Sebelum membahas masalah kinerja Forwarded Records dan menyelesaikannya, kita perlu meninjau struktur tabel SQL Server.
Ikhtisar Struktur Tabel
Di SQL Server, unit dasar penyimpanan data adalah Halaman 8 KB . Setiap halaman dimulai dengan header 96-byte yang menyimpan informasi sistem tentang halaman tersebut. Kemudian, baris tabel akan disimpan pada halaman data secara serial setelah header. Di akhir halaman, tabel offset baris, yang berisi satu entri untuk setiap baris, akan disimpan berlawanan dengan urutan baris di halaman. Entri offset baris ini menunjukkan seberapa jauh byte pertama dari baris tersebut berada dari awal halaman.
SQL Server memberi kita dua jenis tabel, berdasarkan struktur tabel itu. Berkelompok tabel menyimpan dan mengurutkan data di halaman data berdasarkan nilai kolom atau kolom kunci indeks Clustered yang telah ditentukan sebelumnya. Selain itu, halaman data dalam tabel Tergugus diurutkan dan ditautkan bersama dalam daftar tertaut berdasarkan nilai kunci indeks Tergugus. B-pohon struktur indeks Clustered menyediakan metode akses data cepat berdasarkan nilai kunci indeks Clustered. Jika baris baru dimasukkan atau nilai kunci yang sudah ada diperbarui dalam tabel berkerumun, SQL Server akan menyimpan nilai baru di posisi logis yang benar yang sesuai dengan ukuran baris yang disisipkan tanpa melanggar kriteria pengurutan. Jika nilai yang dimasukkan atau diperbarui lebih besar dari ruang yang tersedia di halaman data, halaman akan dibagi menjadi dua halaman agar sesuai dengan nilai baru.
Jenis tabel kedua adalah Heap tabel, di mana data tidak diurutkan dalam halaman data dalam urutan apa pun dan halaman tidak ditautkan bersama, karena tidak ada indeks Clustered yang ditentukan pada tabel itu, untuk menerapkan kriteria penyortiran apa pun. Melacak halaman yang tidak diurutkan dalam kriteria pengurutan apa pun atau ditautkan bersama di tabel heap bukanlah misi yang mudah. Untuk menyederhanakan proses pelacakan alokasi halaman dalam tabel heap, SQL Server menggunakan Peta Alokasi Indeks (IAM), satu-satunya koneksi logis antara halaman data di tabel heap, dengan menyimpan entri untuk setiap halaman data di tabel atau indeks di tabel IAM. Untuk mengambil data apa pun dari tabel heap, SQL Server Engine memindai IAM untuk menemukan sejauh mana, yang membentuk 8 halaman yang menyimpan data yang diminta.
Masalah Catatan yang Diteruskan
Jika baris baru dimasukkan ke dalam tabel heap, SQL Server Engine akan memindai Ruang Kosong Halaman (PFS) halaman untuk melacak status alokasi dan penggunaan ruang pada setiap halaman data untuk menemukan lokasi pertama yang tersedia di halaman data yang sesuai dengan ukuran baris yang disisipkan. Kemudian, baris akan ditambahkan ke halaman yang dipilih. Jika nilai yang dimasukkan lebih besar dari ruang yang tersedia di halaman data, halaman baru akan ditambahkan ke tabel tersebut untuk dapat menyisipkan nilai baru.
Di sisi lain, jika data yang ada di tabel heap diubah, misalnya, kami memperbarui string panjang variabel dengan ukuran data yang lebih besar, dan ruang saat ini tidak sesuai dengan data baru, data akan dipindahkan ke fisik yang berbeda. lokasi dan Catatan yang Diteruskan akan dimasukkan ke dalam tabel tumpukan di lokasi data asli, untuk menunjuk ke lokasi baru data tersebut dan untuk menyederhanakan lokasi data pelacakan. Lokasi data baru juga berisi penunjuk yang menunjuk ke penunjuk penerusan agar tetap diperbarui jika data dipindahkan dari lokasi baru dan untuk mencegah rantai penunjuk penerusan yang lama atau menghapusnya. Hal ini dapat menyebabkan penghapusan catatan penerusan juga.
