dan staging data dalam sistem file.
[1] Jika Anda adalah pemburu sintaks, perhatikan bahwa skrip SortCL yang digunakan dalam produk IRI CoSort atau platform IRI Voracity mendukung sintaks dan definisi data yang sama seperti IRI RowGen untuk pembuatan data pengujian, IRI NextForm untuk migrasi data, dan IRI FieldShield untuk penyembunyian data. Semua alat tersebut semuanya didukung di GUI IRI Workbench, dan metadatanya juga dapat dibagikan dan dikelola tim untuk kontrol versi, garis keturunan pekerjaan/data, dan keamanan di cloud.
[2] Untuk menampilkan diagram ER di IRI Workbench:
- Pilih Proyek IRI Baru dan buat Folder Baru
- Pilih folder itu dan sorot semua tabel database yang berlaku di Penjelajah Sumber Data; lalu klik kanan IRI, New ER-Diagram
- File (Schema.QA) akan dibuat
- Klik kanan pada File itu, dan pilih Representasi Baru, Diagram Relasi Entitas Baru.
[3] Elemen diagram ER yang menggambarkan model tersebut meliputi:
- jenis entitas yang ditentukan
- atribut yang ditentukan
- hubungan antara tipe entitas
- gambar keseluruhan, atau diagram konseptual
[4] IRI FACT dan SQL*Loader adalah opsi ekstraksi dan pemuatan massal.