Meskipun metode pengalihan Catatan yang Diteruskan mengurangi kebutuhan untuk tabel intensif sumber daya dan operasi pembuatan ulang indeks non-cluster untuk memperbarui alamat data setiap kali lokasi data diubah, metode ini juga menggandakan jumlah pembacaan yang diperlukan untuk mengambil data. SQL Server akan mengunjungi lokasi lama terlebih dahulu, di mana ia akan menemukan Forwarded Record yang mengarahkannya ke lokasi data baru. Kemudian, ia akan membaca data yang diminta, melakukan operasi baca dua kali. Selain itu, masalah Catatan yang Diteruskan menyebabkan perubahan pembacaan data berurutan menjadi pembacaan data acak yang memengaruhi kinerja operasi pengambilan data dari waktu ke waktu secara negatif.
Mari kita buat heapForwardRecordDemo berikut ini tabel menggunakan pernyataan CREATE TABLE T-SQL di bawah ini:
CREATE TABLE ForwardRecordDemo( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Kemudian, isi tabel tersebut dengan data 3K untuk tujuan pengujian, menggunakan pernyataan T-SQL INSERT INTO di bawah ini:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)MASUKKAN 1000INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)GO 1000INSERT INTO ForwardRecordDemo VALUES ('Frank ','1988-07-04',900)GO 1000 Mengidentifikasi Masalah Catatan yang Diteruskan
Informasi tentang jenis tabel dan jumlah halaman yang digunakan saat menyimpan data tabel, serta persentase fragmentasi indeks dan jumlah Catatan yang Diteruskan untuk tabel tertentu dapat dilihat dengan menanyakan sys.dm_db_index_physical_stats fungsi manajemen dinamis sistem dan dengan meneruskan ke DETAILED mode untuk mengembalikan jumlah Catatan Penerusan. Untuk melakukannya, gunakan skrip T-SQL di bawah ini:
<'pre>PILIH OBJECT_NAME(PhysSta.object_id) sebagai DBTableName, PhysSta.index_type_desc, PhysSta.avg_fragmentation_in_percent, PhysSta.forwarded_record_count, PhysSta.page_countFROM sys.dm_physic_db_in'STA. PhysSta.object_id) ='ForwardRecordDemo' DAN forwarded_record_count BUKAN NULLSeperti yang Anda lihat dari hasil kueri, tabel sebelumnya adalah tabel heap yang tidak memiliki indeks Clustered yang dibuat untuk mengurutkan data di halaman dan menautkan halaman satu sama lain. Baris 3K yang disisipkan ke dalam tabel ditetapkan ke 15 halaman data, tanpa catatan yang diteruskan dan persentase fragmentasi nol, seperti yang ditunjukkan pada hasil di bawah ini:

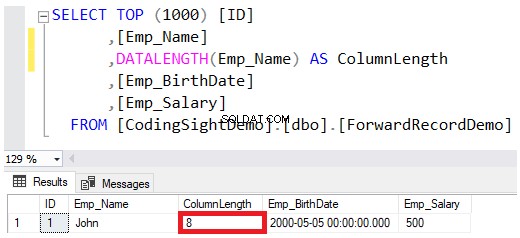
Saat Anda menentukan tipe data kolom sebagai VARCHAR atau NVARCHAR, nilai yang ditentukan dalam definisi tipe data adalah ukuran maksimum yang diizinkan untuk string tersebut, tanpa sepenuhnya mencadangkan jumlah tersebut saat menyimpan nilai ke dalam halaman data. Misalnya, John nama karyawan yang dimasukkan ke dalam tabel itu hanya akan mencadangkan 8 byte dari maksimum 100 byte untuk kolom itu, dengan mempertimbangkan bahwa menyimpan string NVARCHAR akan menggandakan byte yang diperlukan untuk kolom VARCHAR, seperti yang ditunjukkan di DATALENGTH hasil fungsi di bawah ini:
Jika Anda ingin memperbarui nilai kolom Emp_Name untuk memasukkan nama lengkap karyawan John, gunakan pernyataan UPDATE di bawah ini:
PERBARUI ForwardRecordDemo SET Emp_Name='John David Micheal'WHERE Emp_Name='John'
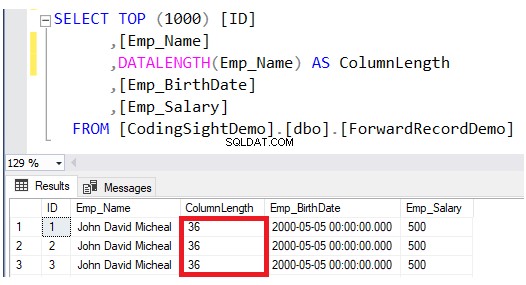
Periksa panjang kolom yang diperbarui menggunakan DATALENGTH fungsi. Anda akan melihat bahwa panjang kolom Emp_Name di baris yang diperbarui telah diperluas sebesar 28 byte per setiap kolom, yaitu sekitar 3,5 halaman data tambahan ke tabel itu, seperti yang ditunjukkan pada hasil di bawah ini:
Kemudian, periksa jumlah Catatan yang Diteruskan setelah operasi pembaruan dengan menanyakan fungsi manajemen dinamis sistem sys.dm_db_index_physical_stats. Untuk melakukannya, gunakan skrip T-SQL di bawah ini:
<'pre>PILIH OBJECT_NAME(PhysSta.object_id) sebagai DBTableName, PhysSta.index_type_desc, PhysSta.avg_fragmentation_in_percent, PhysSta.forwarded_record_count, PhysSta.page_countFROM sys.dm_physic_db_in'STA. PhysSta.object_id) ='ForwardRecordDemo' DAN forwarded_record_count BUKAN NULLSeperti yang Anda lihat, memperbarui kolom Emp_Name pada catatan 1K dengan nilai string yang lebih besar, tanpa menambahkan catatan baru, akan menetapkan 5 tambahan halaman ke tabel itu, bukan 3,5 halaman seperti yang diharapkan sebelumnya. Ini akan terjadi karena menghasilkan 484 meneruskan catatan untuk menunjuk ke lokasi baru dari data yang dipindahkan. Ini dapat menyebabkan tabel menjadi 33% terfragmentasi, seperti yang ditunjukkan dengan jelas di bawah ini:

Sekali lagi, jika Anda berhasil memperbarui nilai kolom Emp_Name untuk memasukkan nama lengkap karyawan Zaid, gunakan pernyataan UPDATE di bawah ini:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq'WHERE Emp_Name='Zaid'
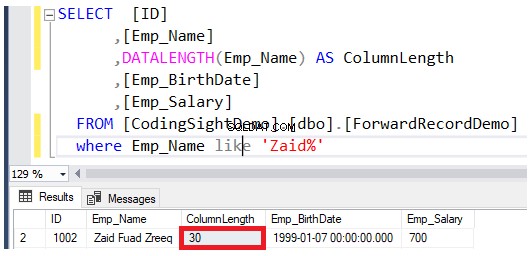
Periksa panjang kolom yang diperbarui menggunakan DATALENGTH fungsi. Anda akan melihat bahwa panjang kolom Emp_Name di baris yang diperbarui diperluas sebesar 22 byte per setiap kolom, yaitu sekitar 2,7 halaman data tambahan ditambahkan ke tabel itu, seperti yang ditunjukkan pada hasil di bawah ini:
Periksa jumlah catatan yang diteruskan setelah melakukan operasi pembaruan. Anda dapat melakukan ini dengan menanyakan fungsi manajemen dinamis sistem sys.dm_db_index_physical_stats menggunakan skrip T-SQL yang sama di bawah ini:
<'pre>PILIH OBJECT_NAME(PhysSta.object_id) sebagai DBTableName, PhysSta.index_type_desc, PhysSta.avg_fragmentation_in_percent, PhysSta.forwarded_record_count, PhysSta.page_countFROM sys.dm_physic_db_in'STA. PhysSta.object_id) ='ForwardRecordDemo' DAN forwarded_record_count BUKAN NULLHasilnya akan menunjukkan kepada Anda bahwa memperbarui kolom Emp_Name pada catatan 1K lainnya dengan nilai string yang lebih besar tanpa menyisipkan baris baru akan menetapkan 4 lain halaman ke tabel itu, bukan 2,7 halaman seperti yang diharapkan. Ini akan terjadi karena menghasilkan 417 additional tambahan meneruskan catatan untuk menunjuk ke lokasi baru dari data yang dipindahkan dan mempertahankan 33% . yang sama persentase fragmentasi, seperti yang ditunjukkan di bawah ini:

Memperbaiki Masalah Catatan yang Diteruskan
Cara paling sederhana untuk memperbaiki masalah Catatan yang Diteruskan adalah dengan memperkirakan panjang maksimum string yang akan disimpan di kolom dan menetapkannya menggunakan panjang tetap tipe data untuk kolom itu daripada menggunakan tipe data panjang variabel. Cara permanen yang optimal untuk memperbaiki masalah Catatan yang Diteruskan adalah dengan menambahkan indeks Tergugus ke meja itu. Dengan cara ini, tabel akan sepenuhnya diubah menjadi tabel Clustered, yang diurutkan berdasarkan nilai kunci indeks Clustered. Ini akan mengontrol urutan data yang ada, data yang baru dimasukkan dan diperbarui yang tidak sesuai dengan ruang yang tersedia saat ini di halaman data, seperti yang dijelaskan sebelumnya dalam pengantar artikel ini.
Jika menambahkan indeks Clustered ke tabel itu bukan merupakan opsi untuk persyaratan tertentu, seperti tabel staging atau tabel ETL, Anda dapat mengatasi masalah Catatan yang Diteruskan untuk sementara dengan memantau Catatan yang Diteruskan dan membangun kembali tabel tumpukan untuk menghapusnya, itu akan juga perbarui semua indeks yang tidak berkerumun di tabel tumpukan itu. Fungsionalitas membangun kembali tabel heap diperkenalkan di SQL Server 2008, dengan menggunakan ALTER TABLE…REBUILD Perintah T-SQL.
Untuk melihat dampak kinerja Catatan yang Diteruskan pada kueri pengambilan data, mari kita jalankan kueri SELECT yang melakukan pencarian berdasarkan nilai kolom Emp_Nameю Namun, sebelum menjalankan kueri, aktifkan statistik TIME dan IO:
SET STATISTICS WAKTU ONSET STATISTICS IO ONSELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Akibatnya, Anda akan melihat bahwa 925 operasi baca logis dilakukan untuk mengambil data yang diminta dalam 84 md seperti yang ditunjukkan di bawah ini:

Untuk membangun kembali tabel heap untuk menghapus semua Catatan yang Diteruskan, gunakan perintah ALTER TABLE…REBUILD:
ALTER TABLE ForwardRecordDemo REBUILD;
Jalankan lagi pernyataan SELECT yang sama:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name seperti 'John%'
Statistik TIME dan IO akan menunjukkan kepada Anda bahwa hanya 21 operasi baca logis dibandingkan dengan 925 operasi baca logis dengan Catatan yang Diteruskan disertakan dilakukan untuk mengambil data yang diminta dalam 79 md :

Untuk memeriksa jumlah record yang diteruskan setelah membangun kembali tabel heap, jalankan fungsi manajemen dinamis sistem sys.dm_db_index_physical_stats, gunakan skrip T-SQL yang sama di bawah ini:
<'pre>PILIH OBJECT_NAME(PhysSta.object_id) sebagai DBTableName, PhysSta.index_type_desc, PhysSta.avg_fragmentation_in_percent, PhysSta.forwarded_record_count, PhysSta.page_countFROM sys.dm_physic_db_in'STA. PhysSta.object_id) ='ForwardRecordDemo' DAN forwarded_record_count BUKAN NULLAnda akan melihat bahwa hanya 21 halaman, dengan 3 . sebelumnya halaman yang digunakan untuk Catatan yang Diteruskan, ditetapkan ke tabel itu untuk menyimpan data, yang serupa dengan hasil perkiraan yang kami dapatkan selama operasi penyisipan dan pembaruan data (15+3.5+2.7). Setelah membangun kembali tabel heap, semua Catatan yang Diteruskan dihapus sekarang. Hasilnya, kami memiliki tabel tanpa fragmentasi:

Masalah Catatan yang Diteruskan adalah masalah kinerja penting yang harus dipertimbangkan oleh administrator basis data saat merencanakan pemeliharaan meja tumpukan. Hasil sebelumnya diambil dari tabel pengujian kami yang hanya berisi catatan 3K. Anda dapat membayangkan jumlah halaman yang akan terbuang sia-sia oleh Forwarded Records dan penurunan kinerja I/O, karena membaca sejumlah besar Forwarded Records saat membaca dari tabel besar!
Referensi:
- Panduan Arsitektur Laman dan Luas
- dm_db_index_physical_stats (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- Mengetahui tentang 'Forwarded Records' dapat membantu mendiagnosis masalah performa yang sulit ditemukan